Pandas入门:Series与DataFrame操作详解
需积分: 0 154 浏览量
更新于2024-08-04
收藏 256KB DOCX 举报
"Pandas库是Python数据分析领域中的核心库,提供了高效且易于使用的数据结构,如Series和DataFrame。这两个数据类型是Pandas的基础,使得处理和分析数据变得更加便捷。"
在Python中,Pandas库是基于Numpy构建的,主要针对数据分析任务。为了使用Pandas,首先需要导入库,通常使用别名pd,如下所示:
```python
import numpy as np
import pandas as pd
```
1. **Series**
Series是一种一维的数据结构,它可以存储任何数据类型(整数、字符串、浮点数、Python对象等)。Series由一组数据(Values)和相应的索引(Index)组成。当创建Series时,如果没有指定索引,它会自动生成0开始的整数索引。Series可以从以下几种类型创建:
- **从标量值创建**:创建一个只有一个元素的Series,所有索引默认相同。
```python
s = pd.Series(5, index=[0, 1, 2, 3])
```
- **从字典创建**:键作为索引,值作为数据。
```python
dict_data = {'a': 1, 'b': 2, 'c': 3}
s = pd.Series(dict_data)
```
- **从ndarray创建**:数组的元素成为Series的值,如果未指定索引,数组的索引将用于Series。
```python
arr = [1, 2, 3, 4]
s = pd.Series(arr)
```
Series的操作类似于Numpy的数组,支持基本的数学运算,并且在运算时会自动对齐不同的索引。此外,Series允许设置索引名称,这有助于数据的管理和解释。
2. **Series的索引操作**
Series可以有两套索引,系统自动的和用户自定义的。切片操作可以根据这两种索引进行,但需注意不要混淆。例如:
```python
s = pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])
sliced_s = s['b':'d']
```
自定义索引的Series在运算时会自动对齐,即使索引不完全匹配,Pandas也会尝试找到对应位置的元素进行操作。
3. **DataFrame**
DataFrame是Pandas的二维表格型数据结构,它具有行索引(column axis, axis=1)和列索引(index, axis=0)。DataFrame可以存储多种数据类型,并且非常适合处理表格数据。DataFrame的创建方式包括:
- **从二维ndarray生成**:数组的列成为DataFrame的列,行成为行索引。
```python
data = np.array([[1, 2, 3], [4, 5, 6]])
df = pd.DataFrame(data)
```
- **从一维ndarray、列表、字典、元组或Series构成的字典创建**:字典的键成为列名,值成为对应的列数据。
```python
dict_data = {'A': [1, 2, 3], 'B': [4, 5, 6]}
df = pd.DataFrame(dict_data)
```
- **从Series创建**:多个Series可以通过共享相同的索引来合并成DataFrame。
```python
s1 = pd.Series([1, 2, 3], name='A')
s2 = pd.Series([4, 5, 6], name='B')
df = pd.DataFrame({'A': s1, 'B': s2})
```
- **从其他DataFrame创建**:可以直接通过复制或拼接其他DataFrame来创建新的DataFrame。
DataFrame提供了丰富的操作,如选择列、行,过滤数据,合并数据表,计算统计量等。其灵活性和强大的功能使其在数据分析中扮演着至关重要的角色。
Pandas的Series和DataFrame是强大且灵活的数据结构,它们使Python成为数据科学领域的首选语言之一。通过理解并熟练掌握这两个数据类型,你可以更有效地处理和分析各种类型的数据集。
Pandas 是基于 numpy 的一个第三方库,是一个提供高性能易用数据类型和分析工具
调用方法:
```
import numpy as pd
```
Pandas 有两个常用的数据类型:Series 与 DataFrame
Pandas 注重数据与索引的关系,注重应用。Numpy 则注重维度
1,Series
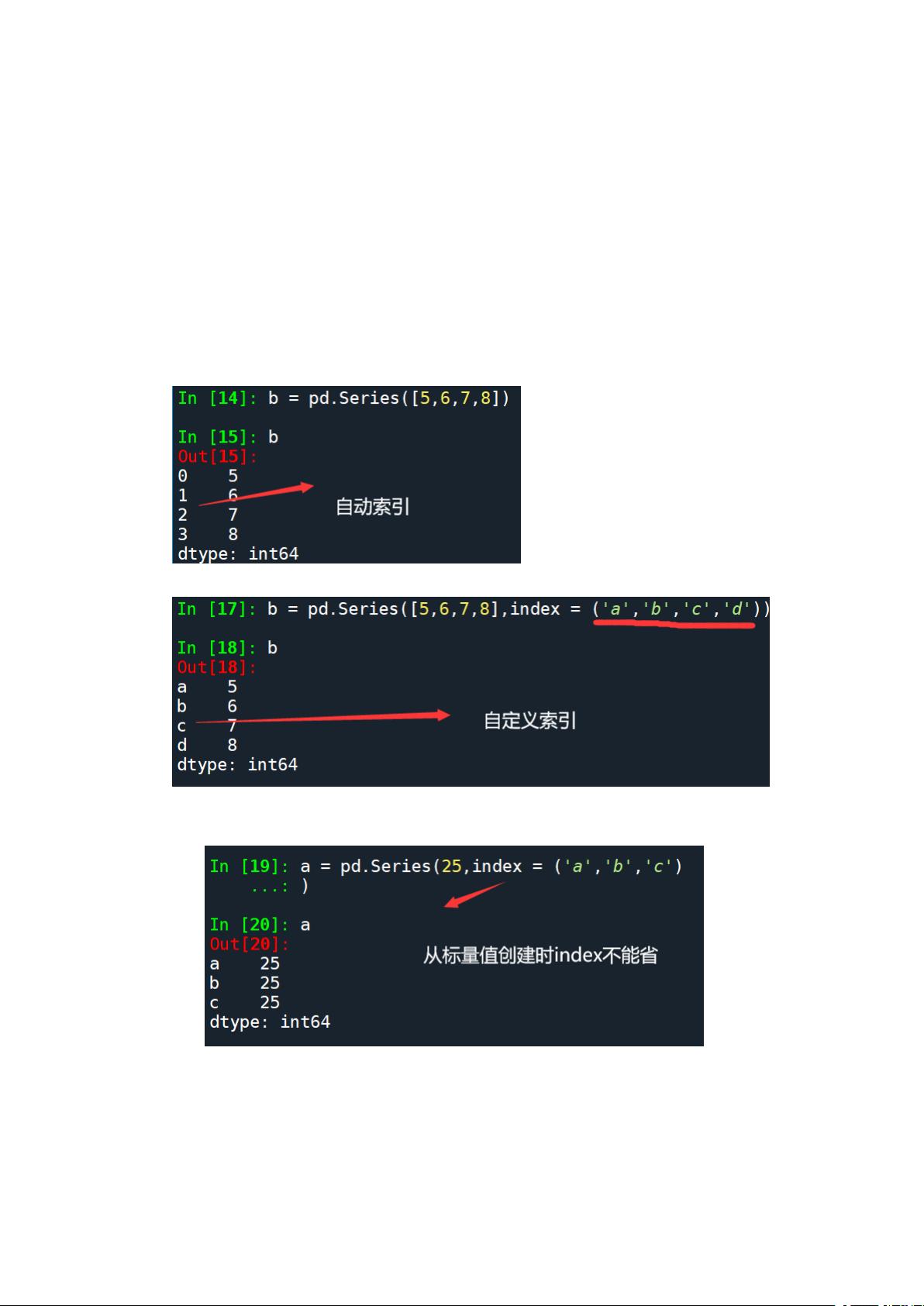
Series 类型是由一组数据(Values)与其索引(index)组成的。输入数据会自动生成从 0 开
始的自动索引
也可以自定义索引:
Series 可由以下类型创建:Python 列表,字典,ndarray,标量值创建
a) 从标量值创建
b) 从字典类型创建
下载后可阅读完整内容,剩余3页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情









