由于SHA-224和SHA-512/224,输出的散列值都是224bits,因此这两个算法的循环次数都是相同的
时间: 2024-05-24 14:15:04 浏览: 104
这个说法是不正确的。SHA-224和SHA-512/224的输出长度都是224 bits,但它们的循环次数是不同的。SHA-224使用和SHA-256相同的循环次数,即64次,而SHA-512/224使用和SHA-512相同的循环次数,即80次。这是因为SHA-224和SHA-512/224分别是SHA-256和SHA-512的变种,它们的设计都是为了在不同的应用场景下提供不同的安全性和效率。
相关问题
HMAC-sha12-224的安全强度为128bits
实际上,HMAC-SHA-224 的安全强度是 112 比特。这是因为 HMAC-SHA-224 使用 SHA-224 哈希函数,其输出长度为 224 比特,但是由于其安全强度受到生日攻击的限制,因此其实际安全强度只有 112 比特。这也是为什么一些安全专家建议使用更强的哈希算法,例如 SHA-256 或 SHA-3,来获得更高的安全强度。
C++实现SHA-1算法
以下是C++实现SHA-1算法的示例代码:
```c++
#include <iostream>
#include <iomanip>
#include <sstream>
#include <string>
#include <cstring>
#include <cstdint>
// 左移循环移位
#define ROTL(x, n) (((x) << (n)) | ((x) >> (32 - (n))))
// SHA-1 常量
#define SHA1_K0 0x5A827999
#define SHA1_K1 0x6ED9EBA1
#define SHA1_K2 0x8F1BBCDC
#define SHA1_K3 0xCA62C1D6
// SHA-1 初始化向量
const std::uint32_t SHA1_IV[] = { 0x67452301, 0xEFCDAB89, 0x98BADCFE, 0x10325476, 0xC3D2E1F0 };
// SHA-1 消息填充
void sha1_pad(std::string& message) {
// 向消息尾部添加一个比特 1
message += '\x80';
// 添加 0 到 64 位填充,使消息长度满足模 512 余 448
std::size_t original_size = message.size();
std::size_t padding_size = (56 - (original_size % 64)) % 64;
message.resize(original_size + padding_size, '\0');
// 在消息尾部添加 64 位的原始消息长度
std::uint64_t message_bits = original_size * 8;
message.append(reinterpret_cast<const char*>(&message_bits), sizeof(message_bits));
}
// SHA-1 压缩函数
void sha1_compress(std::uint32_t* state, const std::uint8_t* block) {
// 初始化变量
std::uint32_t a = state[0];
std::uint32_t b = state[1];
std::uint32_t c = state[2];
std::uint32_t d = state[3];
std::uint32_t e = state[4];
std::uint32_t w[80];
// 将 16 个字分组成 80 个字
for (int i = 0; i < 16; i++) {
w[i] = (block[i * 4] << 24) | (block[i * 4 + 1] << 16) | (block[i * 4 + 2] << 8) | block[i * 4 + 3];
}
for (int i = 16; i < 80; i++) {
w[i] = ROTL(w[i - 3] ^ w[i - 8] ^ w[i - 14] ^ w[i - 16], 1);
}
// SHA-1 主循环
for (int i = 0; i < 80; i++) {
std::uint32_t f, k;
if (i < 20) {
f = (b & c) | ((~b) & d);
k = SHA1_K0;
} else if (i < 40) {
f = b ^ c ^ d;
k = SHA1_K1;
} else if (i < 60) {
f = (b & c) | (b & d) | (c & d);
k = SHA1_K2;
} else {
f = b ^ c ^ d;
k = SHA1_K3;
}
std::uint32_t temp = ROTL(a, 5) + f + e + k + w[i];
e = d;
d = c;
c = ROTL(b, 30);
b = a;
a = temp;
}
// 更新状态
state[0] += a;
state[1] += b;
state[2] += c;
state[3] += d;
state[4] += e;
}
// 计算 SHA-1 哈希值
std::string sha1(const std::string& message) {
// 初始化状态
std::uint32_t state[5];
std::memcpy(state, SHA1_IV, sizeof(SHA1_IV));
// 对消息进行填充
std::string padded_message = message;
sha1_pad(padded_message);
// 对填充后的消息进行压缩
for (std::size_t i = 0; i < padded_message.size(); i += 64) {
sha1_compress(state, reinterpret_cast<const std::uint8_t*>(&padded_message[i]));
}
// 将结果转换为十六进制字符串
std::ostringstream oss;
oss << std::hex << std::setfill('0');
for (int i = 0; i < 5; i++) {
oss << std::setw(8) << state[i];
}
return oss.str();
}
// 测试
int main() {
std::cout << sha1("Hello, world!") << std::endl; // 0x7b502c3a1f48c860e3c0feeb6a1c9a22d1aee6cb
return 0;
}
```
在该实现中,`sha1()` 函数接受一个字符串作为输入,并返回该字符串的 SHA-1 哈希值。哈希值以十六进制字符串的形式返回。
相关推荐
最新推荐
openssl 生成ca证书 pkcs12 pem格式转换
- [digest]:指定 HASH 算法,例如 md5、sha1、md2、mdc2 或 md4。 - config file:指定 openssl 配置文件。 - text:指定文本显示格式。 例如,使用 CA 的 RSA 密钥创建一个自签署的 CA 证书(X.509 结构)的命令...
MD5加密算法 ASP版.doc
由于MD5算法已知存在碰撞攻击的弱点,即不同的输入可能产生相同的输出,因此在现代安全标准中,MD5不再被视为足够安全的加密手段。现在更推荐使用如SHA-256等更强大的哈希函数。然而,对于理解基础的哈希算法和位...
C++中的条件运算符详解
"条件运算符是C++中的三目运算符,用于根据条件选择执行不同的表达式。表达式1?表达式2:表达式3的结构中,如果表达式1的值为真(非零),则执行表达式2;否则执行表达式3。在示例中,max=a>b?a:b用于求a和b中的较大值。条件运算符的优先级高于赋值运算符,例如在x=(x=3)?x+2:x-3中,先进行x=3的赋值,然后根据结果决定执行x+2还是x-3。表达式可以有不同类型的,如z=a>b?'A':a+b,这里结合了字符和数值运算。C++的发展历程中,C语言作为基础,C++在其之上进行了扩展和完善,强调面向对象编程。C语言的特点包括结构化、混合级别(高级和汇编)、可移植性以及灵活但语法不严密,对初学者有一定挑战。"
在深入探讨条件运算符之前,让我们首先回顾一下C++的基本概念。C++是一种强大的、面向对象的编程语言,由Bjarne Stroustrup在C语言的基础上创建。它不仅包含了C语言的所有特性,还引入了类、模板、异常处理等面向对象的概念。
条件运算符,也称为三元运算符,是C++中的一个特殊语法构造,其形式为`expression1 ? expression2 : expression3`。这个运算符根据`expression1`的结果来决定执行`expression2`或`expression3`。如果`expression1`的值非零(即逻辑上为真),则`expression2`的值将被计算并作为整个表达式的结果;反之,如果`expression1`的值为零(逻辑上为假),则`expression3`的值将被计算并返回。这种运算符常用于简单的条件选择,特别是在需要根据条件分配变量值时。
在实际编程中,条件运算符可以提高代码的紧凑性和可读性。例如,`max=a>b?a:b`这个语句用于找出`a`和`b`中的较大值。如果`a`大于`b`,则`max`将被赋值为`a`;否则,`max`将被赋值为`b`。这个运算符的优先级高于赋值运算符,这意味着在`x=(x=3)?x+2:x-3`这样的表达式中,首先执行`x=3`,然后根据`x`的新值决定执行`x+2`还是`x-3`。
在C++中,条件运算符允许三个表达式有不同的类型。例如,`z=a>b?'A':a+b`这个表达式中,`'A'`是一个字符,`a+b`是一个数值,但编译器会自动处理这种类型转换,使得整个表达式能够正常工作。
C语言是C++的前身,以其简洁、灵活性和高效的代码执行而闻名。它支持结构化编程,可以用于编写系统级软件和小型控制程序,同时也适合科学计算。C语言的一个关键特性是它的可移植性,这意味着用C编写的程序可以在不同类型的计算机上运行,只需很少或无需修改。
然而,C语言的语法结构相对较松散,这使得编程者有更大的自由度,但也增加了调试的难度。对于初学者来说,理解和掌握C语言可能需要更多的时间和实践。与更现代的语言相比,C++提供了更严格的类型检查和面向对象的特性,这些特性有助于提高代码的组织性和可维护性,但同时也增加了学习曲线。尽管如此,C++仍然是许多专业软件开发和系统编程的首选语言。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
联邦学习:打破数据孤岛,实现协作式云服务,云计算的未来
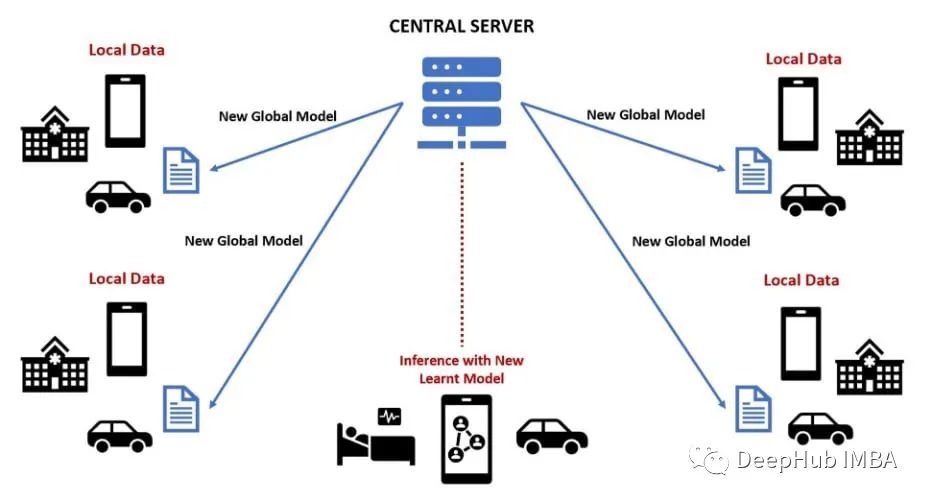
# 1. 联邦学习概览
联邦学习是一种分布式机器学习范式,允许在不共享原始数据的情况下,从多个参与方联合训练机器学习模型。它旨在解决数据隐私和安全问题,同时利用来自不同来源的数据丰富模型。
联邦学习的独特之处在于,它允许参与方在本地训练模型,并仅共享模型更新,而不是原始数据。通过这种方式,数据隐私得到保护,同时仍能利用集体数据的力量来训练更准确和
AttributeError: 'RFECV' object has no attribute 'ranking_'
`AttributeError: 'RFECV' object has no attribute 'ranking_'` 这个错误意味着当你尝试访问名为`'ranking_'`的属性时,`RFECV`对象并不具备这样的属性。RFECV (Recursive Feature Elimination with Cross-Validation) 是一种特征选择工具,在scikit-learn库中用于递归地删除变量并评估模型性能,直到找到最佳的变量组合。
`ranking_` 属性通常是在循环结束后,保存了每次交叉验证过程中特征的重要性排名。如果你试图在循环过程中或尚未完成选择过程时获取这个属性,
C++程序设计解析:变量a,b,c的值变化分析
"谭浩强 C++ ppt - 讨论C++编程中的变量赋值和条件运算符"
在C++编程中,理解变量的赋值和条件运算符是至关重要的。题目给出的程序段展示了如何使用这些概念,以及它们在实际编程中的效果。这段代码如下:
```cpp
int x=10, y=9;
int a, b, c;
a=(--x==y++)?--x:++y;
b=x++;
c=y;
```
首先,我们分析每个变量的赋值过程:
1. `x` 初始化为10,`y` 初始化为9。
2. 在表达式 `a=(--x==y++)?--x:++y` 中,条件运算符 `? :` 被用来根据条件决定赋值给 `a` 的值。首先,`--x` 将 `x` 减1变为9,然后与 `y++` 比较。由于 `x` 现在等于9,且 `y++` 之后 `y` 变为10,所以条件 `--x == y++` 为真。
3. 当条件为真时,条件运算符后面的 `--x` 执行,`x` 再次减1变为8,因此 `a` 被赋值为8。
4. 接下来,`b=x++;` 这一行将 `x` 的当前值(8)赋给 `b`,然后 `x` 自增1变为9。
5. 最后,`c=y;` 将 `y` 的值(10)赋给 `c`。
因此,执行完这段程序后,变量的值是:`x=9`, `y=10`, `a=8`, `b=8`, `c=10`。但题目中给出的最终值有一些错误,应该是 `x=9`, `y=10`, `a=8`, `b=9`, `c=10`。
这段程序展示了C++中的一些关键特性,如前置递减和后置递增运算符(`--x` 和 `x++`),以及条件运算符的用法。前置递减/增加运算符会先改变变量的值,然后返回新的值;而后置递减/增加运算符则先返回当前值,然后才改变变量的值。
C++是建立在C语言基础之上的,保留了C语言的很多特性,如结构化编程、丰富的运算符和高效的代码执行。C++还引入了面向对象编程的概念,如类、对象、封装、继承和多态,以及模板和异常处理等高级特性。然而,这也意味着C++对于初学者来说可能更具挑战性,因为它的语法相对宽松,可能导致不易察觉的错误,尤其是在处理指针和内存管理时。
C语言因为其高效和良好的可移植性,被广泛用于系统级编程和嵌入式系统。C++则在保持这些优点的同时,提供了更高级的抽象和编程模型,适用于开发复杂的软件系统,尤其是游戏引擎、图形用户界面和大型企业应用等领域。
"互动学习:行动中的多样性与论文攻读经历"
多样性她- 事实上SCI NCES你的时间表ECOLEDO C Tora SC和NCESPOUR l’Ingén学习互动,互动学习以行动为中心的强化学习学会互动,互动学习,以行动为中心的强化学习计算机科学博士论文于2021年9月28日在Villeneuve d'Asq公开支持马修·瑟林评审团主席法布里斯·勒菲弗尔阿维尼翁大学教授论文指导奥利维尔·皮耶昆谷歌研究教授:智囊团论文联合主任菲利普·普雷教授,大学。里尔/CRISTAL/因里亚报告员奥利维耶·西格德索邦大学报告员卢多维奇·德诺耶教授,Facebook /索邦大学审查员越南圣迈IMT Atlantic高级讲师邀请弗洛里安·斯特鲁布博士,Deepmind对于那些及时看到自己错误的人...3谢谢你首先,我要感谢我的两位博士生导师Olivier和Philippe。奥利维尔,"站在巨人的肩膀上"这句话对你来说完全有意义了。从科学上讲,你知道在这篇论文的(许多)错误中,你是我可以依
联邦学习:挖掘数据协作的商业价值,投资机会不容错过

# 1. 联邦学习的理论基础
联邦学习是一种分布式机器学习技术,它允许多个参与者在不共享原始数据的情况下共同训练模型。这种方法通过保护数据隐私和打破数据孤岛,为协作数据分析和建模提供了新的可能性。
### 1.1 联邦学习的原理
联邦学习遵循以下基本原理:
- **数据分散:**参与者保持其数据本地,不与其他参与者共享。
- **模型聚合:**参与者在本地训练模型,然后将模型更新(例如梯度)聚合
neo4j➕经典模型
Neo4j是一款专为处理图形数据设计的开源数据库,它采用图数据库模型,而非传统的表格型结构。在经典模型(比如关系数据库模型)中,数据通常存储在表之间通过键值对的关系链接,而 Neo4j则使用节点(Nodes)代表实体,边(Edges)表示它们之间的关联。
在Neo4j中,你可以创建节点来表示复杂的实体和属性,例如用户、产品或事件,并使用边来表示它们之间的关系,如“朋友”、“购买”或“包含”。这种非结构化的方式非常适合处理大量相互关联的数据,尤其是在社交网络、推荐系统或知识图谱等场景中。
经典模型适合于数据有明显的一对一或多对多关系的情况,而Neo4j则更适合处理复杂和动态的网络型数据。结合