支持向量机主动学习在医学文献分类中的应用优化
需积分: 10 80 浏览量
更新于2024-07-19
收藏 302KB PDF 举报
支持向量机(Support Vector Machine, SVM)是一种强大的机器学习算法,在许多现实世界的问题中取得了显著的成功,尤其在分类任务中。本文主要关注的是将SVM应用于文本分类,并探讨了在文献检索中的一种特殊场景,即当搜索者可能使用医学科学中的缩写术语而非完整词汇时,如何有效地处理这种情况。
研究背景是由于医疗领域的文献常常包含大量的专业术语和缩写,这可能导致在在线系统搜索时的误匹配或信息遗漏。因此,作者们研究了MEDLINE Medical Subject Headings (MeSH) 不同界面在将这些缩写映射到MeSH词汇表中的表现,目的是评估如何改进搜索的准确性和效率。
文章的标题"Support Vector Machine Active Learning with Application to Text Classification"指出,作者Simon Tong和Daphne Koller针对这一问题提出了一个创新的主动学习算法。传统的SVM方法依赖于预先随机选择的训练集进行分类,但在很多情况下,学习者可以访问一个未标记的数据池,通过主动选择部分样本请求其标签,从而提高模型性能。这就是所谓的池式主动学习策略。
作者们引入的新算法特别考虑了如何在支持向量机的框架下设计有效的主动学习策略。他们利用“版本空间”概念,这是一种理论工具,用于理解模型在不断获取新数据后的变化过程,帮助确定最有价值的样本来询问标签。通过这种方式,他们的算法旨在最小化标注成本,同时最大化模型在有限的标签信息下的泛化能力。
实验结果显示,与传统的被动学习方法相比,该主动学习SVM算法在文本分类任务中表现出更好的性能,能够更有效地利用有限的标注资源,从而提升文献分类的精度。这对于那些依赖缩写检索的领域,如医学文献搜索,具有实际的应用价值。
总结来说,这篇论文不仅介绍了支持向量机在文本分类中的核心原理,还提出了一个适应性更强、更智能的主动学习策略,使得在处理医学文献中的缩写术语时,能更有效地提高信息检索的准确性。这对于改善在线信息检索系统的用户体验和信息发现效率具有重要意义。
SVM Active Learning with Applications to Text Classification
(a) (b)
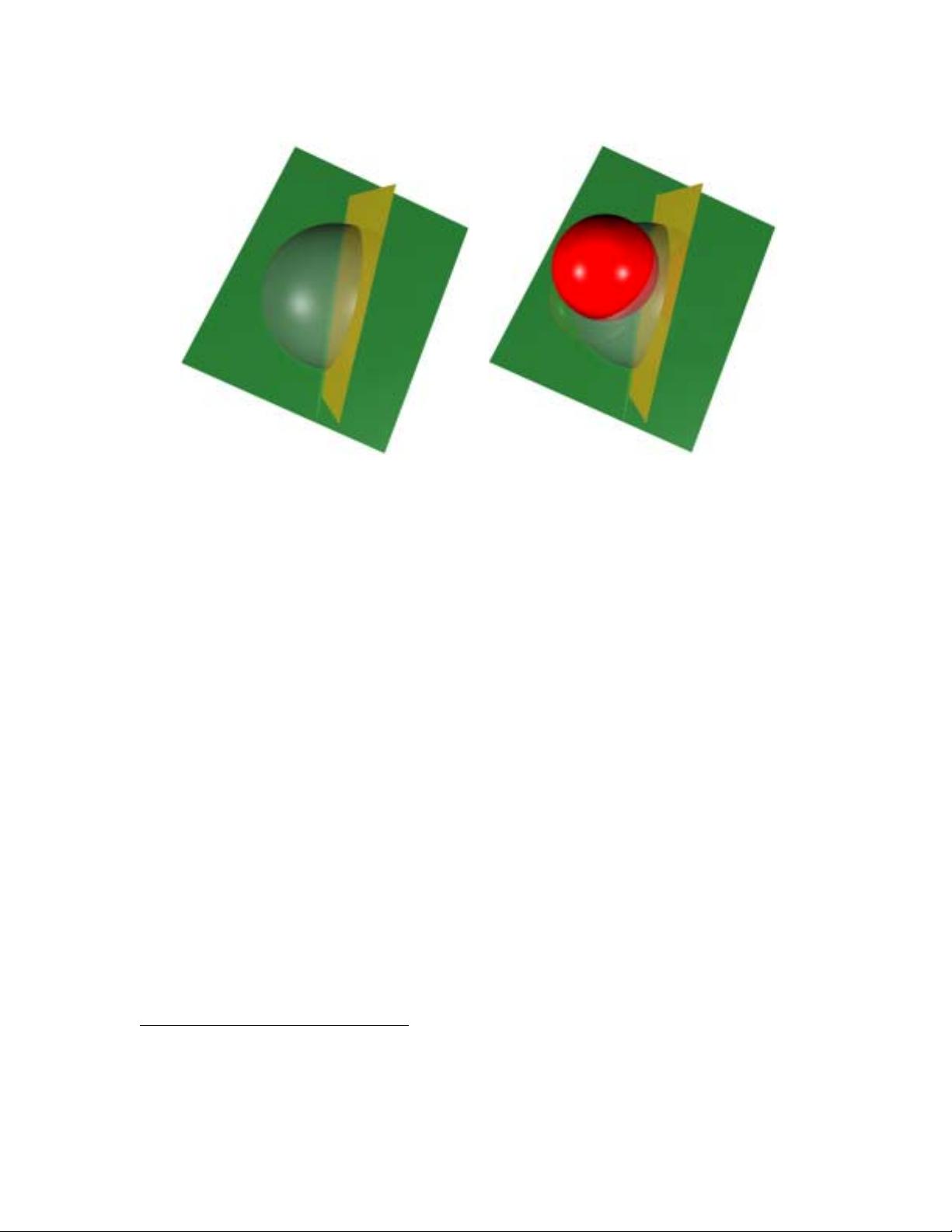
Figure 2: (a) Version space duality. The surface of the hypersphere represents unit weight
vectors. Each of the two hyperplanes corresponds to a labeled training instance.
Each hyperplane restricts the area on the hypersphere in which consistent hy-
potheses can lie. Here, the version space is the surface segment of the hypersphere
closest to the camera. (b) An SVM classifier in a version space. The dark em-
bedded sphere is the largest radius sphere whose center lies in the version space
and whose surface does not intersect with the hyperplanes. The center of the em-
bedded sphere corresponds to the SVM, its radius is proportional to the margin
of the SVM in F, and the training points corresponding to the hyperplanes that
it touches are the support vectors.
Note that a version space only exists if the training data are linearly separable in the
feature space. Thus, we require linear separability of the training data in the feature space.
This restriction is much less harsh than it might at first seem. First, the feature space often
has a very high dimension and so in many cases it results in the data set being linearly
separable. Second, as noted by Shawe-Taylor and Cristianini (1999), it is possible to modify
any kernel so that the data in the new induced feature space is linearly separable
2
.
There exists a duality between the feature space F and the parameter space W (Vapnik,
1998, Herbrich et al., 2001) which we shall take advantage of in the next section: points in
F correspond to hyperplanes in W and vice versa.
By definition, points in W correspond to hyperplanes in F. The intuition behind the
converse is that observing a training instance x
i
in the feature space restricts the set of
separating hyperplanes to ones that classify x
i
correctly. In fact, we can show that the set
2. This is done by redefining for all training instances x
i
: K(x
i
, x
i
) ← K(x
i
, x
i
)+ν where ν is a positive
regularization constant. This essentially achieves the same effect as the soft margin error function (Cortes
and Vapnik, 1995) commonly used in SVMs. It permits the training data to be linearly non-separable
in the original feature space.
49
剩余21页未读,继续阅读
2023-07-08 上传
2023-05-31 上传
2023-03-31 上传
2023-05-29 上传
2023-05-03 上传
2023-05-15 上传
2023-04-02 上传

jarvan3zZ
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机人脸表情动画技术发展综述
- 关系数据库的关键字搜索技术综述:模型、架构与未来趋势
- 迭代自适应逆滤波在语音情感识别中的应用
- 概念知识树在旅游领域智能分析中的应用
- 构建is-a层次与OWL本体集成:理论与算法
- 基于语义元的相似度计算方法研究:改进与有效性验证
- 网格梯度多密度聚类算法:去噪与高效聚类
- 网格服务工作流动态调度算法PGSWA研究
- 突发事件连锁反应网络模型与应急预警分析
- BA网络上的病毒营销与网站推广仿真研究
- 离散HSMM故障预测模型:有效提升系统状态预测
- 煤矿安全评价:信息融合与可拓理论的应用
- 多维度Petri网工作流模型MD_WFN:统一建模与应用研究
- 面向过程追踪的知识安全描述方法
- 基于收益的软件过程资源调度优化策略
- 多核环境下基于数据流Java的Web服务器优化实现提升性能
