Java深度学习库指南:TensorFlow与DL4J对比解析,选型不再难
发布时间: 2024-08-30 01:24:17 阅读量: 133 订阅数: 49 
# 1. 深度学习与Java的结合
在当今IT领域,深度学习与Java的结合已经成为了一个不可忽视的趋势。一方面,Java作为企业级应用开发的首选语言,其稳定性和易维护性得到了广泛的认可。另一方面,深度学习作为机器学习的一个重要分支,其在图像识别、语音识别、自然语言处理等领域展现出的强大能力,使得它在各行各业得到了广泛的应用。
然而,深度学习与Java的结合并不是没有挑战的。Java在性能上可能不如C++和Python,但它强大的跨平台能力、丰富的社区资源和成熟的生态系统,使得它在处理大规模、复杂的企业级应用时,具有独特的优势。
在这一章节中,我们将深入探讨深度学习与Java的结合,分析其优势、挑战以及在实际应用中的案例。我们将从Java在深度学习中的角色、深度学习与Java的集成方法,以及Java在深度学习中的应用场景等方面进行详细阐述。通过这一章节的学习,读者将能够对深度学习与Java的结合有一个全面深入的理解。
# 2. TensorFlow核心概念与应用
## 2.1 TensorFlow的架构和设计理念
### 2.1.1 TensorFlow计算图基础
TensorFlow的计算图是其核心概念之一,它是一个有向图(Directed Graph),用于描述数学运算。计算图由节点(Nodes)和边(Edges)组成,节点通常表示施加数学运算的单元,而边表示节点间传递的多维数组数据,也就是张量(Tensors)。在TensorFlow中,所有的计算都是在创建计算图之后进行的,你可以构建图的静态定义(静态图),也可以边运行边定义计算图(动态图)。
为了更好地理解这一概念,我们可以通过一个简单的例子来说明:
```python
import tensorflow as tf
# 定义两个常量节点
a = tf.constant(2)
b = tf.constant(3)
# 定义一个加法操作节点
addition = tf.add(a, b)
# 创建一个Session来运行图
with tf.Session() as sess:
# 运行计算图中的加法节点
result = sess.run(addition)
print(result) # 输出:5
```
在这段代码中,我们首先导入了TensorFlow库,然后创建了两个常量节点`a`和`b`,并定义了一个加法操作节点`addition`。最后,我们通过创建一个`Session`对象来运行这个计算图,并得到结果。
### 2.1.2 张量操作和神经网络构建
张量(Tensor)是多维数组的泛化,它在TensorFlow中是所有数据交换的基本单位。张量的维度称为rank,一个有N维的张量,其rank为N。例如,一个一维数组是一个rank为1的张量,一个矩阵是一个rank为2的张量。
在神经网络构建中,我们通常使用张量来表示网络中的数据和权重。在TensorFlow中,我们可以利用张量操作来构建复杂的神经网络结构。
下面是一个构建简单的神经网络的例子:
```python
import tensorflow as tf
# 定义输入层的张量
x = tf.placeholder(tf.float32, shape=[None, 784]) # 假设数据是784维的
y = tf.placeholder(tf.float32, shape=[None, 10]) # 假设输出是10维的
# 定义权重和偏置
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
# 构建模型
prediction = tf.nn.softmax(tf.matmul(x, W) + b)
# 定义损失函数和优化器
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=prediction))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.5).minimize(loss)
# 创建一个Session来运行图
with tf.Session() as sess:
# 初始化全局变量
sess.run(tf.global_variables_initializer())
# 进行训练...
# 通过多次迭代更新W和b
```
在这段代码中,我们首先定义了输入层的张量`x`和输出层的张量`y`。然后创建了权重张量`W`和偏置张量`b`,并构建了模型`prediction`。接着定义了损失函数,并使用了梯度下降优化器来优化模型参数。最后,我们初始化了全局变量并开始训练模型。
## 2.2 TensorFlow的高级特性
### 2.2.1 Estimators和Datasets的使用
TensorFlow提供了高阶API Estimators,使得构建模型和进行训练变得更加简单。Estimator利用Datasets API来处理数据,并可以轻松地进行模型的训练、评估和预测。使用Estimators可以简化很多底层细节的处理,让开发者可以更加专注于模型设计本身。
为了说明Estimators的使用,我们看一个简单的线性回归例子:
```python
import tensorflow as tf
def input_fn():
# 加载数据集并返回一个Dataset对象
dataset = tf.data.Dataset.from_tensor_slices((X_train, y_train))
return dataset
# 定义特征列,这里以连续特征为例
feature_columns = [tf.feature_column.numeric_column(key=str(k)) for k in range(X_train.shape[1])]
# 创建线性回归Estimator模型
estimator = tf.estimator.LinearClassifier(feature_columns=feature_columns)
# 训练模型
estimator.train(input_fn=input_fn, steps=1000)
# 评估模型
result = estimator.evaluate(input_fn=input_fn)
print(result)
```
在这个例子中,我们首先定义了一个输入函数`input_fn`来加载数据集并返回一个`Dataset`对象。然后定义了特征列`feature_columns`,并通过`LinearClassifier`创建了Estimator模型。最后,我们使用`train`方法来训练模型,并通过`evaluate`方法评估模型。
### 2.2.2 分布式训练和模型部署
TensorFlow支持分布式训练,这意味着你可以利用多台机器共同训练一个模型,从而加速训练过程。TensorFlow的分布式训练是在一个集群上运行,其中包含一个或多个任务(多个工作进程)和服务器。
模型部署是将训练好的模型应用到实际生产环境中。TensorFlow提供了TensorFlow Serving,这是一个灵活、高性能的机器学习模型服务系统,专门用于管理机器学习模型并提供模型服务。
下面是一个简化的分布式训练例子:
```python
import tensorflow as tf
# 配置集群
cluster_spec = tf.train.ClusterSpec({
'worker': ['localhost:2222', 'localhost:2223', 'localhost:2224'],
'ps': ['localhost:2225', 'localhost:2226']
})
# 与集群中的某个任务建立会话
with tf.train.MonitoredTrainingSession(master=cluster_spec.as_cluster_def(), is_chief=True) as sess:
# 在这里执行模型的训练操作...
# 使用TensorFlow Serving来部署模型
```
在这个例子中,我们首先配置了一个集群`cluster

