优先队列与二项堆算法概述
版权申诉
78 浏览量
更新于2024-08-28
收藏 1.81MB PDF 举报
"该资源是一份关于算法设计的讲义,特别关注了优先队列(Priority Queues)的数据结构,包括二项堆(Binary Heaps)、d-ary 堆、二项堆(Binomial Heaps)和斐波那契堆(Fibonacci Heaps)。这些数据结构广泛应用于各种计算问题,如A*搜索、堆排序、在线中位数计算、哈夫曼编码、普里姆的最小生成树算法、离散事件驱动模拟、网络带宽管理以及迪杰斯特拉的最短路径算法等。"
在计算机科学中,优先队列是一种数据结构,它允许我们以最小化或最大化某种关键字(键)的方式存储元素。在这个文档中,我们主要探讨了四种不同的优先队列实现方式:
1. **二项堆(Binary Heaps)**:二项堆是最基础的优先队列实现,由完全二叉树构成,满足堆属性(每个节点的键值不小于其子节点的键值,对于最小堆而言)。二项堆支持基本操作如插入、删除最小元素和降低元素的键值。
2. **d-ary 堆(d-ary Heaps)**:d-ary 堆是二项堆的扩展,其中每个节点最多有d个子节点。二项堆是二元堆(d=2)的特殊情况。d-ary 堆可以提供比二项堆更好的性能,但实现复杂度也相应增加。
3. **二项堆(Binomial Heaps)**:二项堆是由多个二项树组成的集合,每个二项树的节点数对应于2的幂次。这种结构在合并两个堆和删除最小元素时具有良好的时间复杂度,特别适用于优先队列的操作。
4. **斐波那契堆(Fibonacci Heaps)**:斐波那契堆是更复杂的数据结构,用于优化优先队列操作的时间复杂度。它们通过连接树节点来实现,具有压缩路径和辅助指针的特性,使得插入、删除最小元素和降低键值的操作更为高效。
优先队列的常见应用包括但不限于:
- **A* 搜索**:在图中寻找从起点到终点的最短路径时,优先队列用于存储待处理的节点,并根据启发式函数的评估结果优先处理可能性最大的节点。
- **堆排序**:堆排序是一种基于优先队列概念的排序算法,通过构建最大堆或最小堆来实现原地排序。
- **在线中位数**:当新的数值不断到来时,优先队列可以帮助我们快速找到当前序列的中位数。
- **哈夫曼编码**:在数据压缩中,优先队列用于构造最优的前缀编码,最小化编码长度。
- **普里姆的最小生成树算法**:在加权无向图中寻找最小生成树时,优先队列用于选择具有最小边权的边。
- **离散事件驱动模拟**:在模拟系统中,优先队列用来安排未来的事件,根据事件发生的时间顺序执行。
- **网络带宽管理**:在多任务环境中,优先队列可以确保高优先级的流量得到优先处理。
- **迪杰斯特拉的最短路径算法**:类似A*搜索,用于寻找加权图中两点之间的最短路径。
这些数据结构和算法在解决实际问题时具有重要作用,它们通过优化操作效率来提高系统的整体性能。理解并掌握这些概念是成为熟练的算法设计师的关键步骤。
Implicit binary heap
Array representation. Indices start at 1.
・
Take nodes in level order.
・
Parent of node at k is at ⎣k / 2⎦.
・
Children of node at k are at 2k and 2k + 1.
9
8
18
11
25
12
21
17
19
10
6
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
6
10
8
12
18
11
25
21
17
19
1
2 3
4 5
98 10
6 7
Binary heap demo
10
heap ordered
8
18
11
25
12
21
17
19
10
6
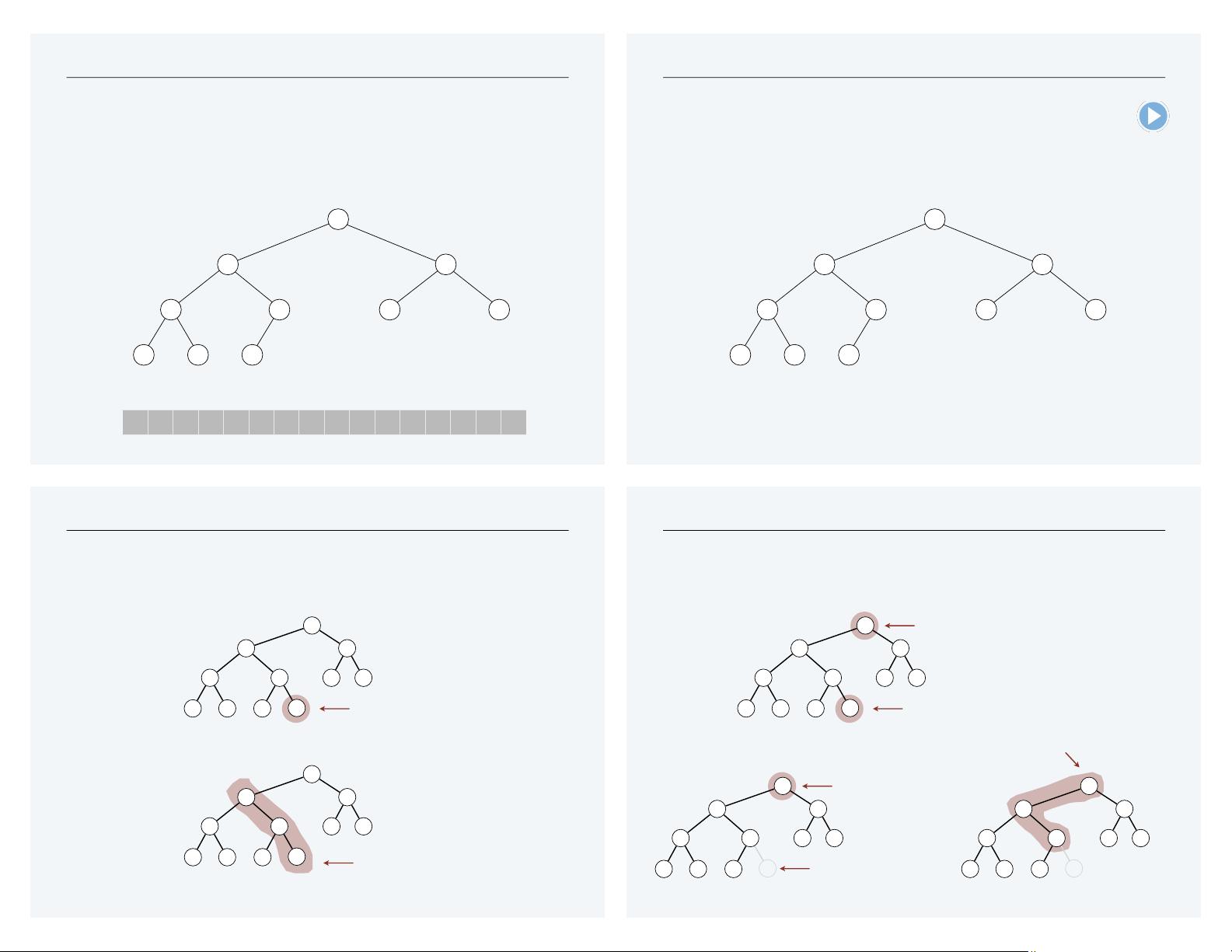
Binary heap: insert
Insert. Add element in new node at end; repeatedly exchange new element
with element in its parent until heap order is restored.
11
8
18
11
25
12
21
17
19
10
6
7
8
10
11
25
12
21
17
19
7
6
18
add key to heap
(violates heap order)
swim up
exchange
with root
element to
remove
Binary heap: extract the minimum
Extract min. Exchange element in root node with last node; repeatedly
exchange element in root with its smaller child until heap order is restored.
12
8
10
11
25
12
21
17
19
7
6
18
8
10
11
25
12
21
17
19
7
18
6
remove
from heap
violates
heap order
8
18
11
25
12
21
17
19
10
7
6
sink down
剩余13页未读,继续阅读
2020-05-27 上传
2021-11-27 上传
2018-04-17 上传
2023-03-20 上传
2023-03-31 上传
2023-03-31 上传
2023-05-25 上传
2023-05-25 上传

码上富贵
- 粉丝: 1w+
- 资源: 177
 我的内容管理
展开
我的内容管理
展开







最新资源
- StarModAPI: StarMade 模组开发的Java API工具包
- PHP疫情上报管理系统开发与数据库实现详解
- 中秋节特献:明月祝福Flash动画素材
- Java GUI界面RPi-kee_Pilot:RPi-kee专用控制工具
- 电脑端APK信息提取工具APK Messenger功能介绍
- 探索矩阵连乘算法在C++中的应用
- Airflow教程:入门到工作流程创建
- MIP在Matlab中实现黑白图像处理的开源解决方案
- 图像切割感知分组框架:Matlab中的PG-framework实现
- 计算机科学中的经典算法与应用场景解析
- MiniZinc 编译器:高效解决离散优化问题
- MATLAB工具用于测量静态接触角的开源代码解析
- Python网络服务器项目合作指南
- 使用Matlab实现基础水族馆鱼类跟踪的代码解析
- vagga:基于Rust的用户空间容器化开发工具
- PPAP: 多语言支持的PHP邮政地址解析器项目
