揭秘递归算法的奥义:深入理解递归思想,掌握应用精髓
发布时间: 2024-08-24 23:50:20 阅读量: 28 订阅数: 28 

C语言中的递归与迭代:深入理解与实践
# 1. 递归算法的基本原理和特性
递归算法是一种解决问题的技术,它通过不断地调用自身来解决问题。递归算法的关键在于定义一个基线条件,当问题被缩小到基线条件时,算法停止递归并返回结果。
递归算法具有以下特性:
- **自相似性:**递归算法将问题分解成较小版本的自身,直到达到基线条件。
- **深度优先:**递归算法在解决问题时,会先深入到问题的最深处,然后再返回并解决较浅层的问题。
- **尾递归:**如果递归调用是函数的最后一个操作,则称为尾递归。尾递归可以优化算法,因为它不需要在调用自身后保存函数的局部变量。
# 2. 递归算法的实践应用
递归算法在实际开发中有着广泛的应用,尤其是在数据结构和算法设计领域。本章节将深入探讨递归算法在这些领域的应用,并通过具体的代码示例进行详细分析。
### 2.1 递归算法在数据结构中的应用
#### 2.1.1 栈和队列的递归实现
栈和队列是两种基本的数据结构,它们通常使用递归算法来实现。
**栈的递归实现**
```python
class Stack:
def __init__(self):
self.items = []
def push(self, item):
self.items.append(item)
def pop(self):
if not self.is_empty():
return self.items.pop()
else:
raise IndexError("Stack is empty")
def is_empty(self):
return len(self.items) == 0
```
**逻辑分析:**
* `push` 方法使用递归将元素压入栈中。如果栈为空,则直接将元素添加到列表中。否则,将元素添加到列表中,然后递归调用 `push` 方法,将剩余元素压入栈中。
* `pop` 方法使用递归从栈中弹出元素。如果栈为空,则引发异常。否则,从列表中弹出元素,然后递归调用 `pop` 方法,弹出剩余元素。
* `is_empty` 方法使用递归检查栈是否为空。如果栈为空,则返回 `True`。否则,递归调用 `is_empty` 方法,检查剩余元素是否为空。
**队列的递归实现**
```python
class Queue:
def __init__(self):
self.items = []
def enqueue(self, item):
self.items.insert(0, item)
def dequeue(self):
if not self.is_empty():
return self.items.pop()
else:
raise IndexError("Queue is empty")
def is_empty(self):
return len(self.items) == 0
```
**逻辑分析:**
* `enqueue` 方法使用递归将元素插入队列中。如果队列为空,则直接将元素添加到列表中。否则,将元素添加到列表开头,然后递归调用 `enqueue` 方法,将剩余元素插入队列中。
* `dequeue` 方法使用递归从队列中删除元素。如果队列为空,则引发异常。否则,从列表中删除元素,然后递归调用 `dequeue` 方法,删除剩余元素。
* `is_empty` 方法使用递归检查队列是否为空。如果队列为空,则返回 `True`。否则,递归调用 `is_empty` 方法,检查剩余元素是否为空。
#### 2.1.2 树和图的递归遍历
树和图是常见的非线性数据结构,它们通常使用递归算法进行遍历。
**树的递归遍历**
```python
class Node:
def __init__(self, data):
self.data = data
self.left = None
self.right = None
def preorder_traversal(root):
if root is not None:
print(root.data)
preorder_traversal(root.left)
preorder_traversal(root.right)
```
**逻辑分析:**
* 前序遍历使用递归遍历树。它首先访问根节点,然后递归遍历左子树,最后递归遍历右子树。
**图的递归遍历**
```python
class Graph:
def __init__(self):
self.vertices = {}
def add_edge(self, source, destination):
if source not in self.vertices:
self.vertices[source] = []
self.vertices[source].append(destination)
