Hadoop作业优化:微软技术白皮书
需积分: 9 90 浏览量
更新于2024-07-23
收藏 2.16MB PDF 举报
“微软Hadoop优化文档 - Hadoop Job Optimization”
本文档由微软ITSESE企业数据架构团队于2014年5月30日发布,主要关注Hadoop作业优化,提供了解决性能瓶颈的策略和建议,以提高整体Hadoop作业的执行效率。
在“HadoopJobOptimization”中,作者首先对MapReduce的内部工作原理进行了简短的介绍,这对于理解后续的优化策略至关重要。MapReduce是Hadoop的核心组件,通过将大型任务分解为小的并行任务,使得分布式处理成为可能。
第二部分定义了一个通用的性能调优框架,用于指导可重复的优化过程。这个框架帮助识别基于性能指标的资源瓶颈,例如CPU利用率、内存使用、磁盘I/O和网络带宽等。了解这些指标对于定位问题至关重要。
在第三部分,文档详细阐述了各种调优技术,包括但不限于:
1. **Mapper和Reducer数量的调整**:适当增加Mapper和Reducer的数量可以提高并行度,但过多可能导致资源竞争和调度开销。
2. **内存管理优化**:设置合适的堆内存大小,避免溢出错误,同时优化数据序列化和反序列化过程。
3. **数据本地性**:尽量使数据与处理节点位于同一集群,减少数据传输的延迟和带宽消耗。
4. **Shuffle阶段优化**:调整Shuffle阶段的缓冲区大小、合并策略和压缩选项,以降低网络传输负担和内存压力。
5. **作业调度策略**:选择合适的作业调度器(如FIFO、CapacityScheduler或FairScheduler),根据作业优先级和资源需求进行合理调度。
6. **HDFS参数调整**:优化副本数量、块大小、预读取策略等,提高数据读取速度。
此外,文档还提供了针对不同性能问题的技术选择矩阵,帮助读者根据具体问题选择最适合的解决方案。
在结论部分,作者总结了整个调优流程,并强调持续监控和调整的重要性,因为Hadoop环境中的工作负载可能会随时间变化。
附录A专注于Hive的Join操作优化,给出了在Hive中执行Join操作时的性能考虑和最佳实践。附录B则列举了Shuffle阶段的相关调优属性,这有助于更深入地理解Shuffle过程并对其进行优化。
这份文档为Hadoop管理员和开发者提供了一份详实的性能调优指南,涵盖了从基础概念到高级策略的全面内容,是优化Hadoop作业性能的重要参考资料。
Microsoft IT SES Enterprise Data Architect Team 2014-05-30
Hadoop Job Optimization
pipeline, the CPU is waiting for other resources to feed in data before it can proceed to the actual
computation.
Low CPU utilization can also be caused by inappropriate values in the job configuration. For example, if you
set the number of Map or Reduce tasks to a value that is too conservative, the job might under-utilize the
computational capacity of the cluster.
RAM
The amount of RAM available on the task tracker nodes is another potential bottleneck that can have
significant effects. If you have memory-intensive workloads and/or the memory settings are not properly
configured, the Map and Reduce tasks might be initiated but immediately fail. Depending on whether or
not this is a transient issue, Hadoop might eventually succeed in running the task, but the retry operation
itself imposes overhead, and in many cases the job will simply fail to execute. You must be careful to
configure memory usage based on the number of tasks and the physical memory you have on each nodes.
Network Bandwidth
High network utilization occurs when large amounts of data travel among nodes. Most often, this happens
when Reduce tasks pull data from Map tasks in the Shuffle phase, and also when the job outputs the final
results into HDFS.
To ensure that network utilization does not become a bottleneck, you need to be aware of the current
network bandwidth used in a particular job, as well as the maximum network bandwidth available. This
number can be determined by performing a stress test of the Hadoop cluster. By constantly monitoring
MapReduce network utilization, you will be able to figure out if the cluster has sufficient network bandwidth
to move data efficiently.
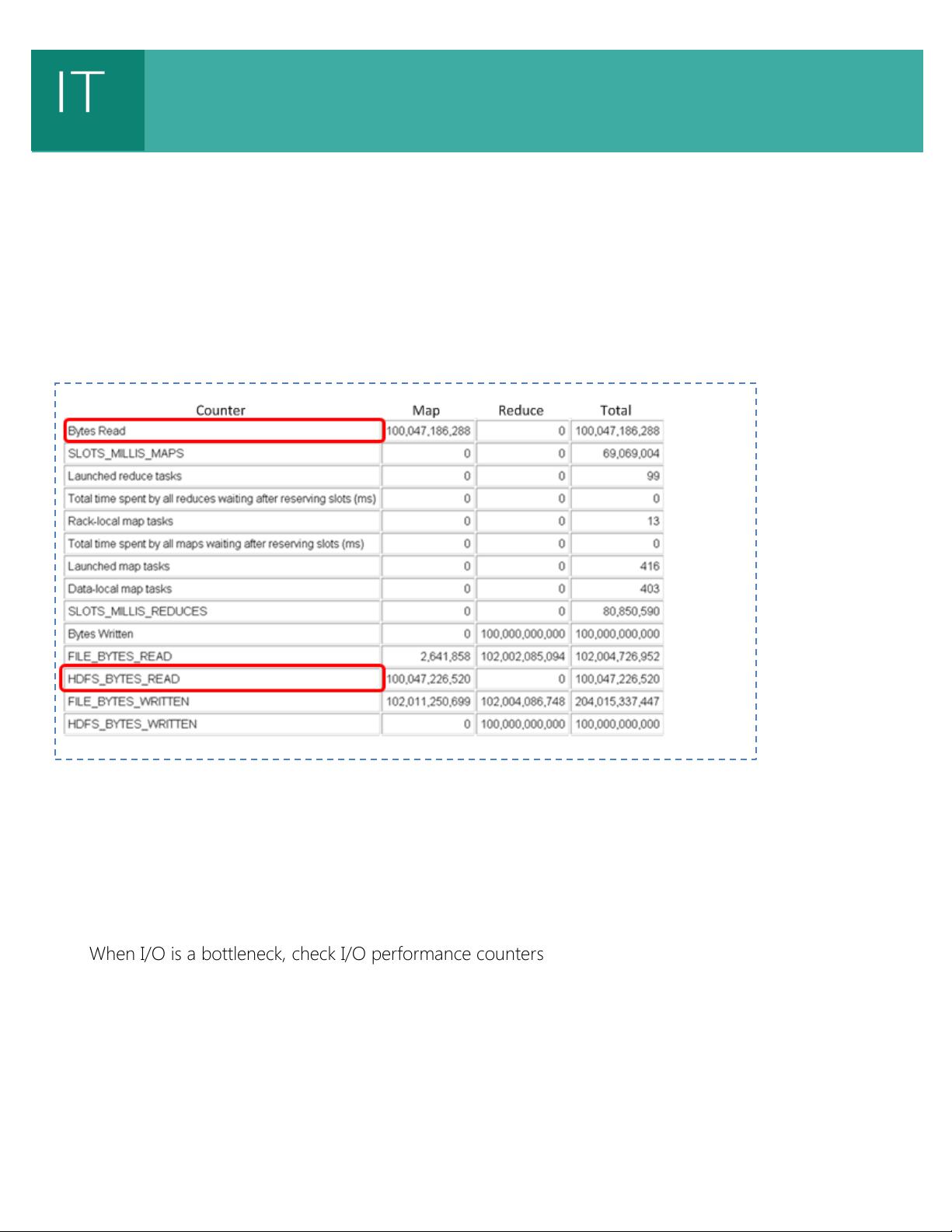
Storage I/O
Storage I/O is probably the most important resource for running a MapReduce job. In our experience, I/O
throughput is also one of the most common bottlenecks. It can decrease MapReduce job performance
across the board, and become a bottleneck at every stage of the execution pipeline.
Storage I/O utilization can be monitored by using Windows performance counters. We recommend that
you learn your cluster’s maximum I/O throughput by running a stress test beforehand, so that you can
determine when your job has encountered a bottleneck. Storage I/O utilization heavily depends on the
volume of input, intermediate data, and final output data. If the bottleneck is in storage I/O, almost all
techniques for reducing data size will help.
剩余58页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-12-04 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

bigdang
- 粉丝: 0
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- Effective C++ 中文版pdf
- 开源时代(讲述开源的东西)
- 高质量c++编程指南
- Emacs下用GDB调试
- SVPWM的等效算法及SVPWM与SPWM的本质联系
- 采用PFC和PWM组合控制器FAN4803设计的直流
- hibernate3 reference
- 一个RSA算法的c++语言实现程序
- ruby on rails 与 uml设计与应用
- 机器视觉--Stefan_Florczyk
- 一个单纯形法的c++程序实现
- IBM 电子商务 电子商务随需应变与科技泛滥
- Ubuntu的最常用配置
- 机器人视觉--JohnWiley经典书籍
- Direct3D9初级教程,书籍,pdf,入门教程
- 词法分析工具 lex帮助大全
