Apache Kylin:大数据分析引擎的预计算力量
需积分: 10 5 浏览量
更新于2024-07-17
收藏 2.09MB PDF 举报
Apache Kylin 是一个专为大数据分析设计的开源分布式分析引擎,最初由 eBay 开发并贡献给开源社区。它旨在解决现有商业BI工具(如 Tableau 和 Microstrategy)在处理大规模Hadoop数据时的性能瓶颈,如水平扩展困难、无法应对PB级别数据、缺乏Hadoop集成等问题。Kylin的核心理念是预计算,通过在Hadoop之上提供SQL查询接口和多维分析(OLAP)功能,实现实时且高并发的数据分析。
Kylin的基本架构包括以下几个关键组件:
1. **数据源与读取**:
Kylin从Hive中获取源数据,这是大数据仓库中的常见选择,因为它能够处理海量数据。数据处理采用MapReduce技术,这是一种分布式计算模型,用于高效地执行大数据处理任务。
2. **立方体(Cube)构建**:
立方体是Kylin的核心组件,它基于预计算原则,将复杂的聚合和多表连接操作转化为对预先计算好的数据块(Cuboid)的查询。每个Cuboid代表一组维度的特定组合,其中存储了聚合后的度量值。这种设计使得查询性能极佳,可以在亚秒级别处理大型Hive表。
3. **存储与查询接口**:
预计算的结果通常存储在HBase中,这是一种高性能、分布式NoSQL数据库,适合大规模数据存储。Kylin提供了REST API、JDBC和ODBC接口,便于用户通过标准的SQL查询与主流分析工具(如Tableau、Excel等)无缝对接。
4. **REST Server**:
REST Server是Kylin的核心服务,负责处理客户端的请求,如创建、构建、刷新和合并立方体等操作。它提供了RESTful接口,简化了管理和维护过程。
5. **标准SQL支持**:
Kylin支持标准的ANSI SQL,这使得它能够与广泛使用的BI工具进行集成,无需额外的适配工作,提高了工作效率。
Apache Kylin通过其高效的预计算和分布式架构,为大数据时代的分析需求提供了一种强大的解决方案,尤其适用于那些依赖Hadoop进行数据处理的公司和团队。

UI 上 提 供 了 一 个 重 要更 新 ,即 允 许用 户 在 Cube 级 别 进 行 自 定 义 配置 , 以覆 盖
kylin.properties 中的全局配置。如在 cube 中定义 kylin.hbase.region.count.max 可以设置该
cube 在 hbase 中 region 切分的最大数量。
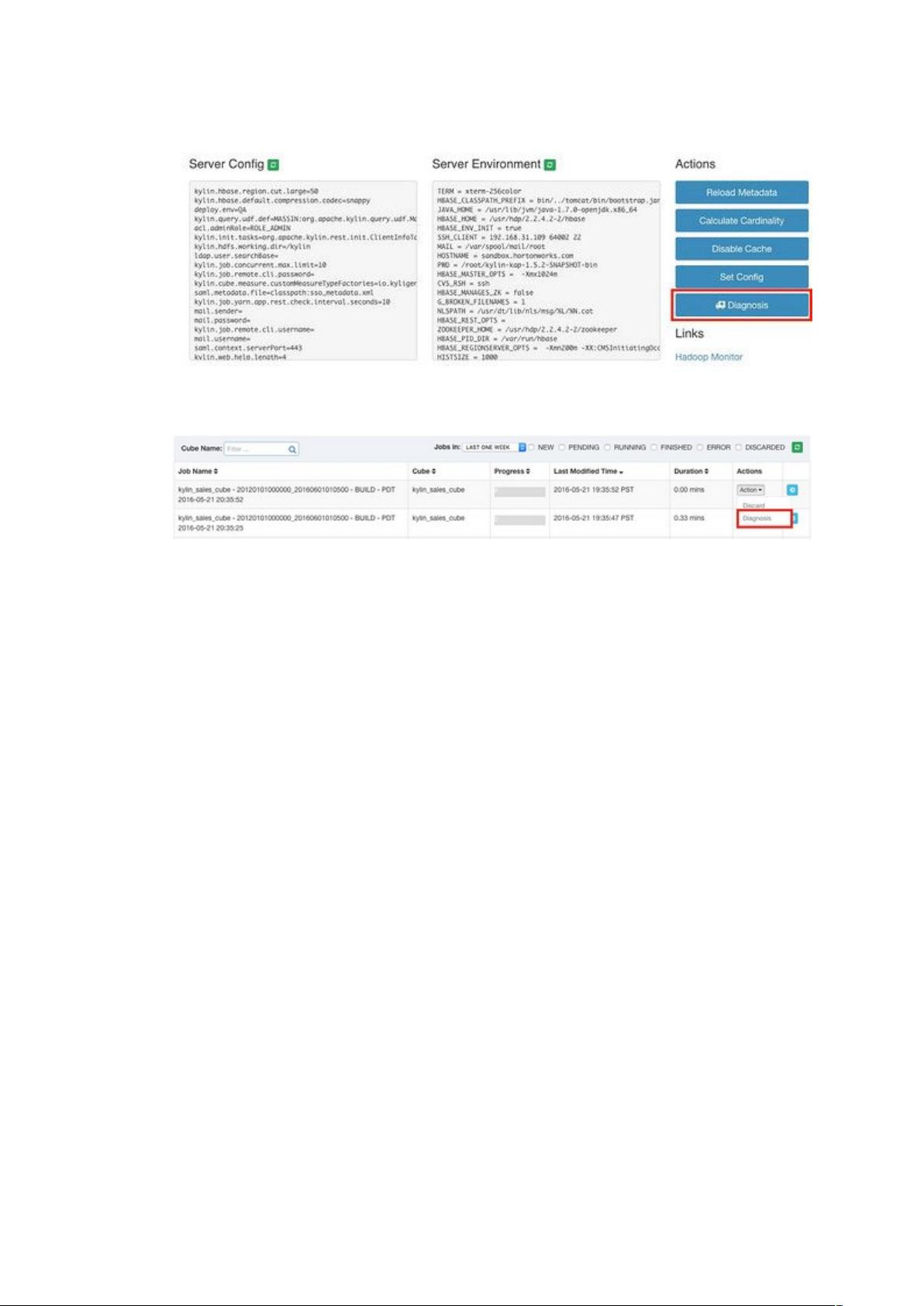
另一个重要的功能是 Diagnosis。用户经常会遇到一些棘手的问题,例如 Cube 构建任务
失败、SQL 查询失败,或 Cube 构建时间过长、SQL 查询时间过长等。但由于运维人员对 Kylin
系统了解不深,很难快速定位到 root cause 所在地。
当用户遇到查询、Cube/Model 管理的问题,单击 System 页面的 Diagnosis 按钮,系统
会自动抓取当前 Project 相关的信息并打包成 zip 文件下载到用户本地。这个包会包含相关的
Metadata、日志、HBase 配置等。当用户需要在 mailing list 求助,也可以附上这个包。
剩余25页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-04-22 上传

zhaiwuyan
- 粉丝: 3
- 资源: 17
 我的内容管理
展开
我的内容管理
展开







最新资源
- AirKiss技术详解:无线传递信息与智能家居连接
- Hibernate主键生成策略详解
- 操作系统实验:位示图法管理磁盘空闲空间
- JSON详解:数据交换的主流格式
- Win7安装Ubuntu双系统详细指南
- FPGA内部结构与工作原理探索
- 信用评分模型解析:WOE、IV与ROC
- 使用LVS+Keepalived构建高可用负载均衡集群
- 微信小程序驱动餐饮与服装业创新转型:便捷管理与低成本优势
- 机器学习入门指南:从基础到进阶
- 解决Win7 IIS配置错误500.22与0x80070032
- SQL-DFS:优化HDFS小文件存储的解决方案
- Hadoop、Hbase、Spark环境部署与主机配置详解
- Kisso:加密会话Cookie实现的单点登录SSO
- OpenCV读取与拼接多幅图像教程
- QT实战:轻松生成与解析JSON数据