def depth_first_search(graph, start):
visited = set()
def dfs(vertex):
if vertex not in visited:
visited.add(vertex)
print(vertex)
for neighbor in graph.vertices[vertex]:
dfs(neighbor)
dfs(start)
```
**逻辑分析:**
* 深度优先搜索使用递归遍历图。它从起始节点开始,递归遍历所有相邻节点,然后递归遍历相邻节点的相邻节点,以此类推。
# 3. 递归算法的优化和调试
### 3.1 递归算法的优化策略
#### 3.1.1 尾递归优化
尾递归是指递归函数在递归调用之前,没有其他操作。优化尾递归可以避免不必要的函数调用和栈空间消耗。
```python
def factorial(n):
if n == 0:
return 1
else:
return n * factorial(n - 1)
```
优化后的尾递归版本:
```python
def factorial(n):
def factorial_helper(n, result):
if n == 0:
return result
else:
return factorial_helper(n - 1, n * result)
return factorial_helper(n, 1)
```
**逻辑分析:**
优化后的版本将递归调用放在函数末尾,并且将中间结果存储在 `result` 参数中。这样,每次递归调用时,栈帧只存储 `n` 和 `result` 两个值,避免了不必要的函数调用开销。
#### 3.1.2 备忘录优化
备忘录优化适用于递归函数计算的结果具有重叠性。它通过存储已计算的结果,避免重复计算。
```python
def fibonacci(n):
if n <= 1:
return n
else:
return fibonacci(n - 1) + fibonacci(n - 2)
```
优化后的备忘录版本:
```python
def fibonacci(n):
memo = {}
def fibonacci_helper(n):
if n in memo:
return memo[n]
if n <= 1:
result = n
else:
result = fibonacci_helper(n - 1) + fibonacci_helper(n - 2)
memo[n] = result
return result
return fibonacci_helper(n)
```
**逻辑分析:**
优化后的版本使用 `memo` 字典存储已计算的结果。当函数再次调用时,它首先检查 `memo` 中是否存在结果。如果存在,则直接返回,避免重复计算。
### 3.2 递归算法的调试技巧
#### 3.2.1 断点调试
断点调试是通过在代码中设置断点,在运行时暂停程序并检查变量值。这有助于识别错误并理解递归函数的执行流程。
**示例:**
```python
def factorial(n):
if n == 0:
return 1
else:
return n * factorial(n - 1)
n = 5
result = factorial(n)
```
设置断点后,程序将在 `result = factorial(n)` 行暂停。此时,可以检查 `n` 和 `result` 的值,并逐步调试递归函数的执行。
#### 3.2.2 堆栈跟踪
堆栈跟踪显示了递归函数调用的堆栈帧,有助于识别递归深度和错误来源。
**示例:**
```python
def factorial(n):
if n == 0:
return 1
else:
return n * factorial(n - 1)
n = -1
result = factorial(n)
```
运行代码后,将出现以下堆栈跟踪:
```
Traceback (most recent call last):
File "factorial.py", line 10, in <module>
result = factorial(n)
File "factorial.py", line 5, in factorial
return n * factorial(n - 1)
File "factorial.py", line 5, in factorial
return n * factorial(n - 1)
File "factorial.py", line 5, in factorial
return n * factorial(n - 1)
...
RecursionError: maximum recursion depth exceeded in comparison
```
堆栈跟踪显示了递归调用的深度,并指出错误发生在 `n` 为负数时。
