Java SDK 7:HashMap深度解析与关键点总结
169 浏览量
更新于2024-09-02
收藏 93KB PDF 举报
HashMap是Java编程语言中常用的集合类之一,它在JDK 1.7版本中的实现具有很多重要的特性。HashMap基于散列(哈希)原理,它将键(key)通过哈希函数转换为数组索引,然后将键值对存储在这个索引对应的链表中。下面我们将深入探讨JDK 7中HashMap的一些关键知识点。
1. **初始容量与最大容量**:
HashMap的默认初始容量是16,这意味着当创建一个HashMap实例时,它会初始化一个大小为16的Entry数组。最大容量是2的30次方(即1 << 30),这是为了防止内存溢出。如果用户尝试设置一个更大的容量,HashMap会使用这个最大值。
2. **负载因子**:
负载因子(load factor)是HashMap的重要参数,默认值为0.75f。当HashMap中的元素数量达到容量(capacity)乘以负载因子时,HashMap会进行扩容操作,以保持性能。
3. **阈值(threshold)**:
阈值是HashMap的实际容量限制,等于容量和负载因子的乘积。当HashMap中的元素数量超过这个阈值时,会触发扩容操作。
4. **数据存储结构**:
HashMap内部使用了一个名为`table`的Entry数组来存储键值对。每个Entry对象包含了键、值以及指向下一个Entry的引用,形成了一个链表结构。这样处理是因为哈希冲突可能导致多个键映射到同一个数组索引上。
5. **哈希函数**:
在JDK 7中,HashMap使用`hash(key)`方法计算键的哈希值,这个值用于确定键值对在数组中的位置。对于String类型的键,JDK 7实现了特殊的哈希算法,称为“alternative hashing”,但这个特性在JDK 8中已被移除。
6. **put方法**:
当调用`put()`方法时,首先检查键是否为空,如果为空,则调用`putForNullKey()`。否则,通过哈希函数计算键的哈希值,然后根据哈希值找到对应数组索引。如果该位置的链表已有元素,那么会遍历链表,根据键的equals()方法查找是否存在相同的键,若存在则更新对应的值,否则在链表末尾添加新的Entry。
7. **扩容机制**:
扩容时,HashMap会创建一个新的容量为原容量2倍的数组,并将旧数组中的所有元素重新哈希到新数组中。这个过程可能需要多次比较和插入,因此在设计程序时,应合理预估HashMap的大小以避免频繁扩容,提高效率。
8. **并发问题**:
JDK 7的HashMap不是线程安全的,如果在多线程环境下同时修改HashMap,可能会导致数据不一致。如果需要线程安全的哈希映射,可以使用ConcurrentHashMap。
9. **迭代器与快速失败**:
HashMap的迭代器依赖于内部结构的不变性,如果在迭代过程中修改HashMap(除了通过迭代器自身的remove()方法),迭代器将抛出`ConcurrentModificationException`,这就是所谓的“快速失败”行为。
以上就是JDK 7中HashMap的一些核心知识点,理解这些概念对于优化代码性能和避免潜在问题至关重要。在实际编程中,根据具体需求选择合适的容器类型和配置参数,可以大大提高程序的运行效率。
jdk7 中中HashMap的知识点总结的知识点总结
HashMap的原理是老生常谈了,不作仔细解说。一句话概括为HashMap是一个散列表,它存储的内容是键值对
(key-value)映射。这篇文章主要总结了关于jdk7 中HashMap的知识点,需要的朋友可以参考借鉴,一起来看看
吧。
HashMap中的几个重要变量中的几个重要变量
默认初始容量,必须是2的n次方
static final int DEFAULT_INITIAL_CAPACITY = 16;
最大容量,当通过构造方法传入的容量比它还大时,就用这个最大容量,必须是2的n次方
static final int MAXIMUM_CAPACITY = 1 << 30;
默认负载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
用来存储键值对,可以看到键值对都是存储在Entry中的
transient Entry<K,V>[] table;
//capacity * load factor,超过这个数就会进行再哈希
int threshold;
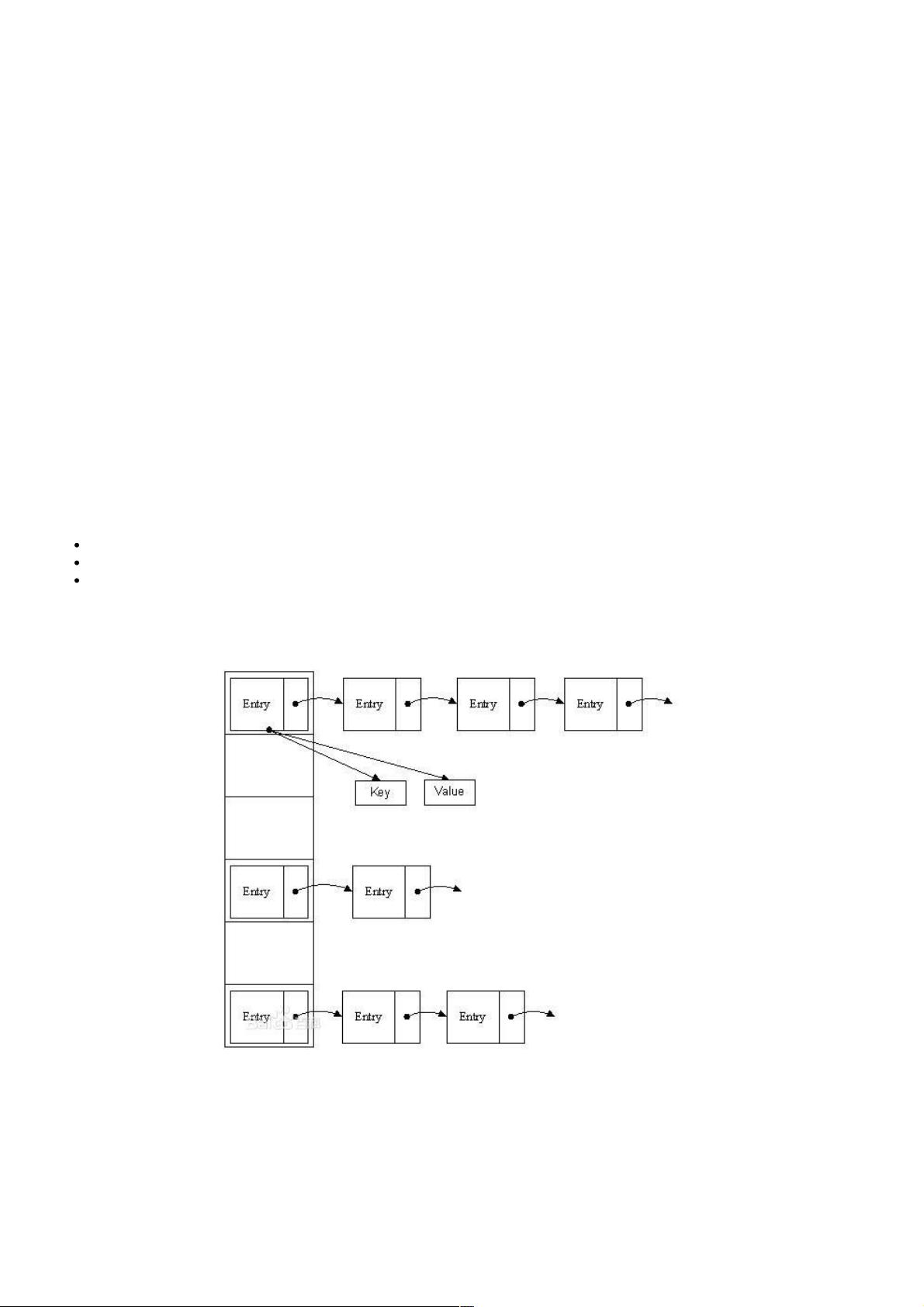
HashMap中的元素是用名为table的Entry数组来保存的,默认大小是16
capacity:数组的容量
load_factor:负载因子
threshold:实际能承载的容量,等于上面两个相乘,当size大于threshold时,就会进行rehash
jdk7中在面对key为String的时候采用了区别对待,会有alternative hashing,但是这个在jdk8中已经被删除了
存储结构存储结构
Entry是一个链表结构,不仅包含key和value,还有可以指向下一个的next
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
下载后可阅读完整内容,剩余3页未读,立即下载
2023-02-28 上传
2022-07-22 上传
2018-12-12 上传
2023-06-07 上传
2023-03-25 上传
2023-09-10 上传
2023-07-13 上传
2023-12-04 上传
2023-06-09 上传









