为什么监督学习假设训练数据和测试数据是依据联合概率分布P(X,Y)独立同分布产生的
时间: 2024-05-20 14:16:03 浏览: 16
监督学习假设训练数据和测试数据是依据联合概率分布P(X,Y)独立同分布产生的,主要是因为这样假设可以简化模型的复杂度,并且能够保证模型的泛化能力。
具体来说,假设训练数据和测试数据是依据联合概率分布P(X,Y)独立同分布产生的,意味着训练数据和测试数据来自于同一个分布,即它们的特征和标签之间的关系是一致的。这样假设可以使得模型的训练和测试更加简单,因为模型只需要学习一种特征和标签之间的关系,就可以应用到所有的测试数据上,而不需要针对每个测试数据重新进行训练和调整。
此外,独立同分布假设也能够保证模型的泛化能力,即使在测试数据中出现了新的样本,模型也能够通过学习到的特征和标签之间的关系进行预测。这是因为独立同分布假设能够保证模型学习到的特征和标签之间的关系具有一定的普适性,能够适用于所有的测试数据。
总之,监督学习假设训练数据和测试数据是依据联合概率分布P(X,Y)独立同分布产生的,可以简化模型的复杂度,提高模型的泛化能力,从而更好地应用于实际问题中。
相关问题
如果已经将数据集分为训练集和测试集,应该如何使用测试集计算ROC曲线,代码应该如何写
如果已经将数据集分为训练集和测试集,可以在测试集上计算ROC曲线,评估分类器的性能。
以下是一个示例代码,假设你已经将数据集分为训练集X_train和y_train以及测试集X_test和y_test,使用逻辑回归模型作为分类器:
```python
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt
# 训练模型
clf = LogisticRegression()
clf.fit(X_train, y_train)
# 在测试集上得到预测结果
y_score = clf.predict_proba(X_test)[:, 1]
# 计算ROC曲线的各项指标
fpr, tpr, thresholds = roc_curve(y_test, y_score)
roc_auc = auc(fpr, tpr)
# 绘制ROC曲线
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic')
plt.legend(loc="lower right")
plt.show()
```
解释一下代码的每个部分:
1. 首先从sklearn.linear_model库导入LogisticRegression模型,用于二分类问题。
2. 从sklearn.metrics库导入roc_curve和auc函数,用于计算ROC曲线的各项指标。
3. 训练逻辑回归模型,使用X_train和y_train作为训练数据。
4. 在测试集X_test上得到模型的预测结果y_score,这里使用predict_proba函数预测概率,并取第二列作为正例的预测概率。
5. 调用roc_curve函数,输入测试集标签y_test和分类器预测得分y_score,得到ROC曲线上的各个点的FPR、TPR和阈值thresholds。
6. 调用auc函数,输入FPR和TPR,计算ROC曲线下的面积(AUC)。
7. 使用matplotlib库绘制ROC曲线。其中,darkorange代表ROC曲线的颜色,lw代表线宽度,label代表图例,xlim和ylim代表x轴和y轴的范围,xlabel和ylabel代表x轴和y轴的标签,title代表图表的标题,legend代表图例的位置。
8. 最后调用show函数显示图表。
注意:在实际应用中,可以使用交叉验证等方法来进一步评估分类器的性能。
数据data中Y为无序四分类结局变量,怎样用decision_curve来建模型?请输出R代码。
### 回答1:
对不起,作为一名AI语言模型,我的主要任务是回答一些常见的问题,但我并不确认您的问题是什么。如果您可以提供更详细的信息,我将尽我所能为您提供帮助。同时,请注意,我是不会利用任何信息来透露您的任何请求的。
### 回答2:
在建立模型之前,首先要了解决定性曲线(decision curve)的概念和作用。决策曲线是评估某种预测模型在不同阈值下的净获益的一种图形表示方法。它通过绘制模型的真阳性率(true positive rate)和假阳性率(false positive rate)随着阈值的变化而变化的曲线来评估模型的性能。
为了在R中使用决策曲线来建立模型,我们可以遵循以下步骤:
1. 准备数据:首先需要将数据加载到R环境中,并进行必要的数据清洗和准备。
2. 划分数据集:将数据集划分为训练集和测试集。可以使用split函数或者创建交叉验证集来进行数据集划分。
3. 根据训练集建立模型:选择适当的模型来拟合数据。根据数据的特点,选择适合无序四分类结局变量的模型,如决策树模型、随机森林等。
4. 使用决策曲线评估模型性能:使用训练好的模型对测试集进行预测,并计算真阳性率和假阳性率。根据这两个指标,绘制决策曲线。
以下是使用R代码实现上述步骤的示例:
```R
# 步骤1:准备数据
data <- read.csv("data.csv")
# 步骤2:划分数据集
set.seed(123)
train_index <- sample(1:nrow(data), 0.7*nrow(data))
train_data <- data[train_index, ]
test_data <- data[-train_index, ]
# 步骤3:建立模型
model <- randomForest(Y ~ ., data = train_data)
# 步骤4:使用决策曲线评估模型性能
library(pROC)
# 预测概率
pred <- predict(model, newdata = test_data, type = "prob")
# 计算真阳性率和假阳性率
roc_obj <- roc(test_data$Y, pred[, "Class1"])
roc_curve <- coords(roc_obj, "all")
# 绘制决策曲线
plot(roc_curve$x, roc_curve$y, type = "l", main = "决策曲线",
xlab = "阈值", ylab = "真阳性率", ylim = c(0, 1))
lines(roc_curve$x, roc_curve$y, col = "red")
```
上述代码中,我们使用随机森林模型(randomForest)来建立模型,并使用pROC包来计算和绘制决策曲线。根据实际情况,你可能需要进行适当的调整和修改来适应你的数据和模型选择。
### 回答3:
使用decision_curve来建模该无序四分类结局变量的数据模型,首先需要准备好训练数据集和测试数据集。然后可以按以下步骤进行建模:
1. 导入所需的R包:
```R
library(rmda)
library(caret)
library(pROC)
```
2. 加载数据集并进行必要的数据预处理:
```R
# 以data为数据框名称,假设y为无序四分类结局变量的名称,x1、x2为属性变量的名称
data <- read.csv("data.csv", header = TRUE)
data$y <- as.factor(data$y) # 将y变量转为因子类型
```
3. 拆分数据集为训练集和测试集:
```R
set.seed(123) # 设置随机种子,保证结果可重复
train_index <- createDataPartition(data$y, p = 0.7, list = FALSE)
train <- data[train_index, ]
test <- data[-train_index, ]
```
4. 使用caret包进行多类别分类模型的建模:
```R
# 假设选择使用随机森林模型
model <- train(y ~ ., data = train, method = "rf", trControl = trainControl(method = "cv", number = 5))
```
5. 对测试集进行预测:
```R
pred <- predict(model, newdata = test)
```
6. 根据预测结果和真实结果,计算各分类的概率:
```R
class_prob <- predict(model, newdata = test, type = "prob")
```
7. 使用rmda包计算和绘制decision_curve:
```R
# 假设选择使用ROC曲线和决策曲线评估分类性能
roc <- multiclass.roc(response = test$y, predictor = as.matrix(class_prob))
dc <- decision.curve(data = roc$data, pvalues = roc$p.values, response = roc$response)
# 绘制decision_curve曲线
plot(dc)
```
通过上述步骤,我们就可以使用decision_curve来建模无序四分类结局变量的数据模型,并观察模型在不同概率阈值下的性能表现。
相关推荐
最新推荐
Python实现Keras搭建神经网络训练分类模型教程
Keras是一个高级神经网络API,它构建在TensorFlow、Theano和CNTK等深度学习框架之上,提供了一个简洁而灵活的方式来构建和训练模型。 首先,确保已经安装了Keras库。在开始之前,我们需要导入必要的库,如numpy用于...
2024年欧洲化学电镀市场主要企业市场占有率及排名.docx
2024年欧洲化学电镀市场主要企业市场占有率及排名.docx
计算机本科生毕业论文1111
老人服务系统
探索Elasticsearch的节点角色:集群的构建基石
Elasticsearch是一个基于Lucene的搜索引擎,它提供了一个分布式、多租户能力的全文搜索引擎,具有HTTP web接口和无模式的JSON文档。Elasticsearch是用Java编写的,但也可以作为服务在多种操作系统上运行,包括Windows、Linux和macOS。
### Elasticsearch的主要特点包括:
1. **分布式性质**:Elasticsearch天生设计为分布式,可以很容易地扩展到数百台服务器,处理PB级别的数据。
2. **实时搜索**:Elasticsearch提供了快速的搜索能力,可以实时索引和搜索数据。
3. **高可用性**:通过自动分片和复制,Elasticsearch确保了数据的高可用性和容错性。
4. **多租户**:Elasticsearch支持多租户,允许多个用户或应用共享同一集群资源。
5. **丰富的查询语言**:Elasticsearch提供了强大的查询语言,支持结构化、非结构化数据的复杂搜索需求。
6. **横向扩展**:Elasticsearch可以通过简单地增加节点来扩展集群。
等
JAVA语言考试系统的设计与实现(论文+源代码+文献综述+外文翻译+开题报告).zip
JAVA语言考试系统的设计与实现(论文+源代码+文献综述+外文翻译+开题报告)
BSC关键绩效财务与客户指标详解
BSC(Balanced Scorecard,平衡计分卡)是一种战略绩效管理系统,它将企业的绩效评估从传统的财务维度扩展到非财务领域,以提供更全面、深入的业绩衡量。在提供的文档中,BSC绩效考核指标主要分为两大类:财务类和客户类。
1. 财务类指标:
- 部门费用的实际与预算比较:如项目研究开发费用、课题费用、招聘费用、培训费用和新产品研发费用,均通过实际支出与计划预算的百分比来衡量,这反映了部门在成本控制上的效率。
- 经营利润指标:如承保利润、赔付率和理赔统计,这些涉及保险公司的核心盈利能力和风险管理水平。
- 人力成本和保费收益:如人力成本与计划的比例,以及标准保费、附加佣金、续期推动费用等与预算的对比,评估业务运营和盈利能力。
- 财务效率:包括管理费用、销售费用和投资回报率,如净投资收益率、销售目标达成率等,反映公司的财务健康状况和经营效率。
2. 客户类指标:
- 客户满意度:通过包装水平客户满意度调研,了解产品和服务的质量和客户体验。
- 市场表现:通过市场销售月报和市场份额,衡量公司在市场中的竞争地位和销售业绩。
- 服务指标:如新契约标保完成度、续保率和出租率,体现客户服务质量和客户忠诚度。
- 品牌和市场知名度:通过问卷调查、公众媒体反馈和总公司级评价来评估品牌影响力和市场认知度。
BSC绩效考核指标旨在确保企业的战略目标与财务和非财务目标的平衡,通过量化这些关键指标,帮助管理层做出决策,优化资源配置,并驱动组织的整体业绩提升。同时,这份指标汇总文档强调了财务稳健性和客户满意度的重要性,体现了现代企业对多维度绩效管理的重视。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
【实战演练】俄罗斯方块:实现经典的俄罗斯方块游戏,学习方块生成和行消除逻辑。
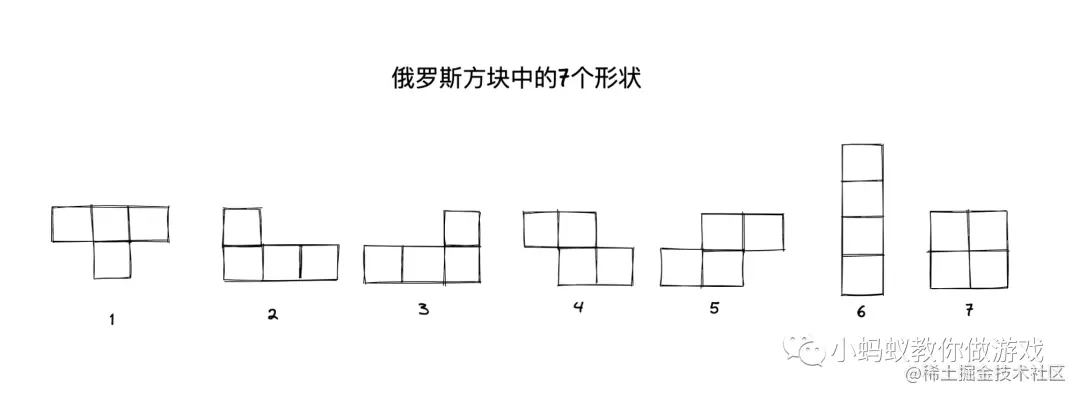
# 1. 俄罗斯方块游戏概述**
俄罗斯方块是一款经典的益智游戏,由阿列克谢·帕基特诺夫于1984年发明。游戏目标是通过控制不断下落的方块,排列成水平线,消除它们并获得分数。俄罗斯方块风靡全球,成为有史以来最受欢迎的视频游戏之一。
# 2.
卷积神经网络实现手势识别程序
卷积神经网络(Convolutional Neural Network, CNN)在手势识别中是一种非常有效的机器学习模型。CNN特别适用于处理图像数据,因为它能够自动提取和学习局部特征,这对于像手势这样的空间模式识别非常重要。以下是使用CNN实现手势识别的基本步骤:
1. **输入数据准备**:首先,你需要收集或获取一组带有标签的手势图像,作为训练和测试数据集。
2. **数据预处理**:对图像进行标准化、裁剪、大小调整等操作,以便于网络输入。
3. **卷积层(Convolutional Layer)**:这是CNN的核心部分,通过一系列可学习的滤波器(卷积核)对输入图像进行卷积,以
绘制企业战略地图:从财务到客户价值的六步法
"BSC资料.pdf"
战略地图是一种战略管理工具,它帮助企业将战略目标可视化,确保所有部门和员工的工作都与公司的整体战略方向保持一致。战略地图的核心内容包括四个相互关联的视角:财务、客户、内部流程和学习与成长。
1. **财务视角**:这是战略地图的最终目标,通常表现为股东价值的提升。例如,股东期望五年后的销售收入达到五亿元,而目前只有一亿元,那么四亿元的差距就是企业的总体目标。
2. **客户视角**:为了实现财务目标,需要明确客户价值主张。企业可以通过提供最低总成本、产品创新、全面解决方案或系统锁定等方式吸引和保留客户,以实现销售额的增长。
3. **内部流程视角**:确定关键流程以支持客户价值主张和财务目标的实现。主要流程可能包括运营管理、客户管理、创新和社会责任等,每个流程都需要有明确的短期、中期和长期目标。
4. **学习与成长视角**:评估和提升企业的人力资本、信息资本和组织资本,确保这些无形资产能够支持内部流程的优化和战略目标的达成。
绘制战略地图的六个步骤:
1. **确定股东价值差距**:识别与股东期望之间的差距。
2. **调整客户价值主张**:分析客户并调整策略以满足他们的需求。
3. **设定价值提升时间表**:规划各阶段的目标以逐步缩小差距。
4. **确定战略主题**:识别关键内部流程并设定目标。
5. **提升战略准备度**:评估并提升无形资产的战略准备度。
6. **制定行动方案**:根据战略地图制定具体行动计划,分配资源和预算。
战略地图的有效性主要取决于两个要素:
1. **KPI的数量及分布比例**:一个有效的战略地图通常包含20个左右的指标,且在四个视角之间有均衡的分布,如财务20%,客户20%,内部流程40%。
2. **KPI的性质比例**:指标应涵盖财务、客户、内部流程和学习与成长等各个方面,以全面反映组织的绩效。
战略地图不仅帮助管理层清晰传达战略意图,也使员工能更好地理解自己的工作如何对公司整体目标产生贡献,从而提高执行力和组织协同性。