# 4. 递归算法的进阶应用
### 4.1 递归算法在人工智能中的应用
递归算法在人工智能领域有着广泛的应用,特别是在机器学习和深度学习中。
#### 4.1.1 决策树和随机森林
决策树是一种监督学习算法,它使用递归的方式将数据划分为更小的子集,直到每个子集都包含相同类别的样本。决策树的递归过程如下:
```python
def build_decision_tree(data, target_attribute):
# 如果数据为空或所有样本属于同一类别,则返回一个叶节点
if not data or len(set(data[target_attribute])) == 1:
return LeafNode(data[target_attribute].iloc[0])
# 选择最佳分割属性
best_attribute = find_best_attribute(data, target_attribute)
# 递归构建子树
subtrees = {}
for value in data[best_attribute].unique():
subtrees[value] = build_decision_tree(data[data[best_attribute] == value], target_attribute)
# 返回根节点
return DecisionNode(best_attribute, subtrees)
```
**代码逻辑分析:**
* `find_best_attribute` 函数根据信息增益或基尼不纯度等指标选择最佳分割属性。
* 递归调用 `build_decision_tree` 函数为每个分割属性构建子树。
* `DecisionNode` 类表示决策树的内部节点,它包含分割属性和子树。
* `LeafNode` 类表示决策树的叶节点,它包含预测的类别。
随机森林是一种集成学习算法,它通过组合多个决策树来提高预测准确性。随机森林的训练过程如下:
```python
def train_random_forest(data, target_attribute, num_trees):
# 初始化随机森林
forest = []
# 训练多个决策树
for _ in range(num_trees):
# 随机抽样数据
sampled_data = data.sample(frac=1.0, replace=True)
# 构建决策树
tree = build_decision_tree(sampled_data, target_attribute)
# 添加决策树到森林中
forest.append(tree)
# 返回随机森林
return forest
```
**代码逻辑分析:**
* `train_random_forest` 函数初始化一个空森林。
* 循环 `num_trees` 次,每次随机抽样数据并构建决策树。
* 将构建的决策树添加到森林中。
#### 4.1.2 神经网络和深度学习
神经网络是一种深度学习模型,它使用递归的方式处理序列数据。循环神经网络 (RNN) 和长短期记忆 (LSTM) 网络是两种常见的递归神经网络。
**循环神经网络 (RNN)**
```python
class RNN:
def __init__(self, input_size, hidden_size, output_size):
# 初始化权重和偏置
self.W_hh = torch.randn(hidden_size, hidden_size)
self.W_xh = torch.randn(input_size, hidden_size)
self.W_hy = torch.randn(hidden_size, output_size)
self.b_h = torch.zeros(hidden_size)
self.b_y = torch.zeros(output_size)
def forward(self, x):
# 初始化隐藏状态
h = torch.zeros(self.hidden_size)
# 递归计算隐藏状态和输出
outputs = []
for t in range(len(x)):
h = torch.tanh(self.W_hh @ h + self.W_xh @ x[t] + self.b_h)
y = torch.softmax(self.W_hy @ h + self.b_y)
outputs.append(y)
return outputs
```
**代码逻辑分析:**
* `RNN` 类初始化权重和偏置。
* `forward` 方法初始化隐藏状态,然后递归计算隐藏状态和输出。
* 循环神经网络通过将前一时刻的隐藏状态作为当前时刻的输入,从而处理序列数据。
**长短期记忆 (LSTM) 网络**
```python
class LSTM:
def __init__(self, input_size, hidden_size, output_size):
# 初始化门控和权重
self.W_f = torch.randn(input_size + hidden_size, hidden_size)
self.W_i = torch.randn(input_size + hidden_size, hidden_size)
self.W_c = torch.randn(input_size + hidden_size, hidden_size)
self.W_o = torch.randn(input_size + hidden_size, hidden_size)
self.b_f = torch.zeros(hidden_size)
self.b_i = torch.zeros(hidden_size)
self.b_c = torch.zeros(hidden_size)
self.b_o = torch.zeros(hidden_size)
def forward(self, x):
# 初始化隐藏状态和细胞状态
h = torch.zeros(self.hidden_size)
c = torch.zeros(self.hidden_size)
# 递归计算门控、隐藏状态和细胞状态
outputs = []
for t in range(len(x)):
# 计算门控
f = torch.sigmoid(self.W_f @ torch.cat([h, x[t]], dim=1) + self.b_f)
i = torch.sigmoid(self.W_i @ torch.cat([h, x[t]], dim=1) + self.b_i)
o = torch.sigmoid(self.W_o @ torch.cat([h, x[t]], dim=1) + self.b_o)
# 更新细胞状态
c = f * c + i * torch.tanh(self.W_c @ torch.cat([h, x[t]], dim=1) + self.b_c)
# 更新隐藏状态
h = o * torch.tanh(c)
# 计算输出
y = torch.softmax(self.W_hy @ h + self.b_y)
outputs.append(y)
return outputs
```
**代码逻辑分析:**
* `LSTM` 类初始化门控和权重。
* `forward` 方法初始化隐藏状态和细胞状态,然后递归计算门控、隐藏状态和细胞状态。
* LSTM 网络通过使用门控来控制信息流,从而更好地处理长期依赖关系。
### 4.2 递归算法在自然语言处理中的应用
递归算法在自然语言处理中也得到了广泛的应用,特别是在语言建模和机器翻译中。
#### 4.2.1 语言模型和机器翻译
语言模型是一种概率分布,它预测给定序列中下一个单词出现的概率。递归神经网络可以用来构建语言模型,例如:
```python
class LanguageModel:
def __init__(self, vocab_size, embedding_size, hidden_size):
# 初始化嵌入层和循环神经网络
self.embedding = nn.Embedding(vocab_size, embedding_size)
self.rnn = nn.LSTM(embedding_size, hidden_size)
def forward(self, x):
# 嵌入输入序列
x = self.embedding(x)
# 递归计算隐藏状态和输出
outputs, (h, c) = self.rnn(x)
# 计算输出概率
logits = self.fc(outputs)
probs = torch.softmax(logits, dim=-1)
return probs
```
**代码逻辑分析:**
* `LanguageModel` 类初始化嵌入层和循环神经网络。
* `forward` 方法嵌入输入序列,然后递归计算隐藏状态和输出。
* 最后,使用全连接层计算输出概率。
机器翻译是一种将一种语言翻译成另一种语言的任务。递归神经网络也可以用来构建机器翻译模型,例如:
```python
class MachineTranslationModel:
def __init__(self, src_vocab_size, tgt_vocab_size, embedding_size, hidden_size):
# 初始化编码器和解码器
self.encoder = nn.LSTM(src_vocab_size, embedding_size, hidden_size)
self.decoder = nn.LSTM(tgt_vocab_size, embedding_size, hidden_size)
def forward(self, src, tgt):
# 编码源语言序列
encoder_outputs, (h, c) = self.encoder(src)
# 初始化解码器隐藏状态
decoder_h = h
decoder_c = c
# 递归解码目标语言序列
outputs = []
for t in range(len(tgt)):
# 计算解码器输入
decoder_input = self.embedding(tgt[t])
# 更新解码器隐藏状态
# 5. 递归算法的局限性和替代方案
### 5.1 递归算法的局限性
递归算法虽然具有简洁优雅的特性,但它也存在一些固有的局限性,主要体现在以下两个方面:
#### 5.1.1 栈空间溢出
递归算法在调用过程中,会不断压栈,如果递归深度过大,可能会导致栈空间溢出。这是因为栈空间通常是有限的,当递归调用次数过多时,栈空间就会被耗尽,导致程序崩溃。
例如,以下代码使用递归算法计算阶乘:
```python
def factorial(n):
if n == 0:
return 1
else:
return n * factorial(n - 1)
```
如果输入一个较大的数字,如 10000,就会导致栈空间溢出。
#### 5.1.2 效率低下
对于某些问题,递归算法的效率可能较低。这是因为递归算法在每次调用时都需要创建新的栈帧,这会带来额外的开销。对于规模较大的问题,这种开销会变得非常明显。
例如,以下代码使用递归算法计算斐波那契数列:
```python
def fibonacci(n):
if n == 0 or n == 1:
return 1
else:
return fibonacci(n - 1) + fibonacci(n - 2)
```
对于较大的 n 值,递归算法的效率会非常低,因为存在大量的重复计算。
### 5.2 递归算法的替代方案
为了克服递归算法的局限性,可以考虑以下替代方案:
#### 5.2.1 迭代算法
迭代算法使用循环来代替递归调用。与递归算法相比,迭代算法不需要压栈,因此不会出现栈空间溢出的问题。此外,迭代算法通常比递归算法更有效率,因为没有额外的栈帧开销。
例如,以下代码使用迭代算法计算阶乘:
```python
def factorial_iterative(n):
result = 1
for i in range(1, n + 1):
result *= i
return result
```
#### 5.2.2 尾递归消除
尾递归消除是一种优化技术,可以将尾递归函数转换为迭代函数。尾递归是指函数在最后一次调用自身后立即返回。通过尾递归消除,可以避免额外的栈帧开销,从而提高效率。
例如,以下代码使用尾递归消除优化了阶乘计算函数:
```python
def factorial_tail_recursive(n, result=1):
if n == 0:
return result
else:
return factorial_tail_recursive(n - 1, result * n)
```
# 6.1 递归算法的优势和劣势
**优势:**
* **简洁性:**递归算法通常比迭代算法更简洁、更易于理解,因为它们利用了函数自身的调用来解决问题。
* **可读性:**递归算法的结构清晰,易于阅读和理解,尤其是对于复杂的问题。
* **自然性:**递归算法遵循了问题的自然分解方式,这使得它们在解决某些类型的问题时非常有效。
**劣势:**
* **栈空间溢出:**递归算法可能会导致栈空间溢出,因为每个函数调用都会在栈中创建一个新的栈帧。
* **效率低下:**递归算法通常比迭代算法效率低下,因为每次函数调用都会带来额外的开销。
* **调试困难:**递归算法的调试可能很困难,因为错误可能出现在任何函数调用中,而且调用堆栈可能很深。
## 6.2 递归算法在未来发展中的趋势
随着计算机技术的不断发展,递归算法在未来仍将发挥重要作用,但其应用方式可能会发生变化。以下是一些可能的趋势:
* **尾递归优化:**尾递归优化技术将递归算法转换为迭代算法,从而消除栈空间溢出的风险。
* **备忘录优化:**备忘录优化技术通过存储重复计算的结果来提高递归算法的效率。
* **并行递归:**并行递归技术利用多核处理器或分布式计算来并行执行递归调用,从而提高性能。
* **人工智能和机器学习:**递归算法在人工智能和机器学习中扮演着重要角色,例如在神经网络和深度学习中。随着这些领域的不断发展,递归算法在这些领域中的应用也将不断扩大。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了递归算法的基本思想和应用实战。从揭秘递归算法的奥义到掌握应用精髓,全面解析递归算法,从基础到精通。同时,专栏还探讨了递归算法的艺术,掌握递归技巧,解决复杂问题。此外,专栏还分析了递归算法的陷阱和规避方法,避免死循环,提升代码质量。此外,还对表锁问题进行了全解析,深度解读了 MySQL 表锁问题及解决方案。最后,通过索引失效案例分析与解决方案,揭秘了索引失效的根源,并提供了解决方案。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
TSPL2高级打印技巧揭秘:个性化格式与样式定制指南

# 摘要
TSPL2打印语言作为工业打印领域的重要技术标准,具备强大的编程能力和灵活的控制指令,广泛应用于各类打印设备。本文首先对TSPL2打印语言进行概述,详细介绍其基本语法结构、变量与数据类型、控制语句等基础知识。接着,探讨了TSPL2在高级打印技巧方面的应用,包括个性化打印格式设置、样
JFFS2文件系统设计思想:源代码背后的故事
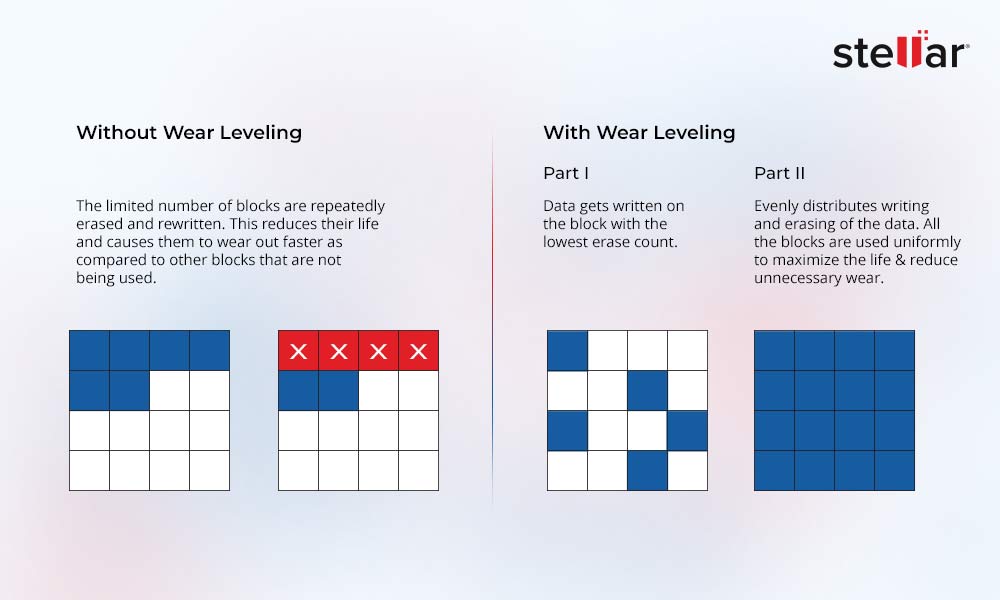
# 摘要
本文对JFFS2文件系统进行了全面的概述和深入的分析。首先介绍了JFFS2文件系统的基本理论,包括文件系统的基础概念和设计理念,以及其核心机制,如红黑树的应用和垃圾回收机制。接着,文章深入剖析了JFFS2的源代码,解释了其结构和挂载过程,以及读写操作的实现原理。此外,针对JFFS2的性能优化进行了探讨,分析了性能瓶颈并提出了优化策略。在此基础上,本文还研究了J
EVCC协议版本兼容性挑战:Gridwiz更新维护攻略

# 摘要
本文对EVCC协议进行了全面的概述,并探讨了其版本间的兼容性问题,这对于电动车充电器与电网之间的有效通信至关重要。文章分析了Gridwiz软件在解决EVCC兼容性问题中的关键作用,并从理论和实践两个角度深入探讨了Gridwiz的更新维护策略。本研究通过具体案例分析了不同EVCC版本下Gridwiz的应用,并提出了高级维护与升级技巧。本文旨在为相关领域的工程师和开发者提供有关EVCC协议及其兼容性维护
计算机组成原理课后答案解析:张功萱版本深入理解

# 摘要
计算机组成原理是理解计算机系统运作的基础。本文首先概述了计算机组成原理的基本概念,接着深入探讨了中央处理器(CPU)的工作原理,包括其基本结构和功能、指令执行过程以及性能指标。然后,本文转向存储系统的工作机制,涵盖了主存与缓存的结构、存储器的扩展与管理,以及高速缓存的优化策略。随后,文章讨论了输入输出系统与总线的技术,阐述了I/O系统的
CMOS传输门故障排查:专家教你识别与快速解决故障
# 摘要
CMOS传输门故障是集成电路设计中的关键问题,影响电子设备的可靠性和性能。本文首先概述了CMOS传输门故障的普遍现象和基本理论,然后详细介绍了故障诊断技术和解决方法,包括硬件更换和软件校正等策略。通过对故障表现、成因和诊断流程的分析,本文旨在提供一套完整的故障排除工具和预防措施。最后,文章展望了CMOS传输门技术的未来挑战和发展方向,特别是在新技术趋势下如何面对小型化、集成化挑战,以及智能故障诊断系统和自愈合技术的发展潜力。
# 关键字
CMOS传输门;故障诊断;故障解决;信号跟踪;预防措施;小型化集成化
参考资源链接:[cmos传输门工作原理及作用_真值表](https://w
KEPServerEX秘籍全集:掌握服务器配置与高级设置(最新版2018特性深度解析)
# 摘要
KEPServerEX作为一种广泛使用的工业通信服务器软件,为不同工业设备和应用程序之间的数据交换提供了强大的支持。本文从基础概述入手,详细介绍了KEPServerEX的安装流程和核心特性,包括实时数据采集与同步,以及对通讯协议和设备驱动的支持。接着,文章深入探讨了服务器的基本配置,安全性和性能优化的高级设
【域控制新手起步】:一步步掌握组策略的基本操作与应用
# 摘要
组策略是域控制器中用于配置和管理网络环境的重要工具。本文首先概述了组策略的基本概念和组成部分,并详细解释了其作用域与优先级规则,以及存储与刷新机制。接着,文章介绍了组策略的基本操作,包括通过管理控制台GPEDIT.MSC的使用、组策略对象(GPO)的管理,以及部署和管理技巧。在实践应用方面,本文探讨了用户环境管理、安全策略配置以及系统配置与优化。此
【SolidWorks自动化工具】:提升重复任务效率的最佳实践

# 摘要
本文全面探讨了SolidWorks自动化工具的开发和应用。首先介绍了自动化工具的基本概念和SolidWorks API的基础知识,然后深入讲解了编写基础自动化脚本的技巧,包括模型操作、文件处理和视图管理等。接着,本文阐述了自动化工具的高级应用
Android USB音频设备通信:实现音频流的无缝传输
# 摘要
随着移动设备的普及,Android平台上的USB音频设备通信已成为重要话题。本文从基础理论入手,探讨了USB音频设备工作原理及音频通信协议标准,深入分析了Android平台音频架构和数据传输流程。随后,实践操作章节指导读者了解如何设置开发环境,编写与测试USB音频通信程序。文章深入讨论了优化音频同步与延迟,加密传输音频数据
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )