Spark计算性能优势与MapReduce对比分析
84 浏览量
更新于2024-08-29
收藏 406KB PDF 举报
"Spark是一个高性能的分布式计算框架,与Hadoop MapReduce相比,其计算速度更快,可提供高达10到100倍的提升。Spark通过DAG任务调度优化了计算过程,允许数据在内存中多次使用,减少了磁盘I/O。Spark支持多种计算模式,包括批处理、交互查询、流处理和机器学习等,实现了'One stack to rule them all'的设计理念。"
Spark架构的核心组件包括以下几个方面:
1. **Driver Program**:驱动程序是Spark应用的起点,它负责构建DAG(有向无环图)来表示任务的执行计划。Driver运行在用户的代码中,创建SparkContext实例并与集群管理器通信,例如YARN或Standalone。
2. **SparkContext**:SparkContext是Spark应用程序的入口点,它连接到Spark集群并初始化所有组件。SparkContext负责与集群管理器通信,创建作业并分配资源。
3. **Cluster Manager**:Spark可以运行在多种集群管理器上,如YARN、Mesos或Standalone。它们负责分配集群资源给Spark应用,监控任务执行,并在节点故障时进行恢复。
4. **Executor**:Executor是在工作节点(Worker Node)上启动的进程,它们负责执行实际的任务。每个Executor在内存中维护一个BlockManager,用于存储数据块。Executor可以在多个任务之间共享内存,减少了磁盘I/O。
5. **RDD(Resilient Distributed Dataset)**:RDD是Spark的基本数据抽象,它是不可变的、分区的数据集。RDD可以被转换和行动,转换操作创建新的RDD,而行动操作触发计算并返回结果到Driver。
6. **DAG Scheduler**:DAGScheduler将用户定义的操作转换成Stage(由Task组成),Stage尽可能地减少磁盘I/O。如果Stage失败,DAGScheduler会重新安排任务。
7. **Task Scheduler**:在每个Executor中,TaskScheduler负责将任务分发到各个工作线程。它根据数据的位置选择最佳的Executor,以减少数据传输。
8. **Storage System Integration**:Spark可以与多种存储系统集成,如HDFS、Cassandra、Amazon S3等,用于读写数据。
9. **Shuffle**:在Spark的计算过程中,Shuffle操作涉及重新分区数据,这可能导致数据在网络间传输。Spark使用内存缓存和溢写磁盘的策略来管理Shuffle数据。
Spark对比MapReduce的优势在于其内存计算能力。在MapReduce中,每次迭代都需要从磁盘读取数据,而Spark可以将数据存储在内存中,减少磁盘I/O,提高效率。此外,Spark的弹性数据集(RDD)允许用户创建高效的转换链,使得计算更高效。
Spark提供了一个全面的计算框架,不仅限于批处理,还包括实时处理、机器学习和图计算,使得大数据处理更加灵活和快速。这种灵活性和性能使其成为大数据分析领域的重要工具。
Spark的架构概述(章节一)的架构概述(章节一)
Spark的架构概述(章节一)的架构概述(章节一)
背景介绍背景介绍
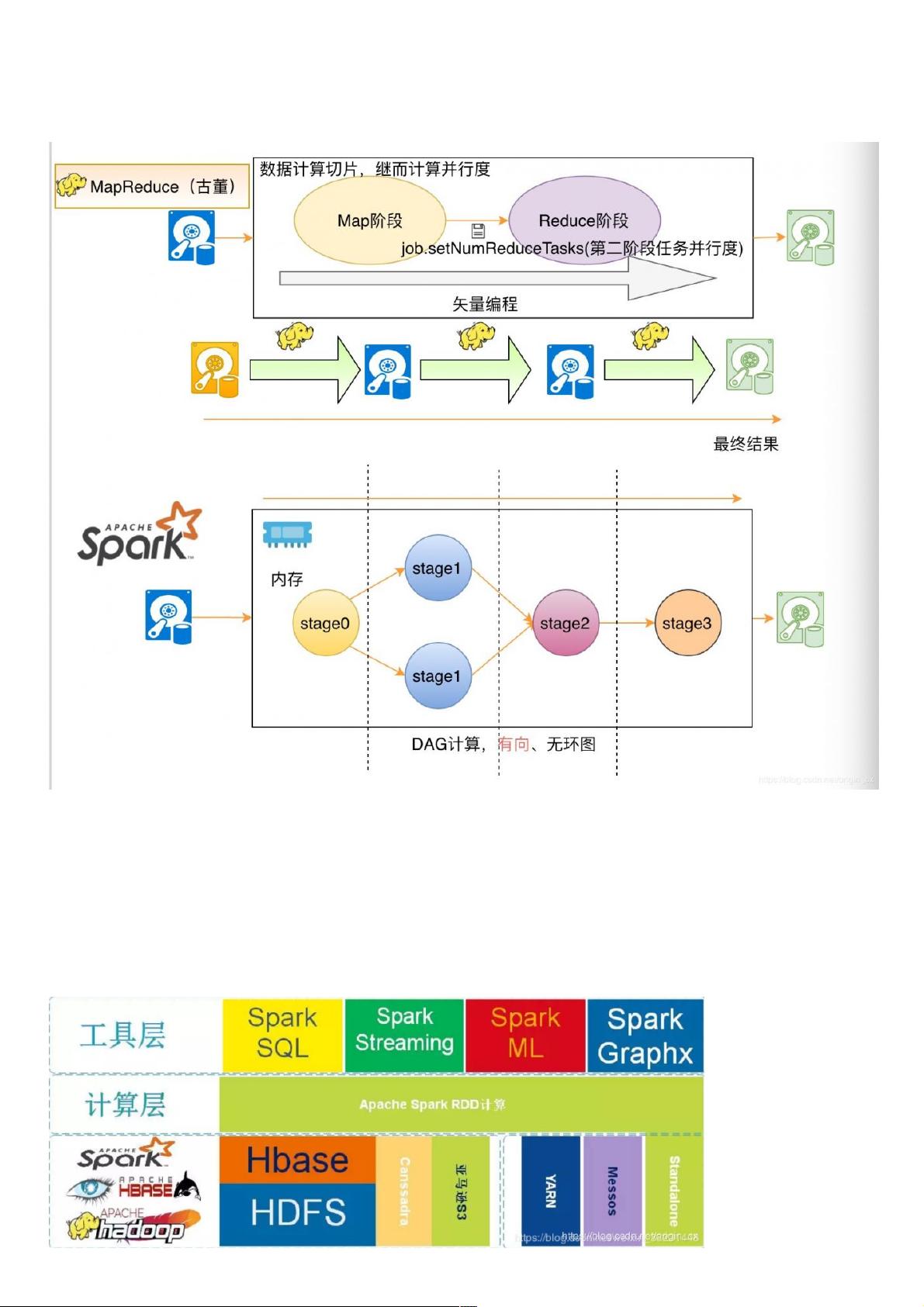
Spark是一个快如闪电的统一分析引擎(计算框架)用于大规模数据集的处理。Spark在做数据的批处理计算,计算性能大约是Hadoop MapReduce的10~100倍,因为Spark使用比较
先进的基于DAG 任务调度(有向无环计算),可以将一个任务拆分成若干个阶段,然后将这些阶段分批次交给集群计算节点处理。
mapreduce计算分为两步,map阶段和reduce阶段,如果两步处理不了结果,则需要再次进行mapreduce计算,反复从磁盘上读写数据,从而降低效率。而spark是基于内存的计算,
每次计算分为若干个阶段,从磁盘中读取一次数据后,直接在内存中完成计算,最后将结果存入磁盘中。
MapReduce VS Spark
MapReduce作为第代数据处理框架,在设计初期只是为了满基于海量数据级的海量数据计算的迫切需求。2006年剥离Nutch(Java搜索引擎)程,主要解决的是早期们对数据的
初级认知所临的问题。
随着时间的推移,们开始探索使Map Reduce计算框架完成些复杂的阶算法,往往这些算法通常不能通过1次性的Map Reduce迭代计算完成。由于Map Reduce计算模型总是把结
果存储到磁盘中,每次迭代都需要将数据磁盘加载到内存,这就为后续的迭代带来了更多延。
Spark发展如此之快是因为Spark在计算层明显优于Hadoop的Map Reduce这磁盘迭代计算,因为Spark可以使内存对数据做计算,且计算的中间结果也可以缓存在内存中,这就为
后续的迭代计算节省了时间,幅度的提升了针对于海量数据的计算效率。
不仅如此Spark在设计理念中也提出了 One stack ruled them all 战略,并且提供了基于Spark批处理上的计算服务分例如:实现基于Spark的交互查询、近实时流处理、机器学习、
Grahx 图形关系存储等。
下载后可阅读完整内容,剩余5页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2019-04-16 上传
2017-12-04 上传
2022-11-17 上传
2015-11-03 上传
2021-10-14 上传
2021-10-14 上传

weixin_38682026
- 粉丝: 1
- 资源: 881
 我的内容管理
展开
我的内容管理
展开







最新资源
- Apress Beginning PL/SQL From Novice to Professional Aug 2007
- ARM教程全集_是你进入ARM好帮手
- Python 中文手册
- DFD introduction
- STM32F10x参考手册
- 2006年下半年软件设计师试卷
- GDB不完全手册.doc
- Makefile详细操作指南.pdf
- gdb中文操作手册-debug
- 数据库第四版答案王珊主编
- stc12c4051ad
- QC API 编程实践,有点技术含量的好东东!
- 数据结构的链式基数排序
- div+css网页设计
- ubuntu8.04速成手册1.0pdf
- 基于FPGA的快速浮点除法器IP核的实现
