"探秘藏经阁:Apache Hadoop 3.0中YARN的新变化"
需积分: 5 138 浏览量
更新于2024-01-17
收藏 1.72MB PDF 举报
Apache Hadoop 3.0是分布式计算和存储框架Apache Hadoop的最新版本。其中,YARN(Yet Another Resource Negotiator)是Hadoop的资源管理系统。本文将概述YARN在Apache Hadoop 3.0中的新功能和改进。
YARN是Hadoop的一个重要组件,主要负责集群资源的管理和任务的调度。在Apache Hadoop 3.0中,YARN有多项重要的改进,旨在提升性能、可伸缩性和用户体验。
首先,YARN在Apache Hadoop 3.0中引入了一种新的调度器,称为Capacity Scheduler。这个调度器改进了资源的分配策略,提供了更好的容量管理和任务调度。Capacity Scheduler支持动态队列,可以根据应用程序的需求动态地调整资源分配。
第二个重要的改进是YARN对容器的管理和隔离能力的增强。容器是YARN中最小的资源单位,用于执行任务。在Apache Hadoop 3.0中,YARN引入了基于容器的资源隔离,通过Linux cgroups技术,可以将容器与其他应用程序隔离开来,避免互相影响。这个改进提高了系统的稳定性和安全性。
另外,YARN在Apache Hadoop 3.0中还引入了Flex opportunities,这是一种新的资源调度机制。Flex opportunities可以根据资源的可用性动态地调整任务的执行,从而提供更好的性能和效率。
除了上述改进之外,YARN在Apache Hadoop 3.0中还增强了对长时间运行应用程序的支持。在以前的版本中,长时间运行的应用程序可能会被系统认为是失败的,并被终止。为了解决这个问题,YARN引入了容器保持(Container Reuse)机制,可以在任务完成后保持容器的状态,以便下次启动同样的任务时可以重新使用容器。
此外,YARN在Apache Hadoop 3.0中还改进了任务的调度策略。通过引入多级调度器,YARN可以将不同类型的任务划分为不同的优先级,并根据需要进行动态调整。
最后,值得一提的是,YARN在Apache Hadoop 3.0中实现了内存分配的改进。传统上,YARN使用静态分配的方式来管理内存,这会导致内存的浪费和低效的利用。在Apache Hadoop 3.0中,YARN引入了动态内存分配(Dynamic Resource Configuration),可以根据应用程序的需求动态地调整内存的分配。
