高级应用:在Matlab中实现四元数的指数函数
发布时间: 2024-04-06 20:55:54 阅读量: 132 订阅数: 35 

简单四元数和 3D 旋转函数库:四元数代数和旋转矩阵的函数库。-matlab开发
# 1. 理解四元数
四元数是一种数学结构,由实部和三个虚部组成,通常表示为$q = a + bi + cj + dk$,其中$a, b, c, d$为实数,而$i, j, k$为虚数单位,满足$i^2 = j^2 = k^2 = ijk = -1$。四元数可以用来表示旋转、姿态等复杂的数学概念,在许多应用中有着重要的作用。
### 1.1 什么是四元数?
四元数是由爱尔兰数学家William Rowan Hamilton于19世纪提出的,它扩展了复数的概念,可以看作是复数的推广。一个四元数$q$可以表示为一个实部和三个虚部的线性组合,其中实部代表了数值部分,虚部代表了空间旋转部分。
### 1.2 四元数的基本性质
四元数具有加法、减法、乘法、除法等运算,其中乘法运算非常重要,因为它能够表示旋转、姿态变换等复杂的数学操作。四元数的乘法不满足交换律,即$ab \neq ba$,但满足结合律,即$(ab)c = a(bc)$。
### 1.3 四元数的代数运算
四元数拥有共轭、模、逆等代数运算,共轭表示虚部取负,模表示四元数的长度,逆表示四元数的倒数。这些代数运算对于四元数的应用至关重要,能够帮助我们解决实际问题中的旋转、姿态变换等计算需求。
# 2. 四元数的指数函数简介
- 2.1 指数函数在数学中的基本概念
- 2.2 四元数的指数函数定义
- 2.3 指数函数在Matlab中的应用
在数学中,指数函数是一种常见且重要的函数类型,通常用 $e^x$ 表示,其中 $e$ 是自然对数的底数。指数函数在数学、物理、工程等领域有着广泛的应用,能够描述增长速度、衰减速度等问题。
而在四元数的领域,我们也可以定义类似于实数域的指数函数,用于四元数的指数运算。四元数是一种具有四个维度的数学结构,通常表示成 $q = a + bi + cj + dk$,其中 $a, b, c, d$ 分别是四个实数,而 $i, j, k$ 则是满足类似于复数域中 $i^2 = j^2 = k^2 = ijk = -1$ 的关系。
具体来说,四元数的指数函数定义如下:
假设四元数 $q = a + bi + cj + dk$ 的模长为 $|q| = \sqrt{a^2 + b^2 + c^2 + d^2}$,则四元数的指数函数 $e^q$ 可以表示为:
e^q = e^a(\cos |v| + v\frac{\sin |v|}{|v|})
其中 $v = bi + cj + dk$,$e^a$ 是实数域的指数函数。
在Matlab中,我们可以利用这一定义来实现四元数的指数函数,为实现更复杂的四元数运算提供基础支持。在接下来的章节中,我们将介绍如何在Matlab中应用四元数的指数函数以及相应的实现方法。
# 3. Matlab基础
在这一章中,我们将介绍Matlab的基础知识,包括环境搭建、基本

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面介绍了 MATLAB 中四元数的基本操作方法,涵盖了四元数的定义、构造、乘法、共轭、模长计算、单位化、取幂、指数函数、对数运算、旋转矩阵转换、坐标变换、插值、微分、积分、特征值、特征向量计算、最小二乘法、解方程、优化计算和机器人控制中的应用。通过深入浅出的讲解和丰富的示例,本专栏将帮助读者掌握四元数在 MATLAB 中的各种操作技巧,为其在计算机图形学、机器人学、计算机视觉等领域的应用提供有力支持。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【PCI Geomatica初学者必备】:一步到位的安装与配置指南
# 摘要
PCI Geomatica是一款先进的遥感和地理信息系统软件,广泛应用于地理数据处理和分析。本文旨在为用户提供一份详尽的PCI Geomatica操作指南,包括系统要求分析、安装前的准备、详细的安装步骤、软件配置要点以及实践操作的入门和进阶分析。特别地,文章还提供了性能优化和故障排除的实用技巧,确保用户能够高效使用PCI Geomatica并解决
【SERDES芯片全解析】:揭秘高速数据传输的核心技术

