YOLOv5目标检测:入门指南:5步掌握YOLOv5架构与训练技巧
发布时间: 2024-08-15 07:26:51 阅读量: 11 订阅数: 14 
# 1. YOLOv5目标检测概述
YOLOv5(You Only Look Once version 5)是一种实时目标检测算法,以其速度快、精度高而闻名。它基于YOLO系列算法,在速度和精度方面进行了显著改进。
YOLOv5采用端到端训练方式,将目标检测任务视为回归问题。它使用单一神经网络同时预测边界框和类别概率。这种方法消除了传统目标检测算法中繁琐的后处理步骤,从而实现了实时目标检测。
YOLOv5具有高度模块化的架构,允许用户根据特定任务需求定制模型。它还提供了广泛的数据增强技术,以提高模型的鲁棒性和泛化能力。
# 2. YOLOv5架构与原理
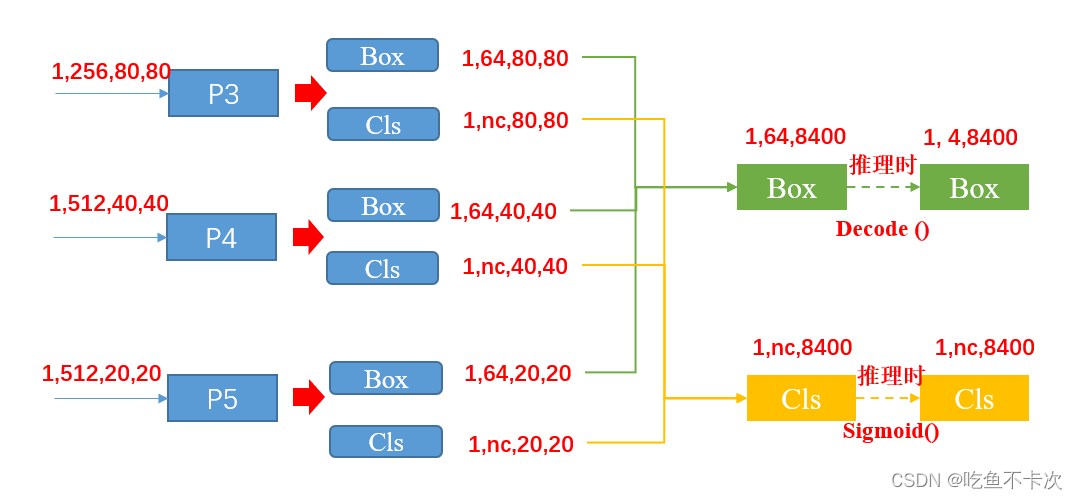
### 2.1 YOLOv5网络结构
#### 2.1.1 Backbone网络
YOLOv5采用CSPDarknet53作为Backbone网络,该网络基于Darknet53架构,引入了CSP(Cross Stage Partial)结构。CSP结构将网络中的卷积层划分为两部分,一部分进行常规卷积,另一部分进行深度可分离卷积。深度可分离卷积将卷积操作分解为两个步骤:深度卷积和逐点卷积。深度卷积沿通道方向进行卷积,逐点卷积沿空间维度进行卷积。这种分解可以减少计算量,同时保持较高的准确性。
#### 2.1.2 Neck网络
Neck网络负责将Backbone网络提取的特征图融合起来,以获得更丰富的语义信息。YOLOv5采用FPN(Feature Pyramid Network)作为Neck网络。FPN通过自顶向下的路径和横向连接将不同尺度的特征图融合在一起。自顶向下的路径将高层特征图上采样,横向连接将低层特征图与上采样后的高层特征图融合。这种融合可以获得具有不同尺度和语义信息的特征图,有利于目标检测。
#### 2.1.3 Detection Head
Detection Head负责将Neck网络提取的特征图转换为目标检测结果。YOLOv5采用YOLO Head作为Detection Head。YOLO Head是一个单卷积层,其输出是一个三维张量,包含了目标的边界框和置信度。边界框由中心点坐标、宽高和偏移量组成,置信度表示目标存在的概率。
### 2.2 YOLOv5目标检测原理
#### 2.2.1 Bounding Box回归
YOLOv5采用IoU(Intersection over Union)损失函数进行Bounding Box回归。IoU损失函数衡量了预测边界框与真实边界框的重叠程度。YOLOv5使用Smooth L1损失函数对IoU损失进行平滑,以提高模型的鲁棒性。
#### 2.2.2 非极大值抑制(NMS)
NMS是一种后处理技术,用于从多个重叠的边界框中选择最优的边界框。NMS首先根据置信度对边界框进行排序,然后依次遍历边界框。对于每个边界框,NMS计算其与其他边界框的IoU,如果IoU大于某个阈值,则将其他边界框抑制。通过NMS,可以获得不重叠的、置信度最高的边界框。
```python
def nms(boxes, scores, iou_threshold=0.5):
"""
非极大值抑制
Args:
boxes: 边界框,形状为(N, 4)
scores: 置信度,形状为(N,)
iou_threshold: IoU阈值
Returns:
保留的边界框索引
"""
# 排序
order = scores.argsort()[::-1]
# 初始化保留的边界框索引
keep = []
# 遍历边界框
while order.size > 0:
# 获取置信度最高的边界框
i = order[0]
# 添加到保留的边界框索引
keep.append(i)
# 计算与其他边界框的IoU
ious = bbox_iou(boxes[i], boxes[order[1:]]).squeeze()
# 抑制IoU大于阈值的边界框
order = order[1:][ious < iou_threshold]
return keep
```
# 3.1 数据集准备
#### 3.1.1 数据集选择
数据集的选择是目标检测训练的关键步骤,它直接影响模型的性能。对于 YOLOv5 训练,常用的数据集包括:
| 数据集 | 类别数 | 图像数 | 注释格式 |
|---|---|---|---|
| COCO | 80 | 123,287 | JSON |
| Pascal VOC | 20 | 11,532 | XML |
| ImageNet | 1,000 | 1,281,167 | JSON |
在选择数据集时,需要考虑以下因素:
* **类别数:**数据集的类别数决定了模型的识别能力。类别数越多,模型的识别难度越大。
* **图像数:**图像数影响模型的泛化能力。图像数越多,模型的泛化能力越好。
* **注释格式:**数据集的注释格式必须与 YOLOv5 训练框架兼容。
#### 3.1.2 数据集标注
数据集标注是将图像中的目标标记为边界框和类别标签的过程。对于 YOLOv5 训练,常用的标注工具包括:
* **LabelImg:**一个开源的图像标注工具,支持多种注释格式。
* **VOTT:**一个基于 Web 的图像标注工具,具有直观的界面和协作功能。
* **CVAT:**一个开源的视频和图像标注工具,支持多种注释格式和高级标注功能。
在标注数据集时,需要确保边界框的准确性和类别标签的一致性。不准确的标注会影响模型的训练效果。
# 4. YOLOv5模型评估与优化
### 4.1 模型评估
#### 4.1.1 精度指标
模型评估是衡量目标检测模型性能的重要步骤。YOLOv5使用以下精度指标来评估其检测性能:
- **平均精度(mAP)**:mAP是目标检测模型的综合精度指标,它计算了模型在不同IOU阈值下的平均精度。IOU(交并比)衡量了预测边界框和真实边界框之间的重叠程度。
- **召回率**:召回率衡量了模型检测出所有真实目标的能力。它计算为检测出的真实目标数量与所有真实目标数量之比。
- **准确率**:准确率衡量了模型预测的边界框与真实边界框匹配的程度。它计算为正确预测的边界框数量与所有预测的边界框数量之比。
#### 4.1.2 速度指标
除了精度外,模型的速度也是一个重要的评估因素。YOLOv5使用以下速度指标来衡量其推理速度:
- **帧率(FPS)**:FPS衡量了模型每秒处理的帧数。它表示模型的实时性。
- **推理时间**:推理时间衡量了模型处理单个图像所需的时间。它表示模型的效率。
### 4.2 模型优化
为了提高模型的精度和速度,可以使用各种优化技术。YOLOv5支持以下模型优化方法:
#### 4.2.1 模型剪枝
模型剪枝是一种通过去除冗余权重来减小模型大小的技术。它可以显著减少模型的大小和推理时间,同时保持模型的精度。
#### 4.2.2 量化
量化是一种将浮点权重转换为低精度整数的技术。它可以进一步减小模型的大小和推理时间,同时保持模型的精度。
### 代码示例
**模型剪枝**
```python
import torch
from torch.nn.utils.prune import l1_unstructured
# 定义剪枝率
prune_rate = 0.5
# 获取模型
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
# 剪枝模型
l1_unstructured(model, name='conv1', amount=prune_rate)
# 保存剪枝后的模型
torch.save(model, 'yolov5s_pruned.pt')
```
**代码逻辑分析**
此代码示例演示了如何使用PyTorch的`l1_unstructured`函数对YOLOv5模型进行剪枝。`prune_rate`参数指定了要剪枝的权重的百分比。`l1_unstructured`函数对模型中指定的层(`conv1`)应用L1非结构化剪枝。剪枝后的模型保存在`yolov5s_pruned.pt`文件中。
**量化**
```python
import torch
from torch.quantization import quantize
# 定义量化配置
quantization_config = torch.quantization.QConfig(activation=torch.quantization.default_observer, weight=torch.quantization.default_per_channel_weight_observer)
# 获取模型
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
# 量化模型
quantized_model = quantize(model, config=quantization_config)
# 保存量化后的模型
torch.save(quantized_model, 'yolov5s_quantized.pt')
```
**代码逻辑分析**
此代码示例演示了如何使用PyTorch的`quantize`函数对YOLOv5模型进行量化。`quantization_config`参数指定了量化的配置。`quantize`函数对模型应用量化,并将其保存在`yolov5s_quantized.pt`文件中。
### 优化效果评估
模型优化后,可以通过重新评估模型的精度和速度指标来评估优化效果。通常,优化后的模型可以在保持或提高精度的情况下减少模型大小和推理时间。
### 总结
模型评估和优化是提高YOLOv5模型性能的关键步骤。通过使用精度和速度指标,可以评估模型的性能。通过应用模型剪枝和量化等优化技术,可以提高模型的效率和推理速度。
# 5.1 目标检测应用
### 5.1.1 图像目标检测
**步骤:**
1. **加载模型:**使用`torchvision.models`模块加载预训练的YOLOv5模型。
2. **预处理图像:**将图像调整为模型输入尺寸,并将其转换为张量。
3. **模型推理:**将图像张量输入模型进行推理,得到目标检测结果。
4. **后处理结果:**对检测结果进行后处理,包括过滤低置信度目标、非极大值抑制等。
5. **可视化结果:**将检测结果可视化在图像上,显示目标边界框和类别标签。
**代码示例:**
```python
import torch
from torchvision.models import yolov5
# 加载模型
model = yolov5.yolov5s()
# 预处理图像
image = cv2.imread("image.jpg")
image = cv2.resize(image, (640, 640))
image = torch.from_numpy(image).permute(2, 0, 1).unsqueeze(0)
# 模型推理
with torch.no_grad():
outputs = model(image)
# 后处理结果
results = yolov5.utils.nms(outputs[0], 0.5, 0.45)
# 可视化结果
for result in results:
x1, y1, x2, y2, conf, cls = result
cv2.rectangle(image, (int(x1), int(y1)), (int(x2), int(y2)), (0, 255, 0), 2)
cv2.putText(image, f"{classes[int(cls)]} {conf:.2f}", (int(x1), int(y1) - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
cv2.imshow("Image", image)
cv2.waitKey(0)
```
### 5.1.2 视频目标检测
**步骤:**
1. **初始化视频流:**使用`cv2`模块初始化视频流,从摄像头或视频文件读取帧。
2. **模型推理:**对每一帧图像进行目标检测,如5.1.1所述。
3. **可视化结果:**将检测结果可视化在帧上,并显示在视频流中。
**代码示例:**
```python
import cv2
import torch
from torchvision.models import yolov5
# 加载模型
model = yolov5.yolov5s()
# 初始化视频流
cap = cv2.VideoCapture("video.mp4")
while True:
# 读取帧
ret, frame = cap.read()
if not ret:
break
# 预处理帧
frame = cv2.resize(frame, (640, 640))
frame = torch.from_numpy(frame).permute(2, 0, 1).unsqueeze(0)
# 模型推理
with torch.no_grad():
outputs = model(frame)
# 后处理结果
results = yolov5.utils.nms(outputs[0], 0.5, 0.45)
# 可视化结果
for result in results:
x1, y1, x2, y2, conf, cls = result
cv2.rectangle(frame, (int(x1), int(y1)), (int(x2), int(y2)), (0, 255, 0), 2)
cv2.putText(frame, f"{classes[int(cls)]} {conf:.2f}", (int(x1), int(y1) - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
# 显示帧
cv2.imshow("Video", frame)
if cv2.waitKey(1) & 0xFF == ord("q"):
break
cap.release()
cv2.destroyAllWindows()
```
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面深入地探讨了 YOLO 目标检测算法,涵盖了从原理到实战的各个方面。专栏文章循序渐进地介绍了 YOLOv5 架构、训练技巧、性能优化秘籍、部署与应用指南,以及多目标检测、目标跟踪、目标分类、目标定位、目标识别等实战技巧。此外,还提供了数据增强技巧、超参数调优指南、常见问题与解决方案、数据集分析、模型评估和前沿技术进展等内容。通过阅读本专栏,读者可以全面掌握 YOLO 目标检测算法,并将其应用于实际场景中,提升目标检测性能和解决实际问题的能力。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
PyCharm and Docker Integration: Effortless Management of Docker Containers, Simplified Development
# 1. Introduction to Docker**
Docker is an open-source containerization platform that enables developers to package and deploy applications without the need to worry about the underlying infrastructure.
**Advantages of Docker:**
- **Isolation:** Docker containers are independent sandbox environme
Peripheral Driver Development and Implementation Tips in Keil5
# 1. Overview of Peripheral Driver Development with Keil5
## 1.1 Concept and Role of Peripheral Drivers
Peripheral drivers are software modules designed to control communication and interaction between external devices (such as LEDs, buttons, sensors, etc.) and the main control chip. They act as an
Detect and Clear Malware in Google Chrome
# Discovering and Clearing Malware in Google Chrome
## 1. Understanding the Dangers of Malware
Malware refers to malicious programs that intend to damage, steal, or engage in other malicious activities to computer systems and data. These malicious programs include viruses, worms, trojans, spyware,
The Application of Numerical Computation in Artificial Intelligence and Machine Learning
# 1. Fundamentals of Numerical Computation
## 1.1 The Concept of Numerical Computation
Numerical computation is a computational method that solves mathematical problems using approximate numerical values instead of exact symbolic methods. It involves the use of computer-based numerical approximati
Keyboard Shortcuts and Command Line Tips in MobaXterm
# Quick Keys and Command Line Operations Tips in Mobaxterm
## 1. Basic Introduction to Mobaxterm
Mobaxterm is a powerful, cross-platform terminal tool that integrates numerous commonly used remote connection features such as SSH, FTP, SFTP, etc., making it easy for users to manage and operate remo
Research on the Application of ST7789 Display in IoT Sensor Monitoring System
# Introduction
## 1.1 Research Background
With the rapid development of Internet of Things (IoT) technology, sensor monitoring systems have been widely applied in various fields. Sensors can collect various environmental parameters in real-time, providing vital data support for users. In these mon
The Role of MATLAB Matrix Calculations in Machine Learning: Enhancing Algorithm Efficiency and Model Performance, 3 Key Applications
# Introduction to MATLAB Matrix Computations in Machine Learning: Enhancing Algorithm Efficiency and Model Performance with 3 Key Applications
# 1. A Brief Introduction to MATLAB Matrix Computations
MATLAB is a programming language widely used for scientific computing, engineering, and data analys
MATLAB-Based Fault Diagnosis and Fault-Tolerant Control in Control Systems: Strategies and Practices
# 1. Overview of MATLAB Applications in Control Systems
MATLAB, a high-performance numerical computing and visualization software introduced by MathWorks, plays a significant role in the field of control systems. MATLAB's Control System Toolbox provides robust support for designing, analyzing, and
【Basics】Image Reading and Display in MATLAB: Reading Images from File and Displaying Them
# 1. An Overview of MATLAB Image Processing
The MATLAB Image Processing Toolbox is a powerful set of functions designed for the processing and analysis of digital images. It offers a variety of functions that can be used for image reading, display, enhancement, segmentation, feature extraction, and
The Relationship Between MATLAB Prices and Sales Strategies: The Impact of Sales Channels and Promotional Activities on Pricing, Master Sales Techniques, Save Money More Easily
# Overview of MATLAB Pricing Strategy
MATLAB is a commercial software widely used in the fields of engineering, science, and mathematics. Its pricing strategy is complex and variable due to its wide range of applications and diverse user base. This chapter provides an overview of MATLAB's pricing s
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )