Python自定义数据结构实战:从理论到实践
发布时间: 2024-09-11 15:35:25 阅读量: 169 订阅数: 66 

Python编程:从入门到实践课后习题.zip
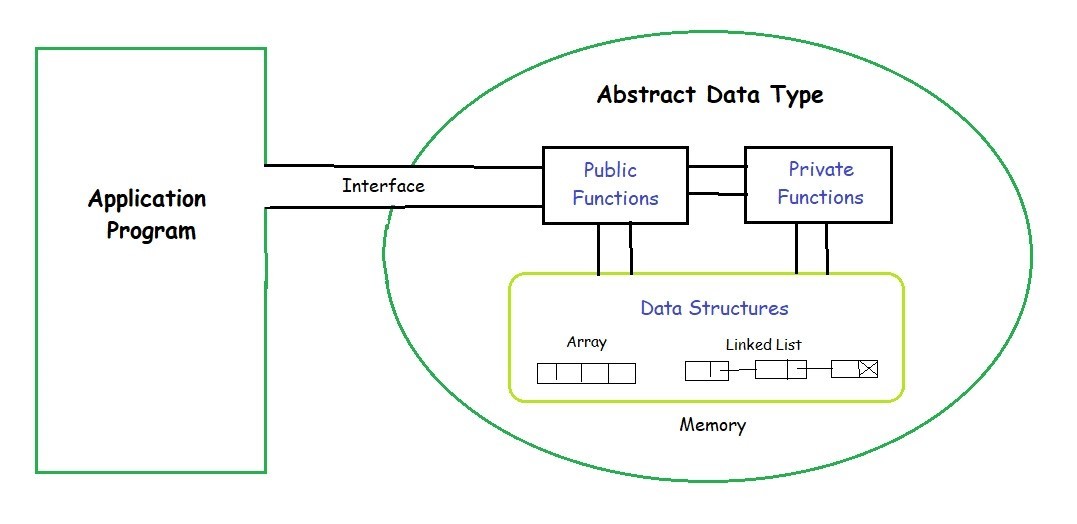
# 1. Python自定义数据结构概览
Python是一种拥有丰富内置数据结构的编程语言,如列表、元组、字典和集合等。这些内置数据结构是Python语言和其标准库的核心部分,为开发提供了极大的便利。然而,在解决特定问题时,内置数据结构可能无法完全满足需求。因此,开发者需要根据问题的特性,自行设计和实现更为合适的数据结构。自定义数据结构不仅能优化程序的性能,还能提高代码的可读性和可维护性。在本章,我们将对自定义数据结构进行概览,并探讨其在软件开发中的重要性。我们将介绍数据结构的基本概念、自定义数据结构的必要性以及如何构建自定义数据结构的基本思路。通过这章内容,读者将对Python中的自定义数据结构有更深入的理解。
# 2. Python中的基本数据结构
## 2.1 内置数据结构的理解与应用
### 2.1.1 列表和元组的使用场景
Python 中的列表(List)和元组(Tuple)是两种常用的有序集合,但它们在使用上有一些本质的区别。列表是可变的,意味着你可以修改列表中的元素,而元组是不可变的,一旦创建就不能被修改。这些特性使得列表和元组在不同的应用场景下有各自的优势。
列表的使用场景包括需要元素修改、频繁添加和删除元素的操作,以及在循环中构建集合。列表是动态的,可以随时添加新元素或删除现有元素,这使得它非常适合于实现栈、队列等数据结构。列表的这些特性在算法实现中尤其有用,例如,快速排序和归并排序中,列表用于存储临时数据。
```python
# 列表示例
fruits = ['apple', 'banana', 'cherry']
fruits.append('orange') # 添加元素
fruits.remove('banana') # 删除元素
```
元组通常用于存储不可变的数据集合,例如数据库记录、坐标点或者日期时间等。由于元组的不可变性,它们在需要保证数据不可被篡改的场景下非常有用。元组还可以被用作字典的键,这是因为在 Python 中,字典的键必须是不可变类型。
```python
# 元组示例
point = (10, 20)
date = (2023, 4, 1)
```
### 2.1.2 字典和集合的高级特性
字典(Dictionary)和集合(Set)是 Python 中两种非常有用的无序数据结构。字典存储键值对,可以实现快速查找,而集合主要用于存储唯一元素,用于快速测试元素的成员资格。
字典可以用于需要快速查找、更新和删除的场景。字典的键必须是唯一的,并且不可变,所以整数、字符串和元组都可以作为字典的键,但列表不可以。字典的常见用途包括实现关联数组、统计词频等。
```python
# 字典示例
person = {
'name': 'Alice',
'age': 30,
'city': 'New York'
}
person['email'] = '***' # 添加键值对
```
集合提供了强大的数学集合运算功能。它可以用来去除重复元素、进行成员资格测试,或者执行数学上的集合运算,如并集、交集、差集等。集合特别适合于处理需要去重的场景,例如,统计文章中不同单词的数量。
```python
# 集合示例
a = {1, 2, 3}
b = {3, 4, 5}
union_set = a | b # 并集
```
在设计和实现数据结构时,合理地选择内置数据结构,可以在很大程度上提高代码的效率和可读性。理解它们的使用场景和特性对于编写高效的 Python 程序至关重要。
# 3. 设计和实现自定义数据结构
## 3.1 自定义数据结构的设计原则
设计一个高效且易于维护的数据结构需要遵循一些基本原则,这些原则将帮助我们在实际开发中应对不同的问题和挑战。在本节中,我们将深入探讨封装性与抽象性、可维护性与扩展性的平衡。