# 摘要
SERDES(串行化/并行化收发器)芯片是现代高速数字通信系统的关键组件,它负责在高数据传输速率下进行信号的串行化与并行化转换。本文首先介绍了SERDES芯片的基本概念和工作原理,然后深入分析了其在信号完整性、时钟数据恢复(CDR)和通道编码与解码方面的关键技术。在芯片设计与实现方面,本文探讨了物理层设计、逻辑层设计以及电气特性等多
掌握i386处理器技术:从基础到优化的7大实战技巧

# 摘要
本文全面介绍了i386处理器的技术特性及其在软件开发中的应用。文章首先回顾了i386架构的发展历史和主要特点,然后深入探讨了其寄存器和内存管理机制,包括实模式与保护模式下的内存管理。接着,本文转向系统编程基础,阐述了i386汇编语言的基本语法和中断处理机制,以及系统调用的实现。在此基础上,文章进一步分析了在i386平台上进行C语言开发和多任务编程的技巧。此外,本文还分享了i386性能优化的原则、方法和代码层面的优化实践。最后,文章展望了i386技术在嵌入
IBM x3650 RAID管理工具:让RAID阵列高效运作的秘诀
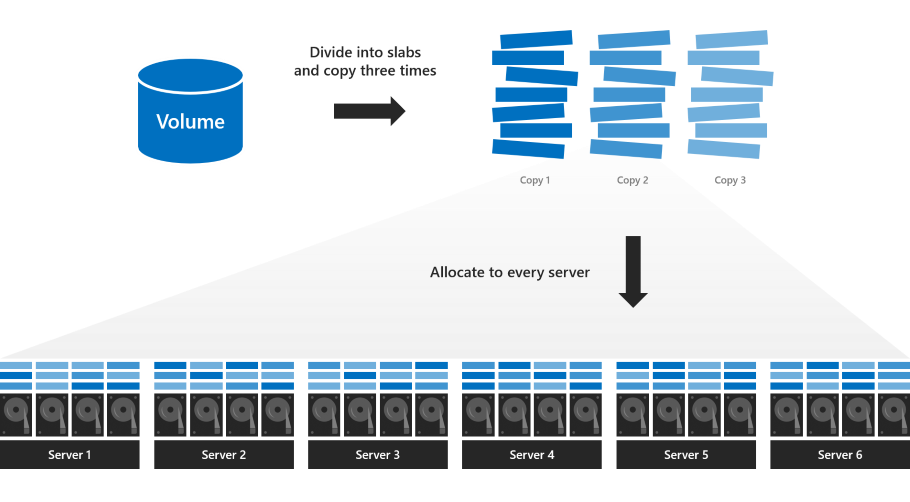
# 摘要
本文深入探讨了RAID技术及其在IBM x3650服务器上的应用。首先,介绍了RAID技术的基础知识和IBM x3650服务器的概述。随后,详细分析了IBM x3650的RAID配置,包括不同RAID级别、控制器管理界面及配置步骤。文中还实战演示了RAID管理工具的应用,涵盖了创建、监控、备份与恢复RAID阵列的技
云基础设施管理:云迁移与云治理策略全攻略
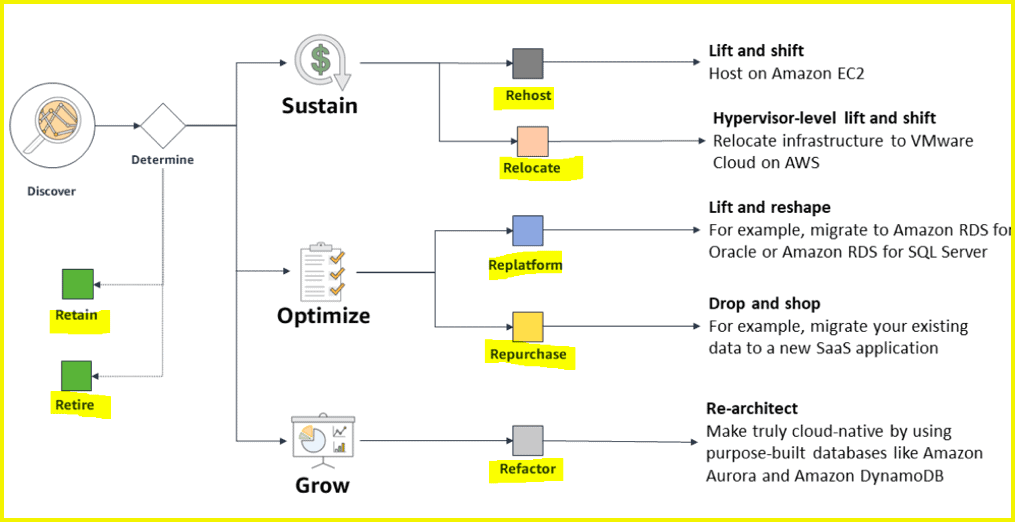
# 摘要
随着信息技术的快速发展,云基础设施管理已成为企业和学术研究的热点领域。本文旨在综述云迁移的理论基础和实践技巧,并探讨云治理的核心原则与策略。文章首先介绍了云迁移的基本概念、模型选择及实践步骤,包括数据和应用迁移、性能优化与故障排除。随后,文中阐述了云治理的框架、合规性与审计、以及成本管理优化策略。通过案例研究,本文分析了成功的云迁移和治理策略的应用,总结了经验教训。最后,文章展望了云基础设施管理的未来趋势,
【工作场所革命】:DP Alt Mode在日常应用中的奇迹

