RocksDB详解:高性能Key-Value数据库的存储机制
189 浏览量
更新于2024-08-28
收藏 762KB PDF 举报
"本文介绍了RocksDB,一个高性能的Key-Value数据库,其核心特性包括持久化机制、排序的Key支持范围查询以及高效的读写流程。RocksDB利用memtable、WAL文件和SST文件来管理数据,并通过缓存层优化查询性能。此外,文章提到了memtable的不同实现结构,如跳跃表和哈希结合跳跃表,以及WAL文件的存储方式。SST文件有两种存储结构,一种按数据块存储,另一种按单个K-V存储,均包含索引和过滤器以加速查询。文章还简要讨论了快照机制和文件删除策略。"
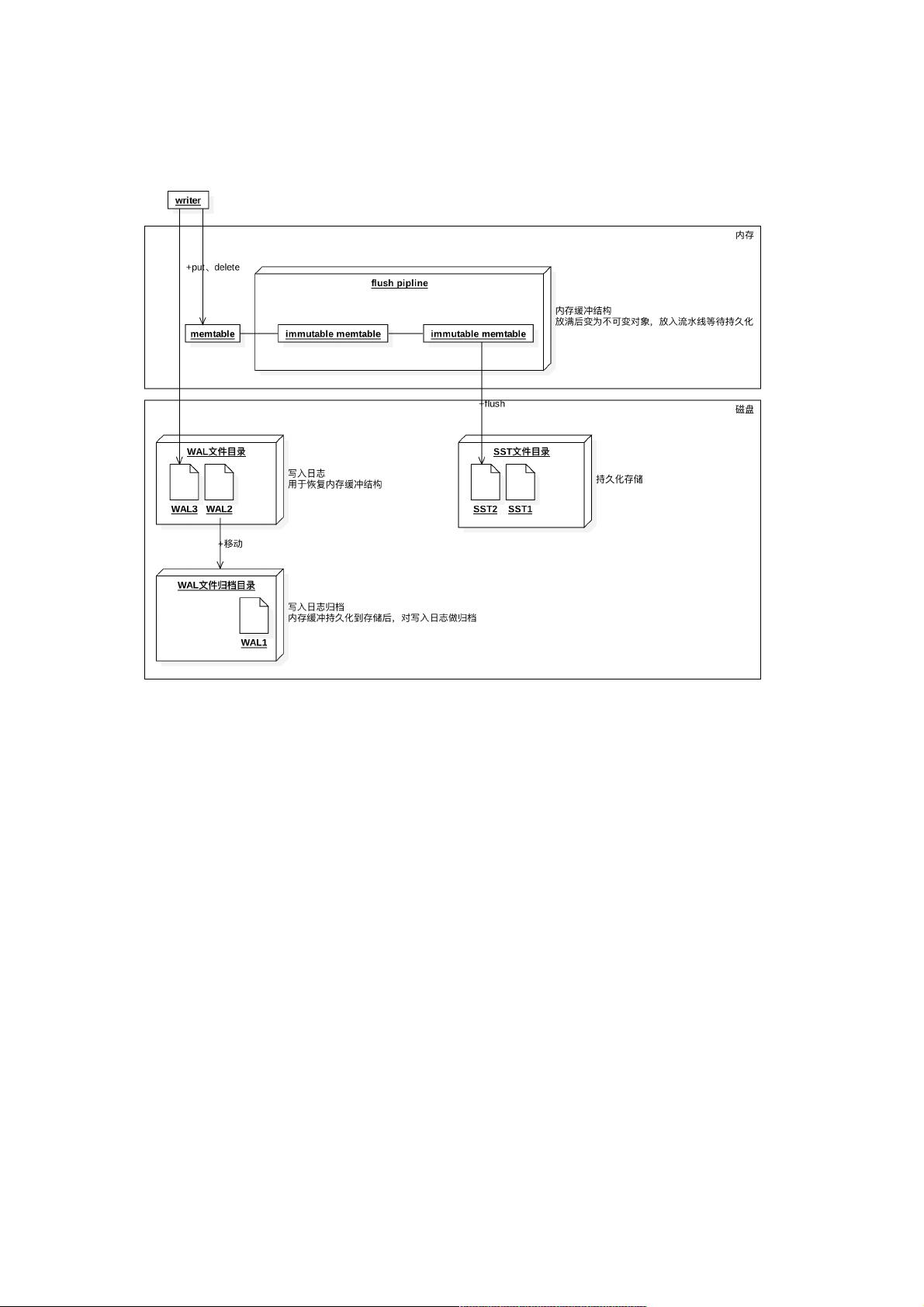
RocksDB是一款被广泛使用的高性能Key-Value数据库,它的设计重点在于提供快速的数据访问和安全的持久化存储。RocksDB的核心组件包括内存中的memtable、Write-Ahead Log (WAL)文件和Sorted String Table (SST)文件。数据首先被写入memtable,当达到一定条件时,数据会被刷入磁盘上的SST文件。WAL文件用于在系统崩溃时恢复未写入SST的memtable数据,确保数据不丢失。
在读取流程中,RocksDB首先查找memtable,然后查找SST文件,这两个构成数据的完整集合。缓存层进一步提升查询速度,采用分片和哈希查询策略,不同缓存有各自的热点数据替换逻辑。查询可以基于当前时间点的视图或快照,快照机制允许在读取过程中安全地删除和合并SST文件,而不影响查询结果。
RocksDB的memtable可以实现为跳跃表或哈希结合跳跃表。跳跃表允许高效范围查询,而哈希结合跳跃表则在单个键查询时提供更快的速度,但牺牲了一定的范围查询性能。
WAL文件按照写入顺序存储键值对,采用固定长度的分组方式,便于读取。SST文件有两种结构:一种按照数据块存储,每个块内键值对有序,块间也有序,文件中包含元数据和索引;另一种结构每个键值对单独存储,索引由哈希和二分查找缓存组成,优化了大前缀下的查询效率。
随着数据的不断写入,RocksDB会生成多个SST文件,通过 compaction 过程进行合并,以减少磁盘空间的使用和提高读取效率。在这个过程中,RocksDB通过高效的索引结构和过滤器技术,确保即使在大量数据下也能快速定位和检索所需信息。
RocksDB以其独特的设计和优化策略,为高性能、低延迟的键值存储需求提供了强大解决方案,广泛应用于大数据处理、实时分析和互联网服务等领域。
看图了解看图了解RocksDB
它是一个高性能的Key-Value数据库。设计了完善的持久化机制,同时保证性能和安全性。能够良好的支持范围查询,因为K-
V记录就是按照Key来排序的。
下图为写入的流程:
可以看到主要的三个组成部分,内存结构memtable,类似事务日志角色的WAL文件,持久化的SST文件。
数据会放到内存结构memtable,一定条件下触发写到到SST文件。写入WAL文件是可选的,用来恢复未写入到磁盘的
memtable。
下图展示了读取的层次:
下载后可阅读完整内容,剩余4页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2013-05-16 上传
2006-03-16 上传

weixin_38691482
- 粉丝: 3
- 资源: 949
 我的内容管理
展开
我的内容管理
展开







最新资源
- BIRT_Viewer_2_2_参数设置详解.pdf
- OpenGL函数简介.pdf
- 初学者,Java转义字符
- 数据结构中图算法设计题
- idea 8.0 常用快捷键
- 使用FLEX 和 Actionscript开发FLASH 游戏(六)-3
- 使用FLEX 和 Actionscript开发FLASH 游戏(五)
- IEEE1588 块结构图中文说明
- 使用FLEX 和 Actionscript开发FLASH 游戏(四)-1
- 使用FLEX 和 Actionscript开发FLASH 游戏(三)-4
- 计算机权限 计算机权限
- DS12887芯片片介绍
- FAT_File_System
- Struts Hibernate Spring推荐的最优组合配置.pdf
- 深入编程内幕 vc++
- 使用FLEX 和 Actionscript开发FLASH 游戏(三)-2