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探索了 Java 中广泛使用的机器学习算法库,为开发人员提供了全面的指南。从选择最佳库到深入了解特定算法,再到优化性能和处理分布式数据,本专栏涵盖了机器学习开发的各个方面。通过深入浅出的解释、代码示例和实践案例分析,本专栏旨在帮助开发人员掌握 Java 中机器学习算法的原理、实现和应用。无论是初学者还是经验丰富的从业者,本专栏都提供了宝贵的见解和实用技巧,使开发人员能够构建高效且准确的机器学习模型。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Xshell与Vmware交互解析】:打造零故障连接环境的5大实践

# 摘要
本文旨在探讨Xshell与Vmware的交互技术,涵盖远程连接环境的搭建、虚拟环境的自动化管理、安全交互实践以及高级应用等方面。首
火电厂资产管理系统:IT技术提升资产管理效能的实践案例
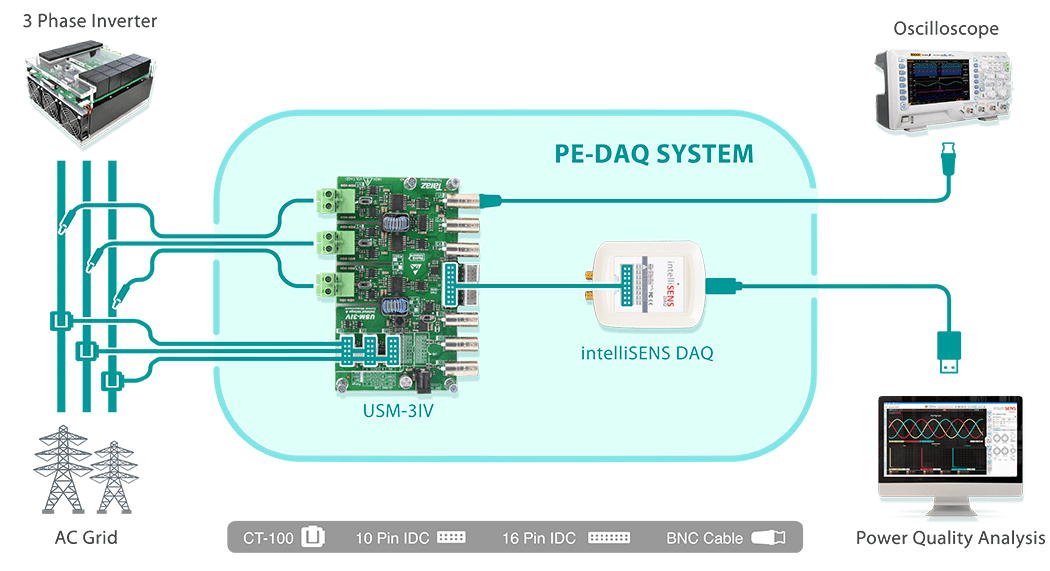
# 摘要
本文深入探讨了火电厂资产管理系统的背景、挑战、核心理论、实践开发、创新应用以及未来展望。首先分析了火电厂资产管理的现状和面临的挑战,然后介绍了资产管理系统的理论框架,包括系统架构设计、数据库管理、流程优化等方面。接着,本文详细描述了系统的开发实践,涉及前端界面设计、后端服务开发、以及系统集成与测试。随后,文章探讨了火电厂资产管理系统在移动端应用、物联网技术应用以及
Magento多店铺运营秘籍:高效管理多个在线商店的技巧
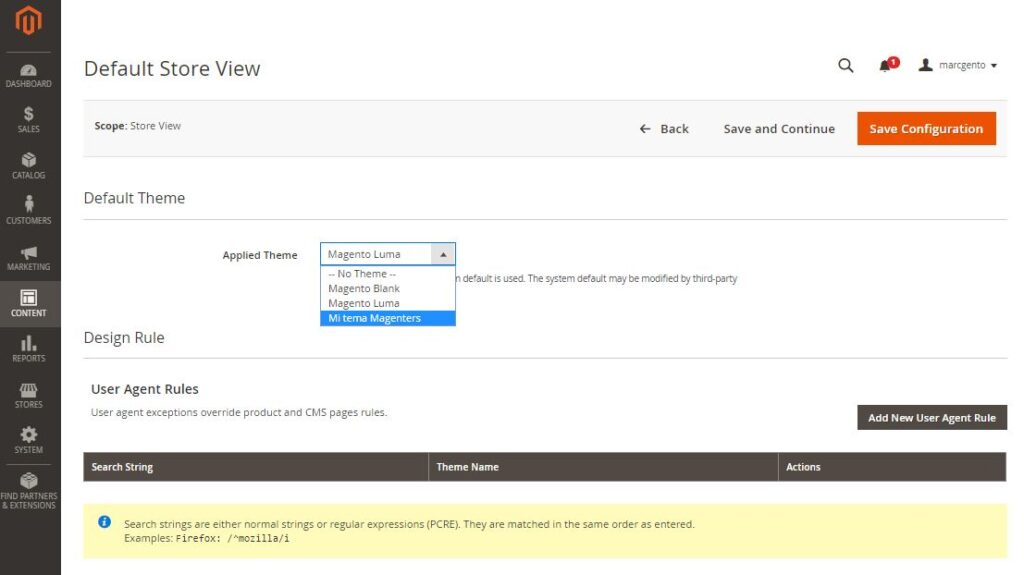
# 摘要
随着电子商务的蓬勃发展,Magento多店铺运营成为电商企业的核心需求。本文全面概述了Magento多店铺运营的关键方面,包括后台管理、技术优化及运营实践技巧。文中详细介绍了店铺设置、商品和订单管理,以及客户服务的优化方法。此外,本文还探讨了性能调优、安全性增强和第三方集成技术,为实现有效运营提供了技术支撑。在运营实践方面,本文阐述了有效的营销
【实战攻略】MATLAB优化单脉冲测角算法与性能提升技巧

# 摘要
本文全面探讨了MATLAB环境下优化单脉冲测角算法的过程、技术及应用。首先介绍了单脉冲测角算法的基础理论,包括测角原理、信号处理和算法实现步骤。其次,文中详细阐述了在MATLAB平台下进行算法性能优化的策略,包括代码加速、并行计算和G
OPA656行业案例揭秘:应用实践与最佳操作规程

