【Python初学者入门指南】:从零基础到掌握Python编程
发布时间: 2024-06-20 20:08:09 阅读量: 95 订阅数: 33 

java计算器源码.zip
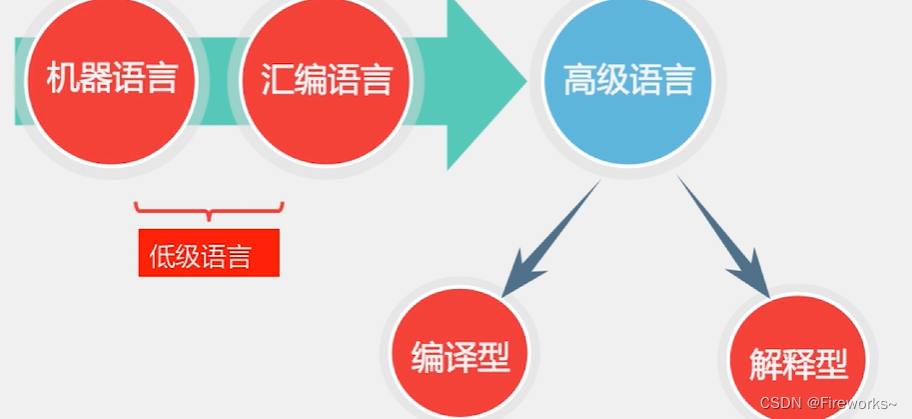
# 1. Python基础入门
Python是一种解释型、面向对象、高层次的编程语言。它以其简单易学、语法简洁、功能强大而著称,广泛应用于Web开发、数据分析、机器学习、人工智能等领域。
### 1.1 Python的特点
- **易于学习:**Python的语法简单明了,初学者易于理解和掌握。
- **面向对象:**Python支持面向对象编程,使代码结构清晰、可维护性强。
- **高层次:**Python提供了丰富的库和模块,可以简化编程任务,提高开发效率。
- **跨平台:**Python可以在Windows、Linux、macOS等多种操作系统上运行,无需重新编译。
# 2. Python编程基础
### 2.1 Python数据类型和变量
#### 2.1.1 数据类型概述
Python是一种动态类型语言,这意味着变量的数据类型在运行时确定。Python支持多种数据类型,包括:
- **数字类型:** 整数、浮点数、复数
- **序列类型:** 列表、元组、字符串
- **映射类型:** 字典
- **集合类型:** 集合、冻结集合
- **布尔类型:** True、False
- **None类型:** 表示空值
#### 2.1.2 变量的定义和使用
变量用于存储数据。要定义变量,使用赋值运算符(=)。例如:
```python
age = 25
name = "John Doe"
```
变量名可以是任何有效的Python标识符,但不能以数字开头。变量的值可以是任何Python数据类型。
### 2.2 Python流程控制
#### 2.2.1 条件语句
条件语句用于根据条件执行不同的代码块。Python中常用的条件语句是:
- **if语句:** 如果条件为真,则执行代码块。
- **elif语句:** 如果前面的条件为假,则检查下一个条件。
- **else语句:** 如果所有条件都为假,则执行代码块。
例如:
```python
age = 25
if age >= 18:
print("成年")
elif age >= 13:
print("青少年")
else:
print("儿童")
```
#### 2.2.2 循环语句
循环语句用于重复执行代码块。Python中常用的循环语句是:
- **for循环:** 遍历序列中的每个元素。
- **while循环:** 只要条件为真,就执行代码块。
例如:
```python
# for循环
fruits = ["apple", "banana", "cherry"]
for fruit in fruits:
print(fruit)
# while循环
count = 0
while count < 5:
print(count)
count += 1
```
#### 2.2.3 函数和参数传递
函数是可重用的代码块,可以接受参数并返回结果。要定义函数,使用`def`关键字。例如:
```python
def greet(name):
"""
向指定的人打招呼。
参数:
name:要打招呼的人的名字。
"""
print("你好," + name + "!")
```
要调用函数,使用函数名并传递参数。例如:
```python
greet("John Doe")
```
### 2.3 Python面向对象编程
#### 2.3.1 类和对象
面向对象编程(OOP)是一种编程范式,它将数据和方法组织成对象。在Python中,类是对象的蓝图,而对象是类的实例。
要定义类,使用`class`关键字。例如:
```python
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def greet(self):
print("你好," + self.name + "!")
```
要创建对象,使用`class`名称并传递参数。例如:
```python
person = Person("John Doe", 25)
```
#### 2.3.2 继承和多态
继承允许一个类从另一个类继承属性和方法。多态允许对象以不同的方式响应相同的调用。
例如:
```python
class Employee(Person):
def __init__(self, name, age, salary):
super().__init__(name, age)
self.salary = salary
def get_salary(self):
return self.salary
```
`Employee`类继承了`Person`类的属性和方法,并添加了`salary`属性和`get_salary()`方法。
# 3. Python实践应用
### 3.1 Python文件操作
#### 3.1.1 文件的读写操作
Python提供了丰富的文件操作函数,可以轻松地对文件进行读写操作。
**打开文件**
```python
with open("filename.txt", "mode") as file:
# 文件操作
```
其中,`mode`指定了文件的打开模式,常用的模式有:
* `r`:只读模式
* `w`:只写模式(覆盖原有内容)
* `a`:追加模式(在原有内容后追加)
* `r+`:读写模式
* `w+`:读写模式(覆盖原有内容)
* `a+`:读写模式(在原有内容后追加)
**读取文件**
```python
with open("filename.txt", "r") as file:
content = file.read()
```
`read()`方法可以读取文件的全部内容,并返回一个字符串。
**写入文件**
```python
with open("filename.txt", "w") as file:
file.write("Hello, world!")
```
`write()`方法可以向文件中写入内容。
**追加文件**
```python
with open("filename.txt", "a") as file:
file.write("Hello, world!")
```
`write()`方法也可以用于追加内容到文件。
#### 3.1.2 文件的权限和属性
Python提供了`os`模块来管理文件的权限和属性。
**获取文件权限**
```python
import os
file_path = "filename.txt"
permissions = os.stat(file_path).st_mode
```
`st_mode`属性包含文件的权限信息,可以使用`oct()`函数将其转换为八进制字符串。
**设置文件权限**
```python
import os
file_path = "filename.txt"
os.chmod(file_path, 0o755)
```
`chmod()`函数可以设置文件的权限,`0o755`表示文件所有者具有读、写、执行权限,组成员具有读、执行权限,其他用户具有读、执行权限。
**获取文件属性**
```python
import os
file_path = "filename.txt"
file_info = os.stat(file_path)
```
`os.stat()`函数返回一个`stat`对象,其中包含了文件的各种属性,如:
* `st_size`:文件大小
* `st_atime`:文件最后访问时间
* `st_mtime`:文件最后修改时间
* `st_ctime`:文件创建时间
# 4.1 Python正则表达式
正则表达式是一种强大的工具,用于匹配、搜索和替换文本中的模式。在Python中,正则表达式通过`re`模块提供。
### 4.1.1 正则表达式的基本语法和元字符
正则表达式使用一系列特殊字符和元字符来定义模式。最常用的元字符包括:
| 元字符 | 描述 |
|---|---|
| `.` | 匹配任何单个字符 |
| `*` | 匹配前面元素零次或多次 |
| `+` | 匹配前面元素一次或多次 |
| `?` | 匹配前面元素零次或一次 |
| `^` | 匹配字符串的开头 |
| `$` | 匹配字符串的结尾 |
| `[]` | 匹配方括号内的任何单个字符 |
| `[^]` | 匹配方括号内外的任何单个字符 |
| `|` | 匹配多个模式中的任何一个 |
### 4.1.2 正则表达式的应用
正则表达式有广泛的应用,包括:
- **文本处理:** 查找和替换文本中的模式,验证输入,提取数据
- **数据验证:** 检查电子邮件地址、电话号码和邮政编码的格式
- **文本分析:** 识别语言、情绪和主题
- **代码分析:** 查找语法错误和代码重复
**代码示例:**
```python
import re
# 匹配所有以"a"开头的单词
pattern = r"^a\w+"
# 在字符串中搜索匹配项
text = "apple banana cherry"
match = re.search(pattern, text)
# 打印匹配项
if match:
print(match.group())
```
**逻辑分析:**
- `re.search(pattern, text)`:使用`re`模块的`search()`函数在`text`中搜索与`pattern`匹配的第一个匹配项。
- `match.group()`:获取匹配项的内容。
**参数说明:**
- `pattern`:要匹配的正则表达式模式。
- `text`:要搜索的字符串。
# 5.1 Python爬虫项目
### 5.1.1 爬虫的基本原理
**爬虫的概念**
爬虫,又称网络爬虫或网络蜘蛛,是一种自动化程序,用于从互联网上收集和提取信息。爬虫通过模拟浏览器的行为,访问和解析网页,从中提取结构化数据。
**爬虫的工作原理**
爬虫的工作原理通常包括以下步骤:
1. **获取URL列表:**爬虫从一个初始URL列表开始,其中包含要爬取的网页地址。
2. **下载网页:**爬虫向目标网页发送HTTP请求,下载网页的HTML代码。
3. **解析网页:**爬虫使用HTML解析器解析下载的网页,提取结构化数据,如文本、图像和链接。
4. **提取数据:**爬虫根据预定义的规则从解析后的网页中提取所需数据。
5. **存储数据:**爬虫将提取的数据存储在数据库、文件或其他存储介质中。
6. **跟踪已爬取的URL:**爬虫维护一个已爬取URL的列表,以避免重复爬取。
7. **发现新URL:**爬虫从已爬取的网页中提取新的URL,并将其添加到待爬取的URL列表中。
**爬虫的类型**
爬虫有多种类型,根据其目的和功能进行分类:
- **通用爬虫:**爬取互联网上所有或大多数网页,用于创建搜索引擎索引。
- **垂直爬虫:**专注于特定主题或领域的爬虫,如新闻、电子商务或社交媒体。
- **增量爬虫:**定期爬取网站的更新或更改,以保持数据最新。
- **深层爬虫:**深入爬取网站,访问隐藏或难以访问的网页。
### 5.1.2 爬虫工具和框架
**爬虫工具**
有许多可用的爬虫工具,可以简化爬虫开发过程:
- **Beautiful Soup:**一个流行的HTML解析库,用于从网页中提取数据。
- **Requests:**一个HTTP库,用于发送HTTP请求和下载网页。
- **Scrapy:**一个功能强大的爬虫框架,提供广泛的爬虫功能。
- **Selenium:**一个用于自动化Web浏览器的工具,允许爬虫与交互式网页进行交互。
**爬虫框架**
爬虫框架提供了预先构建的组件和功能,简化了爬虫开发:
- **scrapy:**一个流行的爬虫框架,提供了一个可扩展的架构和丰富的功能。
- **Colly:**一个轻量级的爬虫框架,专注于并发和可扩展性。
- **Playwright:**一个无头浏览器,允许爬虫与现代Web应用程序交互。
- **Puppeteer:**一个无头浏览器,专门用于Node.js,提供强大的Web自动化功能。
**爬虫最佳实践**
遵循最佳实践对于开发高效和道德的爬虫至关重要:
- **尊重robots.txt:**遵守网站的robots.txt文件,避免爬取被禁止的页面。
- **限制爬虫速度:**调整爬虫的爬取速度,以避免对目标网站造成过度负载。
- **处理异常:**处理爬虫过程中可能遇到的异常情况,如网络错误和解析错误。
- **使用代理:**使用代理服务器来隐藏爬虫的IP地址,避免被网站封锁。
- **遵循法律法规:**遵守与爬虫相关的法律法规,避免侵犯隐私或版权。
# 6. Python职业发展
### 6.1 Python职业发展路径
随着Python在各行各业的广泛应用,Python开发人员的需求也日益增加。Python职业发展路径主要分为两大方向:
- **Python开发工程师**:专注于使用Python进行软件开发、系统集成和维护。要求具备扎实的编程基础、对Python生态系统的深入了解以及良好的问题解决能力。
- **数据科学家**:利用Python进行数据分析、机器学习和人工智能开发。要求具备统计学、机器学习和Python编程的扎实基础,以及良好的数据处理和分析能力。
### 6.2 Python学习资源和社区
为了持续提升Python技能,以下是一些有价值的学习资源和社区:
- **在线课程和教程**:Coursera、Udemy、edX等平台提供丰富的Python课程和教程,涵盖从基础到高级的各种主题。
- **社区论坛和交流平台**:Stack Overflow、Reddit等社区提供了一个活跃的平台,可以与其他Python开发人员交流、提问和获取帮助。
- **官方文档和社区贡献**:Python官方文档提供了全面的语言参考和教程,而社区贡献的项目和库扩展了Python的生态系统,提供了丰富的学习和实践机会。
通过持续学习和参与Python社区,可以不断提升技能,拓展职业发展道路。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Python 简单代码库,一个专为 Python 初学者和经验丰富的开发人员设计的全面指南。从基础语法到高级算法和云计算,我们涵盖了广泛的主题,帮助您掌握 Python 编程的方方面面。
本专栏提供了一系列深入的文章,涵盖 Python 的核心概念,包括数据结构、数据操作、可视化和算法。我们还探讨了 Python 在 Web 开发、机器学习和云计算中的实际应用。通过循序渐进的教程和代码示例,我们将指导您从零基础到成为一名熟练的 Python 程序员。
无论您是刚开始学习 Python,还是正在寻找提高技能的方法,Python 简单代码库都是您的理想资源。我们的文章由经验丰富的专家撰写,旨在为您提供清晰、易于理解的指导。加入我们,踏上掌握 Python 编程之旅,释放其无限的可能性。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【MATLAB中MSK调制的艺术】:差分编码技术的优化与应用

# 摘要
MSK调制技术作为现代通信系统中的一种关键调制方式,与差分编码相结合能够提升信号传输的效率和抗干扰能力。本文首先介绍了MSK调制技术和差分编码的基础理论,然后详细探讨了差分编码在MSK调制中的应用,包括MSK调制器设计与差分编码
从零开始学习RLE-8:一文读懂BMP图像解码的技术细节

# 摘要
本文从编码基础与图像格式出发,深入探讨了RLE-8编码技术在图像处理领域的应用。首先介绍了RLE-8编码机制及其在BMP图像格式中的应用,然后详细阐述了RLE-8的编码原理、解码算法,包括其基本概念、规则、算法实现及性能优化策略。接着,本文提供了BMP图像的解码实践指南,解析了文件结构,并指导了RLE-8解码器的开发流程。文章进一步分析了RLE-8在图像压缩中的优势和适用场景,以及其在高级图像处
Linux系统管理新手入门:0基础快速掌握RoseMirrorHA部署
# 摘要
本文首先介绍了Linux系统管理的基础知识,随后详细阐述了RoseMirrorHA的理论基础及其关键功能。通过逐步讲解Linux环境下RoseMirrorHA的部署流程,包括系统要求、安装、配置和启动,本文为系统管理员提供了一套完整的实施指南。此外,本文还探讨了监控、日常管理和故障排查等关键维护任务,以及高可用场景下的实践和性能优化策略。最后,文章展望了Linux系统管理和R
用户体验:华为以用户为中心的设计思考方式与实践
# 摘要
用户体验在当今产品的设计和开发中占据核心地位,对产品成功有着决定性影响。本文首先探讨了用户体验的重要性及其基本理念,强调以用户为中心的设计流程,涵盖用户研究、设计原则、原型设计与用户测试。接着,通过华为的设计实践案例分析,揭示了用户研究的实施、用户体验的改进措施以及界面设计创新的重要性。此外,本文还探讨了在组织内部如何通过
【虚拟化技术】:smartRack资源利用效率提升秘籍
# 摘要
本文全面介绍了虚拟化技术,特别是smartRack平台在资源管理方面的关键特性和实施技巧。从基础的资源调度理论到存储和网络资源的优化,再到资源利用效率的实践技巧,本文系统阐述了如何在smartRack环境下实现高效的资源分配和管理。此外,本文还探讨了高级资源管理技巧,如资源隔离、服务质量(QoS)保障以及性能分析与瓶颈诊
【聚类算法选型指南】:K-means与ISODATA对比分析
# 摘要
本文系统地介绍了聚类算法的基础知识,着重分析了K-means算法和ISODATA算法的原理、实现过程以及各自的优缺点。通过对两种算法的对比分析,本文详细探讨了它们在聚类效率、稳定性和适用场景方面的差异,并展示了它们在市场细分和图像分割中的实际应用案例。最后,本文展望了聚类算法的未来发展方向,包括高维数据聚类、与机器学习技术的结合以及在新兴领域的应用前景。
# 关
小米mini路由器序列号恢复:专家教你解决常见问题

# 摘要
本文对小米mini路由器序列号恢复问题进行了全面概述。首先介绍了小米mini路由器的硬件基础,包括CPU、内存、存储设备及网络接口,并探讨了固件的作用和与硬件的交互。随后,文章转向序列号恢复的理论基础,阐述了序列号的重要性及恢复过程中的可行途径。实践中,文章详细描述了通过Web界面和命令行工具进行序列号恢复的方法。此外,本文还涉及了小米mini路由器的常见问题解决,包括
深入探讨自然辩证法与软件工程的15种实践策略

# 摘要
自然辩证法作为哲学原理,为软件工程提供了深刻的洞见和指导原则。本文探讨了自然辩证法的基本原理及其在软件开发、设计、测试和管理中的应用。通过辩证法的视角,文章分析了对立统一规律、质量互变规律和否定之否定原则在软件生命周期、迭代优化及软件架构设计中的体现。此外,还讨论了如何将自然辩证法应用于面向对象设计、设计模式选择以及测试策略的制定。本文强调了自然辩证法在促进软
【自动化控制】:PRODAVE在系统中的关键角色分析

# 摘要
本文对自动化控制与PRODAVE进行了全面的介绍和分析,阐述了PRODAVE的基础理论、应用架构以及在自动化系统中的实现。文章首先概述了PRODAVE的通信协议和数据交换模型,随后深入探讨了其在生产线自动化、能源管理和质量控制中的具体应用。通过对智能工厂、智能交通系统和智慧楼宇等实际案例的分析,本文进一步揭示了PR
【VoIP中的ITU-T G.704应用】:语音传输最佳实践的深度剖析

# 摘要
本文系统地分析了ITU-T G.704协议及其在VoIP技术中的应用。文章首先概述了G.704协议的基础知识,重点阐述了其关键特性,如帧结构、时间槽、信道编码和信号传输。随后,探讨了G.704在保证语音质量方面的作用,包括误差检测控制机制及其对延迟和抖动的管理。此外,文章还分析了G.704
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )