Spark Structured Streaming:流式大数据实时处理解析
"Spark Structured Streaming是Apache Spark项目的一个组件,专注于实时的流式数据处理。它提供了一种声明式的编程模型,使得开发者可以像处理静态数据一样处理持续流入的数据流。该技术在大数据领域中广泛应用,特别是在金融、互联网、零售和交通等领域,对实时数据进行快速响应和决策。”
**流式数据**
流式数据是指随着时间不断产生并持续更新的数据,这种数据源通常无法预先确定其大小,且数据会连续不断地流入。在各种行业中,流式数据都有广泛的应用,例如:
- **金融**:实时股票价格变动、交易数据、外汇汇率等可用于制定即时投资策略。
- **互联网**:网站的点击流、页面浏览量、新用户注册信息等帮助分析用户行为和网站性能。
- **零售**:订单流、物流信息、商品价格调整等用于优化库存管理和销售策略。
- **交通**:交通流量监测、车辆位置信息等可用于交通管理和服务。
**Structured Streaming的核心概念**
Spark Structured Streaming是基于Spark SQL构建的,它引入了持续查询(Continuous Queries)的概念,将流处理与批处理统一在一个抽象层面上。主要特点包括:
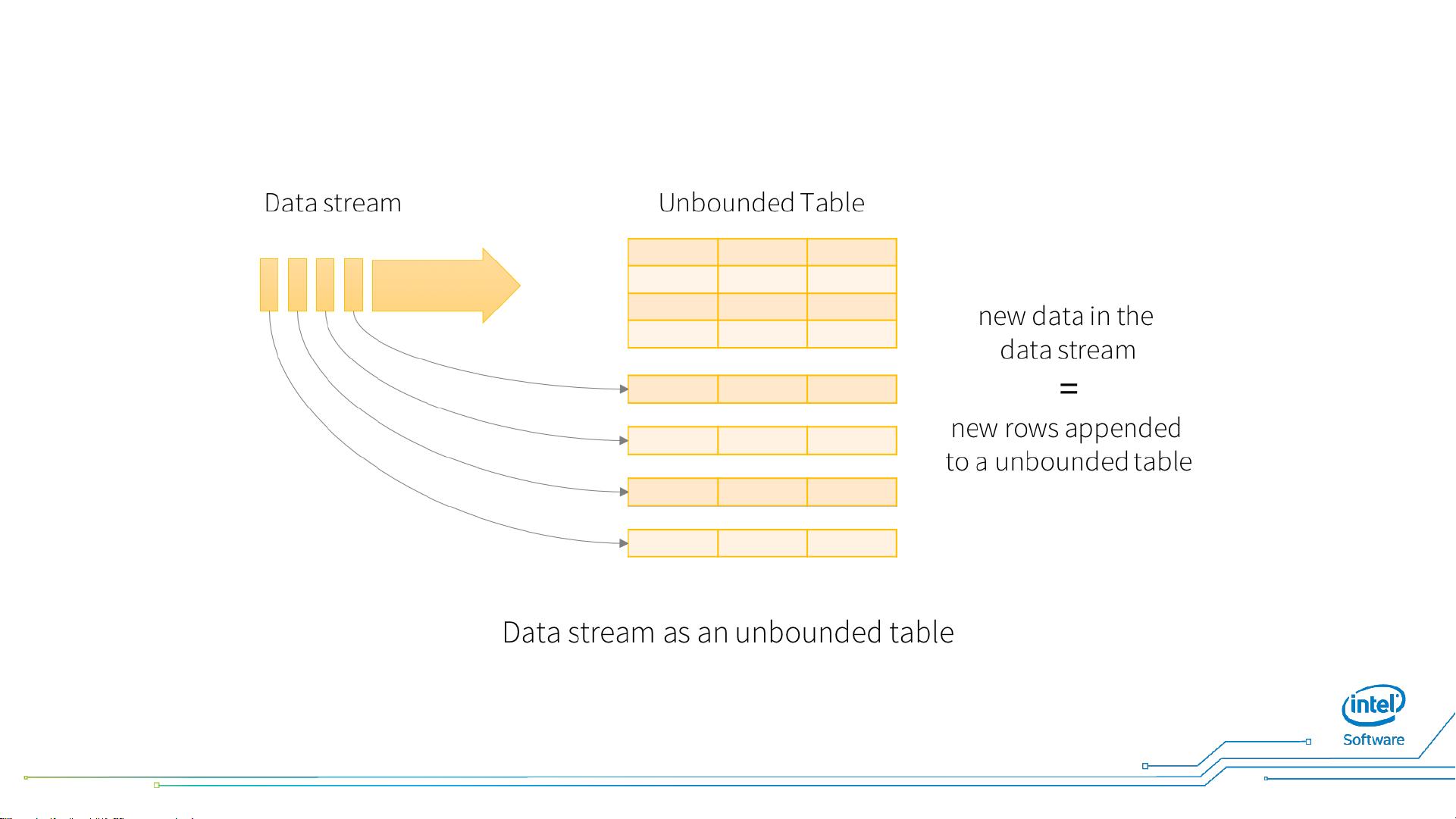
1. **无界数据集(Unbounded Datasets)**:处理无限的数据流,直到数据源停止或者应用程序终止。
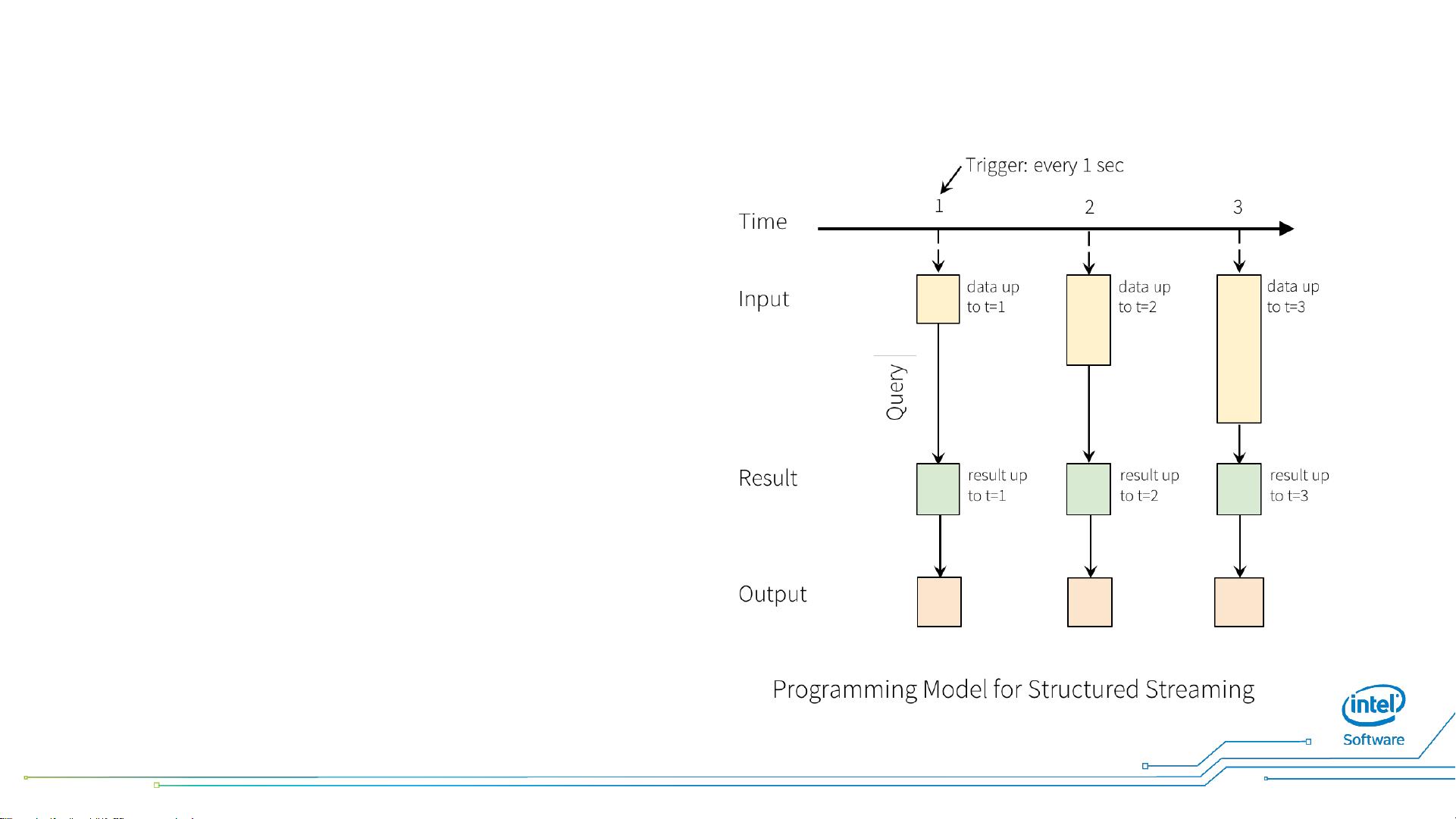
2. **微批处理(Micro-batching)**:以小批量的方式处理数据流,模拟实时处理,同时保持批处理的高效性。
3. **持久化状态(Persistent State)**:允许在处理流数据时维护和更新状态,如计算累计值或滑动窗口。
4. **容错机制**:通过检查点和事件时间处理,确保在故障后能够恢复到一致的状态。
**Structured Streaming的高级话题**
1. **事件时间处理**:与处理系统时间不同,事件时间处理依据数据生成的实际时间,更适应延迟数据到达的情况。
2. **窗口操作**:滑动窗口、会话窗口等提供了处理时间序列数据的灵活性,例如计算每分钟的平均点击率。
3. **状态管理**:支持键值状态、累加器状态等多种状态管理方式,确保状态的一致性和准确性。
4. **多种输出模式**:包括Append模式(追加新数据)、Complete模式(每次更新整个结果集)和Update模式(仅更新结果的改变部分)。
**Structured Streaming的执行原理与高可用**
Spark Structured Streaming通过将流数据拆分成小批次,利用Spark的弹性分布式数据集(Resilient Distributed Datasets, RDDs)进行处理。每个批次的数据都会经过Spark的转换和行动操作,最终将结果写入持久化存储。为了保证高可用,Spark提供了检查点和容错机制,确保在节点故障时可以从最近的检查点恢复,并通过动态调度和资源管理来应对集群中的资源变化。
Spark Structured Streaming是处理流式大数据的强大工具,它通过简单易用的API,结合微批处理和持续查询,实现了高效且可靠的实时数据处理,广泛应用于需要实时分析和响应的业务场景。

The simplest way to perform streaming analytics
is not having to reason about streaming at all
10
剩余56页未读,继续阅读
2020-08-19 上传
点击了解资源详情
2021-02-26 上传
点击了解资源详情
2024-05-29 上传
2021-08-15 上传
2021-01-30 上传

Erjin_Ren
- 粉丝: 13
- 资源: 17
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