# 摘要
本文深入探讨了OPA656行业应用的各个方面,涵盖了从技术基础到实践案例,再到操作规程的制定与实施。通过解析OPA656的核心组件,分析其关键性能指标和优势,本文揭示了OPA656在工业自动化和智慧城市中的具体应用案例。同时,本文还探讨了OPA656在特定场景下的优化策略,包括性能
【二极管热模拟实验操作教程】:实验室中模拟二极管发热的详细步骤

# 摘要
本文通过对二极管热模拟实验基础的研究,详细介绍了实验所需的设备与材料、理论知识、操作流程以及问题排查与解决方法。首先,文中对温度传感器的选择和校准、电源与负载设备的功能及操作进行了说明,接着阐述了二极管的工作原理、PN结结构特性及电流-电压特性曲线分析,以及热效应的物理基础和焦耳效应。文章进一步详述了实验操作的具体步骤,包括设备搭建、二极管的选取和安装、数据采
重命名域控制器:专家揭秘安全流程和必备准备
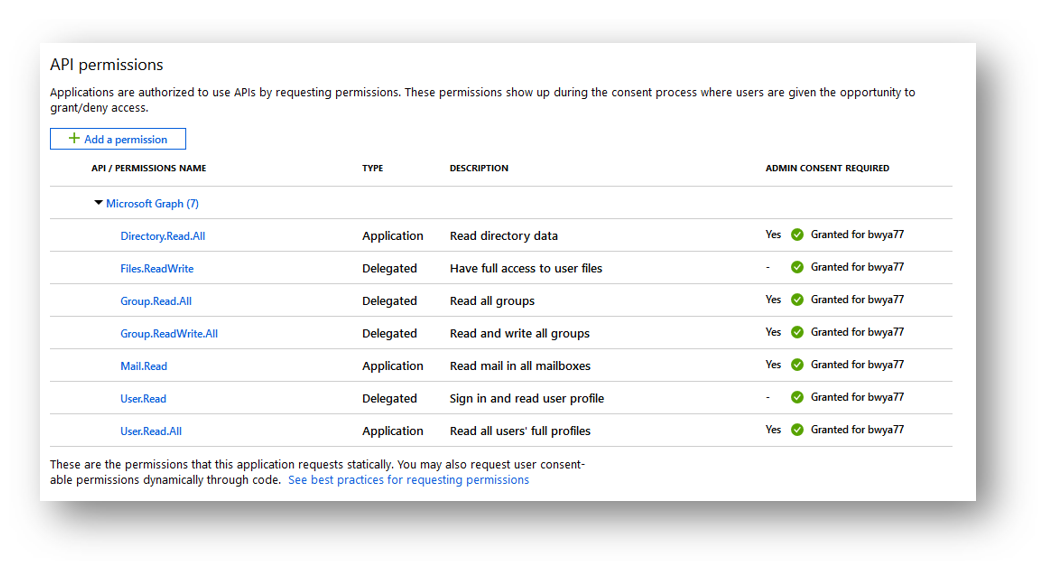
# 摘要
本文深入探讨了域控制器重命名的过程及其对系统环境的影响,阐述了域控制器的工作原理、角色和职责,以及重命名的目的和必要性。文章着重介绍了重命名前的准备工作,包括系统环境评估、备份和恢复策略以及变更管理流程,确保重命名操作的安全性和系统的稳定运行。实践操作部分详细说明了实施步骤和技巧,以及重命名后的监控和调优方法。最后,本文讨论了在重命名域控制器过程中的安全最佳实践和合规性检查,以满足信息安全和监管要求。整体而言,
【精通增量式PID】:参数调整与稳定性的艺术

# 摘要
增量式PID控制器是一种常见的控制系统,以其结构简单、易于调整和较高的控制精度广泛应用于工业过程控制、机器人系统和汽车电子等领域。本文深入探讨了增量式PID控制器的基本原理,详细分析了参数调整的艺术、稳定性分析与优化策略,并通过实际应用案例,展现了其在不同系统中的性能。同时,本文介绍了模糊控制、自适应PID策略和预测控制技术与增量式PID结合的
CarSim参数与控制算法协同:深度探讨与案例分析

# 摘要
本文介绍了CarSim软件的基本概念、参数系统及其与控制算法之间的协同优化方法。首先概述了CarSim软件的特点及参数系统,然后深入探讨了参数调整
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )