"本资源为Python爬虫基础的讲解材料,涵盖了网络爬虫的基本概念、工作原理、HTTP协议以及使用Python的requests库进行网络请求的方法。"
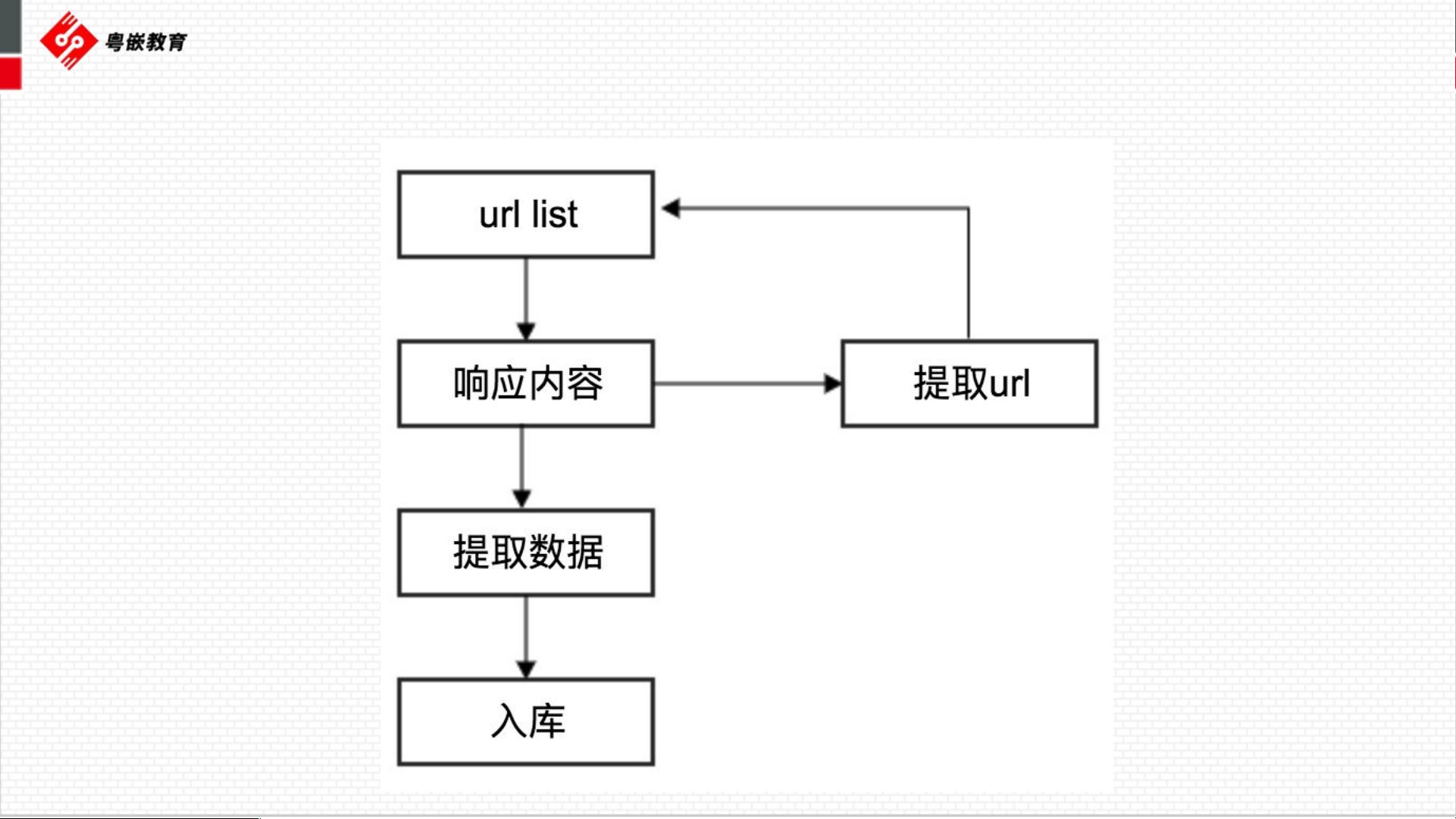
在IT领域,网络爬虫是自动化提取互联网信息的强大工具,它通过模拟浏览器发送HTTP请求并接收响应,按照预设规则抓取所需数据。Python作为一门简洁且功能丰富的编程语言,常被用于开发爬虫项目。本资料主要围绕Python爬虫的基础知识展开,包括以下几个方面:
1. **网络爬虫定义**:
网络爬虫是自动抓取互联网信息的程序,它可以执行类似于浏览器的所有任务。通过发送HTTP请求,爬虫能够获取网页内容,从而实现数据的抓取和分析。
2. **HTTP协议**:
HTTP(超文本传输协议)是互联网上应用最广泛的一种网络协议,它定义了客户端(如浏览器或爬虫)与服务器之间交换数据的格式和交互过程。HTTP请求通常包含请求头(如Host、Connection、User-Agent等)和请求体,而响应则包括状态码(如200表示成功,404表示未找到,500表示服务器错误)和响应体。
3. **查看HTTP请求头**:
要了解HTTP请求的详细信息,可以通过开发者工具查看浏览器发送的请求头。例如,Host指定服务器地址,User-Agent标识客户端类型,Accept指明客户端接受的数据类型,Referer记录了来源页面,Cookie用于保持会话状态,而Connection和Upgrade-Insecure-Requests则涉及连接管理和安全设置。
4. **响应状态码**:
常见的HTTP状态码有200(成功)、302和307(临时重定向)、404(未找到)和500(服务器内部错误)。这些代码有助于理解请求是否成功及服务器的反馈。
5. **requests库**:
requests是Python中的一个库,用于方便地发送HTTP请求并处理响应。使用requests,可以简单地向指定URL发送GET请求,如`response = requests.get(url)`。`response`对象提供了多种属性,如`text`返回响应的文本内容,`content`获取二进制数据,`status_code`则显示请求的状态码。
6. **使用requests库进行网络请求**:
在实际应用中,可能需要处理更复杂的请求,如POST、PUT等,还可以设置请求头、携带cookies、处理重定向等。requests库提供了丰富的API,使得这些操作变得简单易行。
通过学习这些基础知识,你可以开始构建自己的Python爬虫,从互联网上获取数据,无论是进行数据分析、监控网站变化还是进行自动化测试,Python爬虫都能提供强大的支持。对于深入学习,可以参考提供的中文文档API,进一步探索requests库的高级用法。


 我的内容管理
展开
我的内容管理
展开









