mmdetection配置文件中的num_workers是什么参数
时间: 2024-04-04 07:35:19 浏览: 21
在 mmdetection 中,`num_workers` 是指在训练时用于数据加载的进程数量。具体来说,它控制了数据加载器中的进程数。在训练时,数据加载是一个非常耗时的过程,通过增加 `num_workers` 可以加快数据加载速度,从而提高训练效率。但是,需要注意的是,增加 `num_workers` 也会增加系统的负载,可能会导致内存不足或者数据加载器卡死等问题。因此,需要根据实际情况进行调整。
相关问题
mmdetection配置文件解读
mmdetection是一个基于PyTorch的目标检测框架,其配置文件是控制模型训练、测试和推理的重要参数。下面是一个mmdetection配置文件的解读:
```python
# model settings
model = dict(
type='RetinaNet',
pretrained='torchvision://resnet50',
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
style='pytorch'),
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
num_outs=5),
bbox_head=dict(
type='RetinaHead',
num_classes=80,
in_channels=256,
stacked_convs=4,
feat_channels=256,
octave_base_scale=4,
scales_per_octave=3,
anchor_ratios=[0.5, 1.0, 2.0],
anchor_strides=[8, 16, 32, 64, 128],
target_means=[.0, .0, .0, .0],
target_stds=[1.0, 1.0, 1.0, 1.0],
loss_cls=dict(
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=1.0),
loss_bbox=dict(type='SmoothL1Loss', beta=0.11, loss_weight=1.0)),
# training and testing settings
train_cfg=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.4,
min_pos_iou=0,
ignore_iof_thr=-1),
smoothl1_beta=1.0,
allowed_border=-1,
pos_weight=-1,
debug=False),
test_cfg=dict(
nms_pre=1000,
min_bbox_size=0,
score_thr=0.05,
nms=dict(type='nms', iou_threshold=0.5),
max_per_img=100))
# dataset settings
dataset_type = 'CocoDataset'
data_root = 'data/coco/'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]
data = dict(
samples_per_gpu=2,
workers_per_gpu=2,
train=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_train2017.json',
img_prefix=data_root + 'train2017/',
pipeline=train_pipeline),
val=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_val2017.json',
img_prefix=data_root + 'val2017/',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_val2017.json',
img_prefix=data_root + 'val2017/',
pipeline=test_pipeline))
evaluation = dict(interval=1, metric='bbox')
# optimizer
optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001)
optimizer_config = dict(grad_clip=dict(max_norm=35, norm_type=2))
# learning policy
lr_config = dict(
policy='step',
warmup='linear',
warmup_iters=500,
warmup_ratio=0.001,
step=[8, 11])
total_epochs = 12
# checkpoints
checkpoint_config = dict(interval=1)
log_config = dict(interval=50, hooks=[dict(type='TextLoggerHook')])
# runtime settings
dist_params = dict(backend='nccl')
log_level = 'INFO'
work_dir = './work_dirs/retinanet_r50_fpn_1x'
load_from = None
resume_from = None
workflow = [('train', 1)]
```
上述配置文件的主要部分包括:
1. `model`:模型设置,包括模型类型、预训练模型、骨干网络、neck、bbox_head等。
2. `dataset`:数据集设置,包括数据集类型、数据集路径、数据预处理管道等。
3. `optimizer`:优化器设置,包括优化器类型、学习率、动量、权重衰减等。
4. `lr_config`:学习率调整策略,包括学习率策略、热身策略、步数和对应学习率等。
5. `total_epochs`:训练总轮数。
6. `checkpoint_config`:保存模型检查点的间隔。
7. `log_config`:日志设置,包括日志输出间隔和日志输出方式等。
8. `dist_params`:分布式参数设置,包括分布式后端等。
9. `work_dir`:训练、测试和推理结果保存路径。
10. `load_from`和`resume_from`:模型加载和恢复路径。
11. `workflow`:训练、测试和推理流程,包括每个阶段的GPU数量。
mmdetection检测的配置文件是哪个
mmdetection检测的配置文件是模型的配置文件,通常以`.py`格式保存。在mmdetection中,模型的配置文件一般位于`configs`文件夹中,可以根据不同的任务和模型选择相应的配置文件进行调整。例如,对于目标检测任务,可以选择`configs/`下的`faster_rcnn`、`retinanet`、`ssd`等不同模型的配置文件。
相关推荐
最新推荐
mmdetection 模型评测指标
3. 算法评测参数: bbox —— 目标检测框 segm —— 目标分割结果 4. 模型的判断标准有AP(平均精确率) 和AR(平均召回率) 两大类,在机械臂项目中,主要依据AP 来进行评测。 MAP —— mean Average Precision,...
安全隐患台账(模版).xls
安全隐患台账(模版).xls
基于 Java+Mysql 实现的小型仓库管理系统-课程设计(含课设文档+源码)
【作品名称】:基于 Java+Mysql 实现的小型仓库管理系统-课程设计(含课设文档+源码)
【适用人群】:适用于希望学习不同技术领域的小白或进阶学习者。可作为毕设项目、课程设计、大作业、工程实训或初期项目立项。
【项目介绍】:项目说明
1、项目结构:maven+mvc(M模型用的是mybatis技术)
2、项目模式:C/S(客户机/服务器)模式
3、编辑器:IDEA 2019.3.1
4、mysql版本号:5.1.38
zigbee-cluster-library-specification
最新的zigbee-cluster-library-specification说明文档。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
优化MATLAB分段函数绘制:提升效率,绘制更快速

# 1. MATLAB分段函数绘制概述**
分段函数绘制是一种常用的技术,用于可视化不同区间内具有不同数学表达式的函数。在MATLAB中,分段函数可以通过使用if-else语句或switch-case语句来实现。
**绘制过程**
MATLAB分段函数绘制的过程通常包括以下步骤:
1.
SDN如何实现简易防火墙
SDN可以通过控制器来实现简易防火墙。具体步骤如下:
1. 定义防火墙规则:在控制器上定义防火墙规则,例如禁止某些IP地址或端口访问,或者只允许来自特定IP地址或端口的流量通过。
2. 获取流量信息:SDN交换机会将流量信息发送给控制器。控制器可以根据防火墙规则对流量进行过滤。
3. 过滤流量:控制器根据防火墙规则对流量进行过滤,满足规则的流量可以通过,不满足规则的流量则被阻止。
4. 配置交换机:控制器根据防火墙规则配置交换机,只允许通过满足规则的流量,不满足规则的流量则被阻止。
需要注意的是,这种简易防火墙并不能完全保护网络安全,只能起到一定的防护作用,对于更严格的安全要求,需要
JSBSim Reference Manual
JSBSim参考手册,其中包含JSBSim简介,JSBSim配置文件xml的编写语法,编程手册以及一些应用实例等。其中有部分内容还没有写完,估计有生之年很难看到完整版了,但是内容还是很有参考价值的。
"互动学习:行动中的多样性与论文攻读经历"
多样性她- 事实上SCI NCES你的时间表ECOLEDO C Tora SC和NCESPOUR l’Ingén学习互动,互动学习以行动为中心的强化学习学会互动,互动学习,以行动为中心的强化学习计算机科学博士论文于2021年9月28日在Villeneuve d'Asq公开支持马修·瑟林评审团主席法布里斯·勒菲弗尔阿维尼翁大学教授论文指导奥利维尔·皮耶昆谷歌研究教授:智囊团论文联合主任菲利普·普雷教授,大学。里尔/CRISTAL/因里亚报告员奥利维耶·西格德索邦大学报告员卢多维奇·德诺耶教授,Facebook /索邦大学审查员越南圣迈IMT Atlantic高级讲师邀请弗洛里安·斯特鲁布博士,Deepmind对于那些及时看到自己错误的人...3谢谢你首先,我要感谢我的两位博士生导师Olivier和Philippe。奥利维尔,"站在巨人的肩膀上"这句话对你来说完全有意义了。从科学上讲,你知道在这篇论文的(许多)错误中,你是我可以依
揭秘MATLAB分段函数绘制技巧:掌握绘制分段函数图的精髓
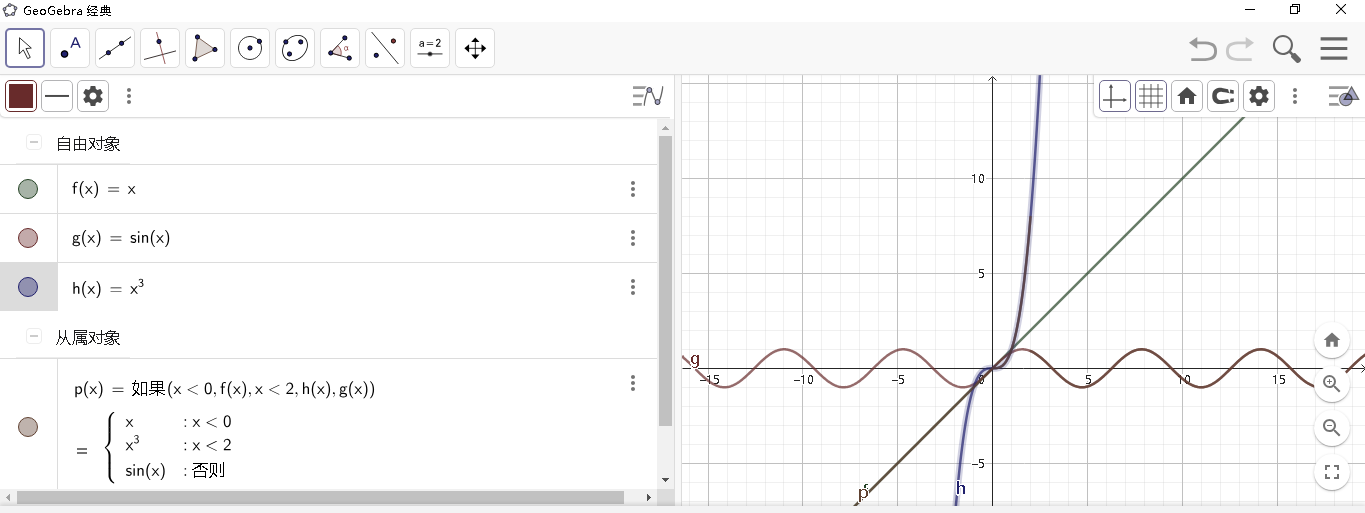
# 1. MATLAB分段函数的概念和基本语法**
分段函数是一种将函数域划分为多个子域,并在每个子域上定义不同函数表达式的函数。在MATLAB中,可以使用`piecewise`函数来定义分段函数。其语法为:
```
y = piecewise(x, x1, y1, ..., xn, yn)
```
其中:
* `x`:自变量。
* `x1`, `y1`, ..., `xn`,