# 摘要
DP Alt Mode技术允许通过USB Type-C接口传输显示信号,为终端设备提供了一种替代传统显示端口的解决方案。本文首先介绍了DP Alt Mode的基本概念和工作原理,并与其他相关技术进行了比较。随后,文中探讨了该技术在硬件层面
【应用与挑战】:Virtex-5 FPGA在通信系统中的深入研究

# 摘要
本文综述了Virtex-5 FPGA在现代通信系统中的应用,详细介绍了其硬件架构,包括可编程逻辑单元(CLB)、输入/输出单元(IOB)和数字信号处理单元(DSP)。进一步探讨了Virtex-5 FPGA在物理层、网络层和传输层的具体应用实践,以及其编程与开发面临的挑战,特
随机数生成器测试原理大揭秘:TestU01库背后的算法深度探究

# 摘要
随机数生成器在科学计算、密码学、模拟与仿真等领域扮演着重要角色。本文介绍了TestU01库,这是一个广泛使用的随机数测试工具,具备多种测试套件,能够对各种随机数生成器进行详尽的评估。首先概述了TestU01的架构、安装和基础使用方法,然后深入探讨了其核心测试
海泰克系统高效网络配置:专业步骤助你实现快速连接

# 摘要
本文详细介绍了海泰克系统及其网络配置的需求分析,深入探讨了网络基础知识,包括通信协议、硬件组件以及配置前的准备工作。文章进一步阐述了海泰克系统网络配置的实施步骤,涵盖基本和高级网络功能的配置以及性能监控与故障排查。此外,还着重讨论了网络配置的优化、安全加固措施以及自动化管理与脚本配置的有效方法。通过案例分析,本文展示了海泰克系统网络配置的实际应用,并提供了问题解决策略和宝贵经验分享。
# 关键字
海泰克系统;网络配置;通信协议;性能优化;网络安全;自
MBIM协议在物联网中的角色:探讨其与IoT技术的融合之道

# 摘要
MBIM协议作为一种专为移动宽带设备设计的通信协议,在物联网技术领域扮演着关键角色。本文首先概述了MBIM协议的基础知识和物联网的核心要素,进而探讨了MBIM与物联网技术融合的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )