Hadoop HDFS学习指南:启动与编程操作
需积分: 50 75 浏览量
更新于2024-09-08
收藏 1.15MB DOCX 举报
"大数据技术原理与应用第三章深入解析分布式文件系统HDFS,涵盖启动Hadoop、HDFS编程、Shell命令操作以及Web界面管理。本章重点在于理解HDFS的基本概念,掌握通过不同Shell命令与HDFS交互的方法,并了解如何通过Web界面监控HDFS状态。"
在大数据领域,分布式文件系统HDFS(Hadoop Distributed File System)扮演着核心角色,它为大规模数据存储提供了可扩展性和高容错性。本章主要讨论HDFS的启动、编程接口以及管理和监控方法。
首先,启动Hadoop是使用HDFS的前提。通过执行特定的命令,可以启动Hadoop环境,并通过访问http://localhost:50070的Web界面来检查NameNode和Datanode的状态,同时也可以在这个界面上浏览HDFS中的文件和目录。
在HDFS编程方面,Shell命令是与HDFS进行交互的常用手段。这里有三个相关的命令行工具:hadoopfs、hadoopdfs和hdfsdfs,它们都用于操作HDFS,但适用范围有所不同。hadoopfs适用于所有类型的文件系统,而hadoopdfs和hdfsdfs则专用于HDFS。这些命令包括创建、删除、移动、复制文件及目录等,例如`mkdir`用于创建目录,`ls`用于列出目录内容,`put`用于上传文件,`get`用于下载文件等。在使用这些命令时,需要注意路径是HDFS路径还是Linux本地路径。
此外,HDFS还提供了Web界面,用户可以通过浏览器访问http://localhost:50070来直观地查看HDFS的文件系统树、空间使用情况、节点状态等信息,这对于系统管理员来说非常方便,可以实时监控HDFS的运行状况。
HDFS的设计原则是容错性和高可用性,它将大文件分割成多个块并分布在集群的不同节点上,每个块通常有多个副本,这样即使部分节点故障,数据仍能被恢复。HDFS的这种特性使得它非常适合处理海量数据,特别是在数据挖掘、机器学习等场景下。
本章内容还将涉及HDFS的副本策略、数据读写流程、NameNode和DataNode的角色以及故障恢复机制等关键知识点。理解并熟练掌握HDFS的使用,是成为合格的大数据工程师所必备的基础。通过实际操作和理论学习,读者可以深入理解分布式文件系统的核心原理,为后续的大数据处理和分析打下坚实基础。
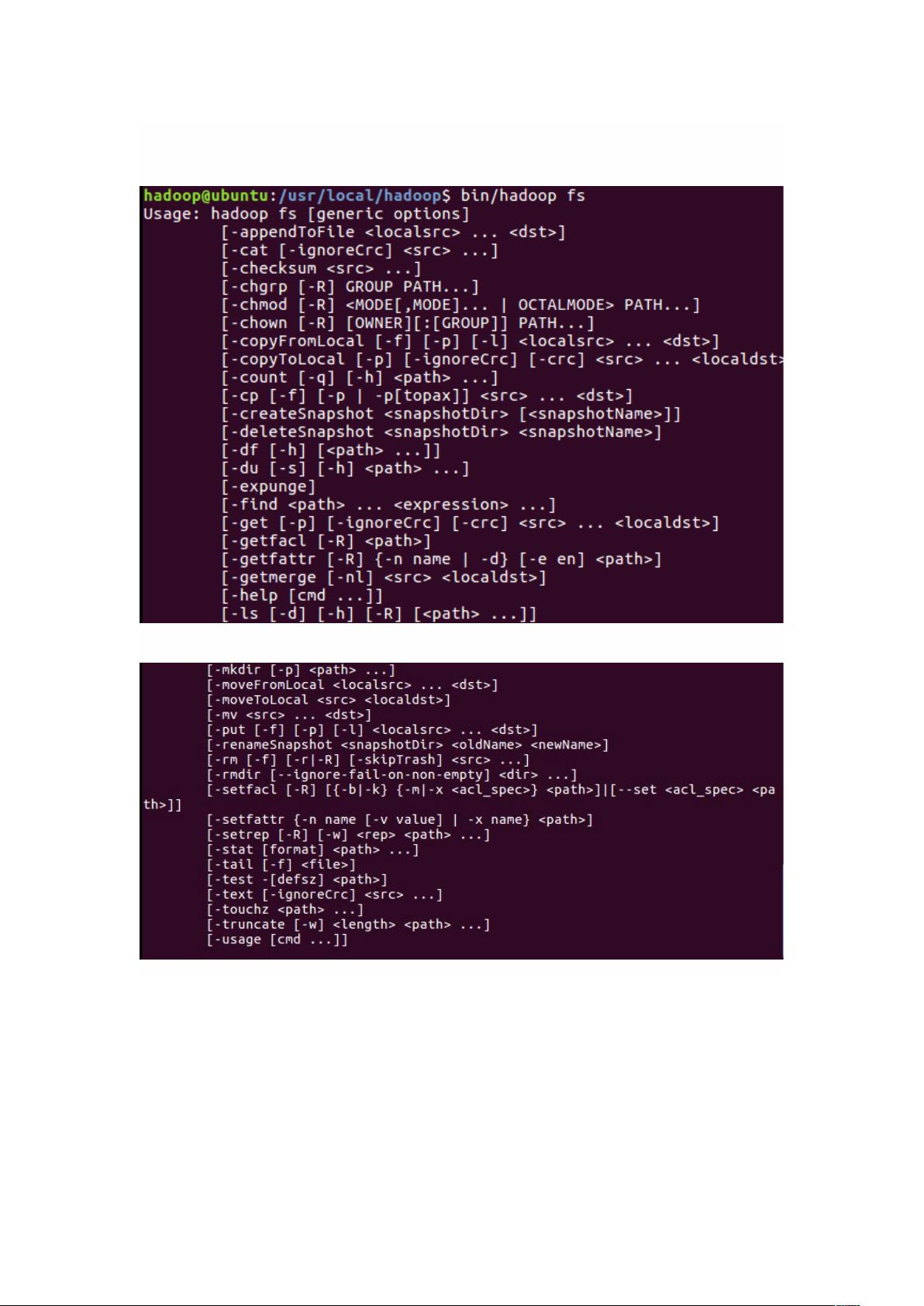
我们可以在终端输入如下命令,查看 fs 总共支持了哪些命令
剩余13页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-01-16 上传
2024-01-16 上传
点击了解资源详情
点击了解资源详情

baidu_32186717ljx
- 粉丝: 2
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- C/C++语言贪吃蛇小游戏
- BeInformed_Backend:与covid-19相关新闻的网站
- python实例-11 根据IP地址查对应的地理信息.zip源码python项目实例源码打包下载
- 【Java毕业设计】【厦门大学毕业设计】蚁群算法实现vrp问题java版本.zip
- shippo:ねこのしっぽ∧_∧
- Graficacion-de-vientos-usando-NCL:NCL库用于从http中提取的grib2文件中提取数据的项目
- 洞洞板简易制作电压、电容表(原理图、程序及算法讲解)-电路方案
- Rainydays
- push-bot:PubSubHubbub 到 XMPP 网关
- XPL compiler:XPL到C转换器-开源
- 【Java毕业设计】java web 毕业设计.zip
- Fruitopia
- iaagofelipe
- 毕业设计论文-源码-ASP人事处网站的完善(设计源码.zip
- TwoLevelExpandableRecyclerView:用于创建两级可扩展回收站视图的库
- 新唐M451 PWM 控制电机弦波(源码)-电路方案