综上所述,YARN在Apache Hadoop 3.0中经过多项改进,包括新的调度器、容器管理和隔离、Flex opportunities、容器保持、任务调度策略以及动态内存分配等。这些改进提高了YARN的性能、可伸缩性和用户体验,使其更适用于大规模分布式计算和存储环境。
5
© Hortonworks Inc. 2011 – 2016. All Rights Reserved
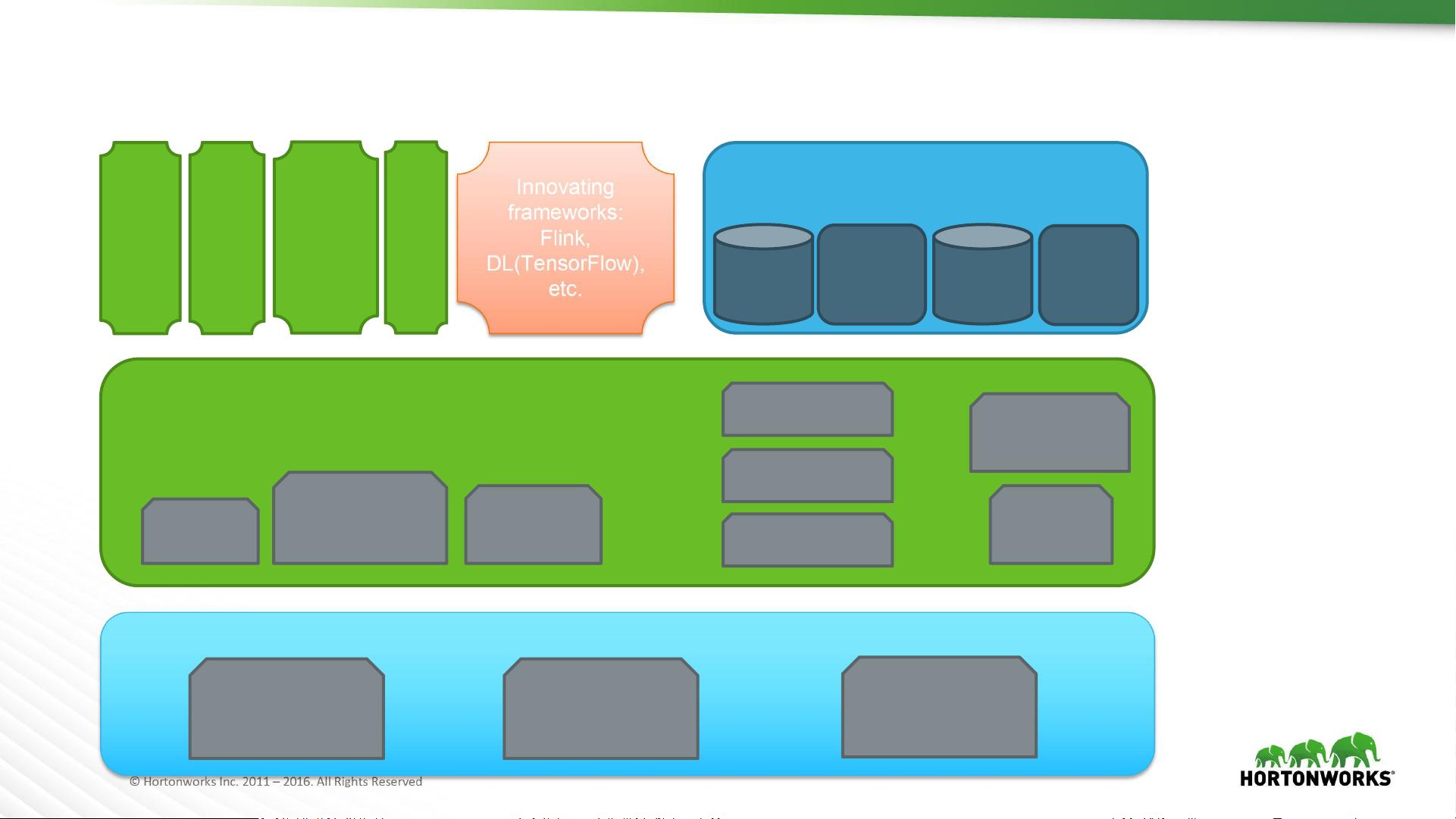
Several important trends in age of Hadoop 3.0 +
YARN and Other Platform Services
Storage
Resource
Management
Security
Service
Discovery
Management
Monitoring
Alerts
IOT Assembly
Kafka
Storm
HBase
Solr
Governance
MR
Tez
Spark
…
Innovating
frameworks:
Flink,
DL(TensorFlow),
etc.
Various Environments
On Premise Private Cloud
Public Cloud
剩余21页未读,继续阅读
2022-08-03 上传
2014-04-28 上传
2023-09-04 上传
2023-07-16 上传
2023-07-16 上传
2023-07-12 上传
2023-05-27 上传
2023-07-25 上传
2023-06-10 上传
2023-04-23 上传

weixin_40191861_zj
- 粉丝: 86
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 常用的dos命令和基本造作
- You Can Program In C++ - A Programmer's Introduction
- Beginning Visual Basic 2005
- 国家级网络精品课程375个
- Hacking Google Maps And Google Earth
- MyEclipse 6 Java 开发中文教程
- 安全第一的C编程规则
- 基于GIS技术的土地储备管理信息系统开发与应用
- 基于WebServices的空间信息资源管理研究
- WinImage打造超强启动盘.doc
- 时态GIS及版本管理原理在森林资源数据更新中的应用研究
- 51完整教材(C及汇编).
- Object-Oriented_JavaScript
- VMWare ESX Server性能優化
- ESX Server
- 想学或正在学C#可以看看
