网络爬虫基础与抓取策略解析
"本文详细介绍了网络爬虫的概念、工作流程和常见抓取策略,适合初学者学习。"
网络爬虫是互联网数据采集的关键工具,它模拟用户行为,自动遍历和下载网页,以构建互联网内容的本地备份。搜索引擎依赖网络爬虫来更新其索引,确保搜索结果的实时性和准确性。
一、网络爬虫基本结构与工作流程
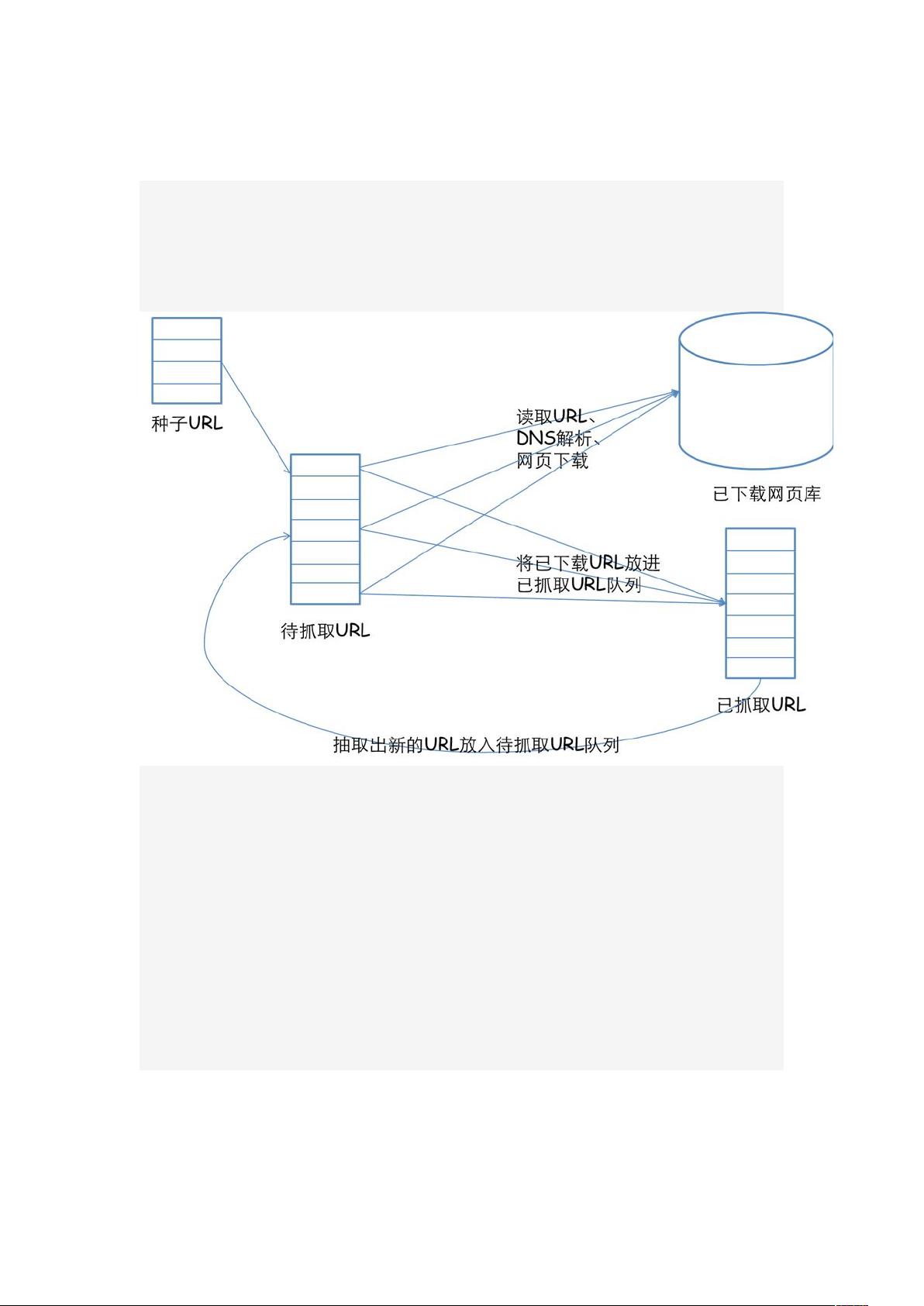
网络爬虫通常由以下几个部分组成:
1. 种子URL:爬虫启动时需要一组初始网址作为起点。
2. 待抓取URL队列:存储待访问的新URL。
3. 已下载网页库:保存已抓取的网页内容。
4. 已抓取URL队列:记录已访问过的URL,避免重复抓取。
爬虫的工作流程包括:
1. 从种子URL开始,将它们放入待抓取队列。
2. 依次取出URL,解析DNS,获取IP,下载网页,存入已下载库,并将新发现的URL加入已抓取队列。
3. 分析已抓取队列中的URL,提取新链接,放入待抓取队列,循环此过程。
二、互联网页面分类
根据爬虫的角度,互联网页面可划分为五类:
1. 已下载未过期网页:最新抓取的网页。
2. 已下载已过期网页:内容发生变化的旧网页。
3. 待下载网页:待抓取URL队列中的网址。
4. 可知网页:可通过分析已抓取或待抓取网页发现的新URL。
5. 不可知网页:爬虫无法直接到达的网页。
三、抓取策略
抓取策略决定了爬虫如何选择和处理URL:
1. 深度优先遍历:从起始页开始,沿着一条链路深入,直至完成,再转向下一个起始页。例如,从A出发,路径为A-F-G-E-H-I-B-C-D。
2. 宽度优先遍历:先抓取起始页的所有链接,然后逐步扩展到下一层。如A-B-C-D-E-F-G-H-I,再处理B-C-D等的链接。
不同的抓取策略适用于不同场景。深度优先适合获取深度较浅的信息,而宽度优先能更广泛地覆盖网页,但可能较慢。
网络爬虫涉及URL管理、网页下载、内容解析等多个环节,理解其工作原理和策略对于进行有效的数据抓取至关重要。对于初学者,从基础知识入手,结合实践操作,可以逐步掌握网络爬虫的精髓。
网络爬虫
网络爬虫是捜索引擎抓取系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本
地形成一个或联网内容的镜像备份。这篇博客主要对爬虫以及抓取系统进行一个简单的概述。
一、网络爬虫的基本结构及工作流程
一个通用的网络爬虫的框架如图所示:
网络爬虫的基本工作流程如下:
1.首先选取一部分精心挑选的种子 URL;
2.将这些 URL 放入待抓取 URL 队列;
3.从待抓取 URL 队列中取出待抓取在 URL,解析 DNS,并且得到主机的 ip,并将 URL 对
应的网页下载下来,存储进已下载网页库中。此外,将这些 URL 放进已抓取 URL 队列。
4.分析已抓取 URL 队列中的 URL,分析其中的其他 URL,并且将 URL 放入待抓取 URL 队
列,从而进入下一个循环。
二、从爬虫的角度对互联网进行划分
对应的,可以将互联网的所有页面分为五个部分:
下载后可阅读完整内容,剩余8页未读,立即下载
2011-08-11 上传
2023-05-22 上传
2024-03-07 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

xiongjinfei201
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- IEEE 14总线系统Simulink模型开发指南与案例研究
- STLinkV2.J16.S4固件更新与应用指南
- Java并发处理的实用示例分析
- Linux下简化部署与日志查看的Shell脚本工具
- Maven增量编译技术详解及应用示例
- MyEclipse 2021.5.24a最新版本发布
- Indore探索前端代码库使用指南与开发环境搭建
- 电子技术基础数字部分PPT课件第六版康华光
- MySQL 8.0.25版本可视化安装包详细介绍
- 易语言实现主流搜索引擎快速集成
- 使用asyncio-sse包装器实现服务器事件推送简易指南
- Java高级开发工程师面试要点总结
- R语言项目ClearningData-Proj1的数据处理
- VFP成本费用计算系统源码及论文全面解析
- Qt5与C++打造书籍管理系统教程
- React 应用入门:开发、测试及生产部署教程