### 3.1.1 封装性与抽象性的平衡
在软件开发中,封装性是面向对象编程的核心概念之一。通过封装,数据结构的内部实现细节对用户隐藏,只暴露必要的操作接口。这不仅有助于保护数据,还增强了代码的可读性和可维护性。然而,在设计数据结构时,我们也需要考虑抽象性。抽象性意味着提供一个高层次的视图,隐藏不必要的细节,使得用户可以专注于解决问题而不是实现细节。
**代码块示例与分析:**
```python
class Stack:
def __init__(self):
self._container = []
def push(self, item):
self._container.append(item)
def pop(self):
return self._container.pop()
def peek(self):
return self._container[-1]
def is_empty(self):
return len(self._container) == 0
def size(self):
return len(self._container)
```
**逻辑分析:**
上述代码实现了栈这一数据结构,通过`_container`属性封装了栈的内部表示,而外部通过`push`, `pop`, `peek`, `is_empty`, 和 `size`等方法与之交互。这样既隐藏了内部实现,又提供了清晰的接口,从而达到了封装与抽象的平衡。
### 3.1.2 可维护性与扩展性的考量
自定义数据结构的可维护性与扩展性是相辅相成的。一个设计良好的数据结构不仅便于维护,还需要考虑未来可能的变更需求。为了保证可维护性,代码应该清晰易读,并有适当的文档注释。扩展性则要求我们在设计时留有接口或抽象方法,便于后续添加新功能。
**代码块示例与分析:**
```python
class Node:
"""节点类,用于构建复杂的数据结构"""
def __init__(self, value):
self.value = value
self.next = None
class LinkedList:
"""链表类,通过节点构建"""
def __init__(self):
self.head = None
def append(self, value):
"""在链表末尾添加一个元素"""
if not self.head:
self.head = Node(value)
else:
current = self.head
while current.next:
current = current.next
current.next = Node(value)
```
**逻辑分析:**
在这个例子中,链表通过一个节点类`Node`实现,它将节点与链表功能分开,使得链表类`LinkedList`更易于理解和维护。同时,通过在链表类中添加`append`方法,允许用户扩展链表,体现了良好的扩展性。
## 3.2 栈和队列的实现
栈和队列是两种简单的数据结构,它们在很多场景下有着广泛的应用。栈是一种后进先出(LIFO)的数据结构,而队列是一种先进先出(FIFO)的数据结构。在本节中,我们将探讨这两种数据结构的原理和应用。
### 3.2.1 栈的原理与应用
栈作为一种数据结构,具有操作限制:只能在一端(栈顶)进行插入(push)和删除(pop)操作。这种限制使得栈非常适合实现算法,如括号匹配、深度优先搜索(DFS)等。
**代码块示例与分析:**
```python
class MyStack:
def __init__(self):
self._stack = []
def is_empty(self):
return len(self._stack) == 0
def push(self, item):
self._stack.append(item)
def pop(self):
if self.is_empty():
raise IndexError("Pop from an empty stack.")
return self._stack.pop()
def peek(self):
if self.is_empty():
return None
return self._stack[-1]
def size(self):
return len(self._stack)
```
**逻辑分析:**
上述代码实现了一个栈数据结构,通过`_stack`属性存储栈中的元素。`push`和`pop`操作分别实现压栈和出栈,`peek`查看栈顶元素而不移除它,`size`返回栈的大小。栈的实现很简单,但是它的后进先出的特性在很多算法中非常有用。
### 3.2.2 队列的原理与应用
与栈不同,队列是一种先进先出(FIFO)的数据结构,它允许在一端添加元素(入队),在另一端移除元素(出队)。队列的应用非常广泛,比如在任务调度、打印队列、缓冲区等场景。
**代码块示例与分析:**
```python
from collections import deque
class MyQueue:
def __init__(self):
self._queue = deque()
def is_empty(self):
return len(self._queue) == 0
def enqueue(self, item):
self._queue.append(item)
def dequeue(self):
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
**Python数据结构训练营**
本专栏深入探讨Python数据结构的奥秘,从基础到高级,帮助初学者掌握编程的基石。专栏涵盖了广泛的主题,包括:
* 数据结构秘籍:解锁初学者编程的奥秘
* 栈与队列:掌握数据流动的艺术
* 递归技巧:数据结构中的魔法武器
* 高级数据结构:树和图算法实现
* 二叉树算法实战:构建与遍历全攻略
* 哈希表与字典:掌握数据结构核心对比
* 高级数据结构指南:B树、堆和优先队列详解
* 链表深度解析:单向与双向链表的实现艺术
* 数据结构实战小结:选择合适结构解决实际问题
* 面试数据结构必备:常见面试题与解答
* 数据结构优化宝典:降低时间与空间复杂度
* 算法与数据结构:动态规划实战应用
* 算法与数据结构:贪心算法精解
* 算法与数据结构:回溯法解题全攻略
* 深入理解数据结构:内存管理与性能优化技巧
* 自定义数据结构实战:从理论到实践
通过深入浅出的讲解和丰富的代码示例,本专栏将帮助您构建坚实的数据结构基础,为您的编程之旅奠定坚实的基础。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
AMESim液压仿真秘籍:专家级技巧助你从基础飞跃至顶尖水平

# 摘要
AMESim液压仿真软件是工程师们进行液压系统设计与分析的强大工具,它通过图形化界面简化了模型建立和仿真的流程。本文旨在为用户提供AMESim软件的全面介绍,从基础操作到高级技巧,再到项目实践案例分析,并对未来技术发展趋势进行展望。文中详细说明了AMESim的安装、界面熟悉、基础和高级液压模型的建立,以及如何运行、分析和验证仿真结果。通过探索自定义组件开发、多学科仿真集成以及高级仿真算法的应用,本文
【高频领域挑战】:VCO设计在微波工程中的突破与机遇
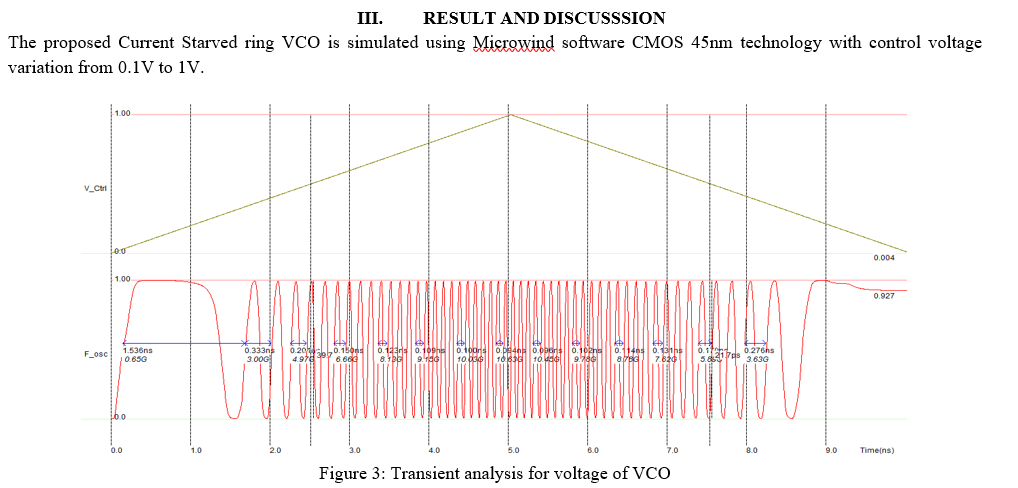
# 摘要
本论文深入探讨了压控振荡器(VCO)的基础理论与核心设计原则,并在微波工程的应用技术中展开详细讨论。通过对VCO工作原理、关键性能指标以及在微波通信系统中的作用进行分析,本文揭示了VCO设计面临的主要挑战,并提出了相应的技术对策,包括频率稳定性提升和噪声性能优化的方法。此外,论文还探讨了VCO设计的实践方法、案例分析和故障诊断策略,最后对VCO设计的创新思路、新技术趋势及未来发展挑战
实现SUN2000数据采集:MODBUS编程实践,数据掌控不二法门
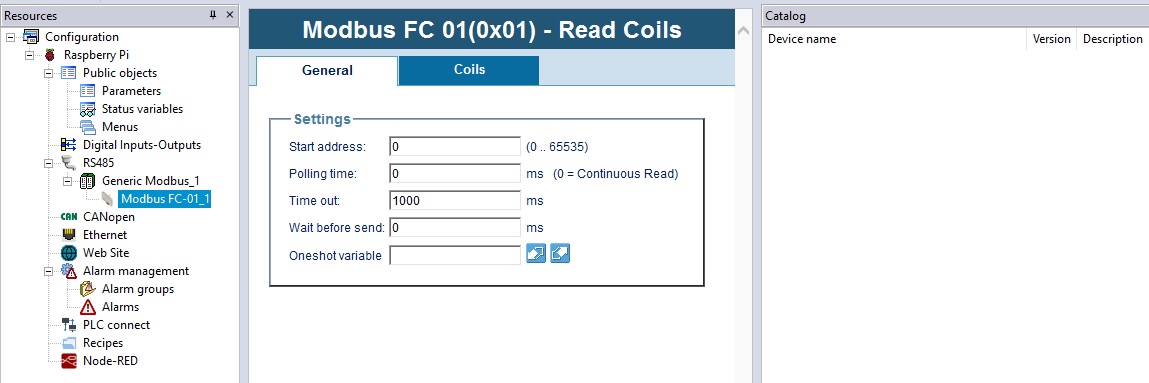
# 摘要
本文系统地介绍了MODBUS协议及其在数据采集中的应用。首先,概述了MODBUS协议的基本原理和数据采集的基础知识。随后,详细解析了MODBUS协议的工作原理、地址和数据模型以及通讯模式,包括RTU和ASCII模式的特性及应用。紧接着,通过Python语言的MODBUS库,展示了MODBUS数据读取和写入的编程实践,提供了具体的实现方法和异常管理策略。本文还结合SUN20
【性能调优秘籍】:深度解析sco506系统安装后的优化策略
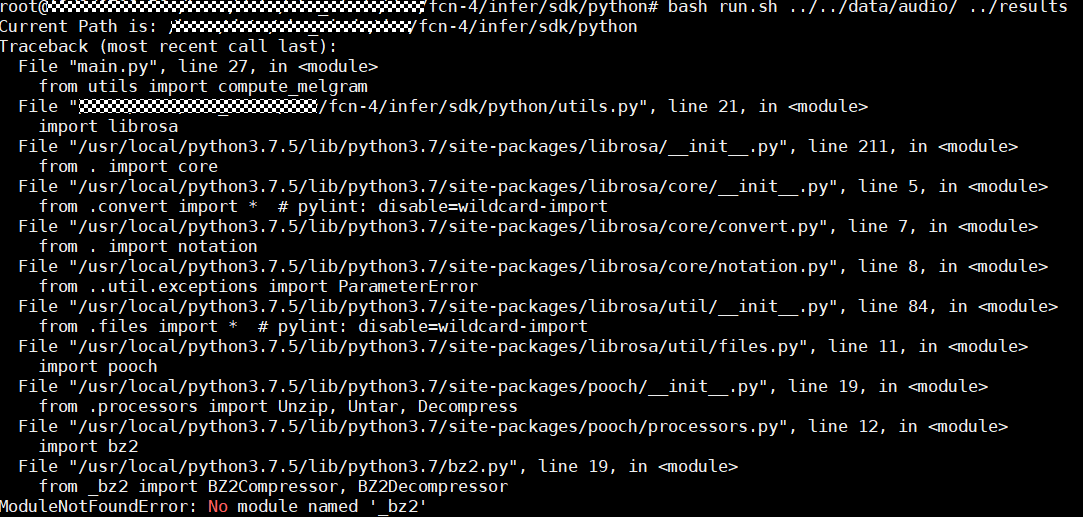
# 摘要
本文对sco506系统的性能调优进行了全面的介绍,首先概述了性能调优的基本概念,并对sco506系统的核心组件进行了介绍。深入探讨了核心参数调整、磁盘I/O、网络性能调优等关键性能领域。此外,本文还揭示了高级性能调优技巧,包括CPU资源和内存管理,以及文件系统性能的调整。为确保系统的安全性能,文章详细讨论了安全策略、防火墙与入侵检测系统的配置,以及系统审计与日志管理的优化。最后,本文提供了系统监控与维护的
网络延迟不再难题:实验二中常见问题的快速解决之道
# 摘要
网络延迟是影响网络性能的重要因素,其成因复杂,涉及网络架构、传输协议、硬件设备等多个方面。本文系统分析了网络延迟的成因及其对网络通信的影响,并探讨了网络延迟的测量、监控与优化策略。通过对不同测量工具和监控方法的比较,提出了针对性的网络架构优化方案,包括硬件升级、协议配置调整和资源动态管理等。
期末考试必备:移动互联网商业模式与用户体验设计精讲

# 摘要
移动互联网的迅速发展带动了商业模式的创新,同时用户体验设计的重要性日益凸显。本文首先概述了移动互联网商业模式的基本概念,接着深入探讨用户体验设计的基础,包括用户体验的定义、重要性、用户研究方法和交互设计原则。文章重点分析了移动应用的交互设计和视觉设计原则,并提供了设计实践案例。之后,文章转向移动商业模式的构建与创新,探讨了商业模式框架
【多语言环境编码实践】:在各种语言环境下正确处理UTF-8与GB2312

# 摘要
随着全球化的推进和互联网技术的发展,多语言环境下的编码问题变得日益重要。本文首先概述了编码基础与字符集,随后深入探讨了多语言环境所面临的编码挑战,包括字符编码的重要性、编码选择的考量以及编码转换的原则和方法。在此基础上,文章详细介绍了UTF-8和GB2312编码机制,并对两者进行了比较分析。此外,本文还分享了在不同编程语言中处理编码的实践技巧,
【数据库在人事管理系统中的应用】:理论与实践:专业解析

# 摘要
本文探讨了人事管理系统与数据库的紧密关系,分析了数据库设计的基础理论、规范化过程以及性能优化的实践策略。文中详细阐述了人事管理系统的数据库实现,包括表设计、视图、存储过程、触发器和事务处理机制。同时,本研究着重讨论了数据库的安全性问题,提出认证、授权、加密和备份等关键安全策略,以及维护和故障处理的最佳实践。最后,文章展望了人事管理系统的发展趋
【Docker MySQL故障诊断】:三步解决权限被拒难题
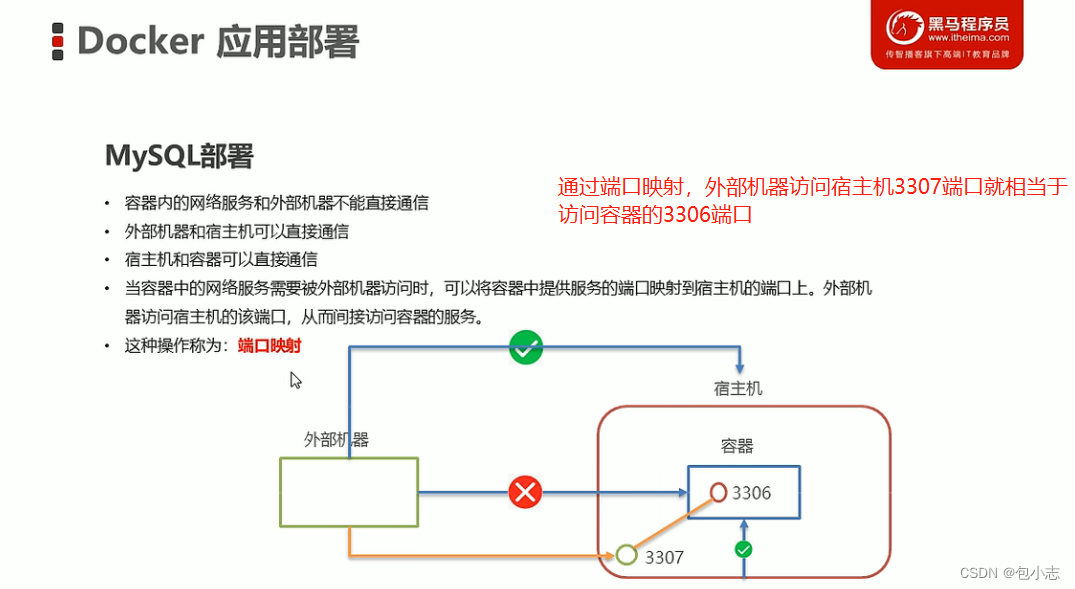
# 摘要
随着容器化技术的广泛应用,Docker已成为管理MySQL数据库的流行方式。本文旨在对Docker环境下MySQL权限问题进行系统的故障诊断概述,阐述了MySQL权限模型的基础理论和在Docker环境下的特殊性。通过理论与实践相结合,提出了诊断权限问题的流程和常见原因分析。本文还详细介绍了如何利用日志文件、配置检查以及命令行工具进行故障定位与修复,并探讨了权限被拒问题的解决策略和预防措施
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )