【Python编程面试必胜攻略】:20个精选面试题深度解析,提升你的面试技巧
发布时间: 2024-11-16 17:24:52 阅读量: 128 订阅数: 40 

Python面试题解析:涵盖生成器、面向对象、正则表达式及常用技巧

# 1. Python编程面试概述
Python编程面试是IT行业内技术面试的重要组成部分,是企业评估候选人是否具备岗位所需技能的关键环节。面试不仅考察求职者对Python语言的掌握程度,更关注其解决问题的能力以及与团队合作的潜力。在准备Python面试时,候选人需要对基础知识有深刻理解,同时了解行业常用的高级特性和解决问题的技巧。
## 1.1 面试的意义与目的
面试是企业对求职者技能、经验和文化适应性进行综合评估的过程。Python面试通常包括一系列问题和任务,旨在考察求职者的编程能力、逻辑思维、算法知识和项目经验等。面试官通过这些考察点来预测求职者在实际工作中的表现。
## 1.2 面试流程的组成
一个典型的Python编程面试流程包括以下几个步骤:
1. **初步筛选**:通过简历筛选出符合基本要求的候选人。
2. **在线测评**:通过在线平台进行初步的技能测试。
3. **电话/视频面试**:初步了解求职者的沟通能力及技术背景。
4. **现场/远程编码测试**:评估求职者的实际编码能力。
5. **技术面试官面试**:深入探讨技术细节和项目经验。
6. **HR面试**:了解求职者的职业规划和企业文化的契合度。
## 1.3 面试前的准备工作
为了在Python面试中脱颖而出,求职者应当:
- **回顾基础知识**:确保对Python的基本语法、数据结构、控制流等有扎实的掌握。
- **练习编程题目**:通过LeetCode、HackerRank等平台提高算法和数据结构的应用能力。
- **准备项目展示**:梳理并总结个人参与的项目经历,准备好项目中的技术细节和遇到的问题及解决方案。
- **学习行业知识**:了解当前Python在行业中的应用趋势以及相关的技术栈。
掌握面试的流程和准备技巧,可以帮助求职者更加自信和有效地展现自己的技术能力。在接下来的章节中,我们将深入探讨Python的核心知识点和面试技巧。
# 2. Python基础知识回顾
## 2.1 数据类型和结构
Python作为一种高级编程语言,提供了丰富多样的数据类型和数据结构,以支持不同的应用场景和需求。数据类型包括整型、浮点型、字符串、布尔型等,而数据结构则包括了列表(list)、元组(tuple)、字典(dict)和集合(set)等。
### 2.1.1 基本数据类型
Python中的基本数据类型是编程的基础。整型(int)、浮点型(float)、字符串(str)和布尔型(bool)是最常见的几种。
- **整型(int)**:表示没有小数点的数字,可正可负,也可以为零。
- **浮点型(float)**:表示带有小数点的数字,可以有小数部分。
- **字符串(str)**:由字符组成的文本序列,使用单引号或双引号定义。
- **布尔型(bool)**:只有两个值,True(真)或False(假),通常用于逻辑判断。
```python
# 基本数据类型的示例
age = 25 # 整型
salary = 3.1415 # 浮点型
name = "Alice" # 字符串
is_active = True # 布尔型
```
### 2.1.2 列表、元组、字典和集合的操作
Python的数据结构中,列表、元组、字典和集合是使用频率非常高的几种。
- **列表(list)**:可变序列,使用方括号定义,列表中的元素可以是不同的数据类型。
- **元组(tuple)**:不可变序列,通常用圆括号定义,一旦创建就不能修改。
- **字典(dict)**:无序的键值对集合,使用大括号定义,每个元素由键和值组成。
- **集合(set)**:无序且元素唯一的集合,使用大括号或set()函数创建,用于去除重复元素和执行数学上的集合运算。
```python
# 数据结构的操作示例
fruits = ['apple', 'banana', 'cherry'] # 列表
numbers = (1, 2, 3) # 元组
person = {'name': 'Bob', 'age': 30} # 字典
unique_numbers = {1, 2, 3} # 集合
```
## 2.2 函数与模块使用
函数和模块是Python中实现代码复用和封装的基本单位。
### 2.2.1 函数定义与调用
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。通过def关键字定义函数。
```python
# 定义函数
def greet(name):
return "Hello, " + name + "!"
# 调用函数
print(greet("Alice")) # 输出:Hello, Alice!
```
### 2.2.2 模块的导入与使用
模块是包含Python代码的.py文件。要使用一个模块的内容,我们需要导入它。
```python
# 导入标准库中的模块
import math
# 使用模块中的函数
print(math.sqrt(16)) # 输出:4.0
```
### 2.2.3 包的管理与虚拟环境
包允许我们组织模块,将多个模块组合在一起。而虚拟环境则提供了一种隔离依赖关系的方法,使得项目依赖不冲突。
```python
# 创建一个虚拟环境
python -m venv myenv
# 激活虚拟环境
# 在Windows下: myenv\Scripts\activate
# 在Unix或MacOS下: source myenv/bin/activate
```
## 2.3 面向对象编程
面向对象编程(OOP)是一种编程范式,它使用对象和类的概念来设计程序。
### 2.3.1 类与实例
类是创建对象的蓝图或模板,而对象是根据类模板创建的实例。
```python
# 定义一个类
class Car:
def __init__(self, make, model):
self.make = make
self.model = model
def display_info(self):
return f"This car is a {self.make} {self.model}"
# 创建类的实例
my_car = Car("Toyota", "Camry")
print(my_car.display_info()) # 输出:This car is a Toyota Camry
```
### 2.3.2 继承与多态
继承是一种机制,它允许新创建的类从一个现有的类中继承属性和方法。多态是同一操作作用于不同的对象,可以有不同的解释和不同的执行结果。
```python
# 继承和多态的简单示例
class ElectricCar(Car):
def __init__(self, make, model, battery_size):
super().__init__(make, model)
self.battery_size = battery_size
def display_info(self):
return f"{super().display_info()} with a {self.battery_size}-kWh battery"
```
### 2.3.3 魔术方法与属性
魔术方法(或特殊方法)是内置函数,以双下划线开头和结尾的函数。Python用它们来实现语言的魔力,比如实现算术运算、索引和切片、属性访问等。
```python
# 自定义类的表示方法
class Vehicle:
def __init__(self, make, model):
self.make = make
self.model = model
def __repr__(self):
return f"<Vehicle(make='{self.make}', model='{self.model}')>"
# 创建对象并输出
my_vehicle = Vehicle("Honda", "Civic")
print(my_vehicle) # 输出:<Vehicle(make='Honda', model='Civic')>
```
在本章节中,我们回顾了Python的基础知识,从基本数据类型到数据结构,从函数与模块的使用到面向对象编程的基本概念。理解和掌握了这些基础知识,对于通过Python编程面试是非常有帮助的。
# 3. Python高级特性与技巧
## 3.1 迭代器与生成器
迭代器是任何遵循迭代器协议的对象,此协议要求对象实现两个方法,`__iter__()` 和 `__next__()`。生成器是一种特殊的迭代器,它们允许你声明一个包含 yield 关键字的函数,而每次调用生成器时都会返回一个值。
### 3.1.1 迭代器的使用与原理
迭代器的使用可以帮助我们遍历容器(如列表)而不需要在内存中创建整个列表,这样可以节省大量空间,尤其是在处理大型数据集时。此外,迭代器可以一次性从源代码中产生连续的值,而不必在内存中同时存储所有值。
迭代器对象可以使用 `iter()` 函数或直接在 for 循环中使用。使用 `iter()` 函数时,我们可以将迭代器与可迭代对象(如列表)关联起来。迭代器的 `__next__()` 方法用于迭代过程中获取容器中的下一个值。
```python
# 示例代码
my_list = [1, 2, 3, 4, 5]
iterator = iter(my_list)
print(next(iterator)) # 输出 1
print(next(iterator)) # 输出 2
```
在上面的代码块中,`iter(my_list)` 创建了一个迭代器对象,并且使用 `next(iterator)` 我们可以逐个获取列表中的元素。如果我们试图获取超出列表长度的下一个元素,Python 将抛出一个 `StopIteration` 异常。
### 3.1.2 生成器的创建与优势
生成器是创建迭代器的简单方式,使用 `yield` 关键字代替 `return` 关键字。一个含有 `yield` 的函数被称为生成器函数。当调用生成器函数时,它返回一个生成器对象,而不是像普通函数那样返回一个值。
生成器的优势在于,它允许你按需生成值,而不是一次性计算所有值。这在处理大数据集或实现惰性计算时非常有用。
```python
# 示例代码
def count_up_to(max_value):
count = 1
while count <= max_value:
yield count
count += 1
counter = count_up_to(5)
print(next(counter)) # 输出 1
print(next(counter)) # 输出 2
```
在本例中,`count_up_to` 是一个生成器函数,每次调用 `next()` 时,它会产生下一个值,直到达到 `max_value`。生成器的主要优势在于其延迟计算(lazy evaluation),即它们只在实际需要时才计算下一个值。
生成器的工作原理与迭代器类似,但它们更简洁、更易用,并且不需要显式定义 `__iter__()` 和 `__next__()` 方法。
## 3.2 装饰器深入理解
装饰器是 Python 中用于增强函数或类功能的高阶函数。它们可以用来修改或增强被装饰对象的行为,而无需更改其本身。
### 3.2.1 装饰器的定义与使用
装饰器本质上是一个函数,它接受一个函数作为参数并返回一个新的函数。最简单的装饰器是这样的:
```python
def simple_decorator(func):
def wrapper():
print("Something is happening before the function is called.")
func()
print("Something is happening after the function is called.")
return wrapper
@simple_decorator
def say_hello():
print("Hello!")
say_hello()
```
在这个例子中,`simple_decorator` 是一个装饰器,它会在 `say_hello` 函数调用前后打印一些信息。装饰器通过 `@simple_decorator` 语法被应用于 `say_hello` 函数。
### 3.2.2 装饰器的参数化与叠加
装饰器不仅可以不接受参数,还可以使用闭包来接收参数。这些参数化的装饰器通常使用额外的包装函数来实现。
```python
def decorator_with_args(number):
def simple_decorator(func):
def wrapper(*args, **kwargs):
print("Something is happening before the function is called.")
print(f"Argument for the decorator: {number}")
result = func(*args, **kwargs)
print("Something is happening after the function is called.")
return result
return wrapper
return simple_decorator
@decorator_with_args(42)
def say_hello(name):
print(f"Hello {name}!")
say_hello("Alice")
```
在这个例子中,`decorator_with_args` 是一个参数化的装饰器,它接收一个 `number` 参数,并返回一个装饰器 `simple_decorator`。后者则返回实际的包装函数 `wrapper`。这样的结构允许装饰器在被调用时接收参数。
装饰器可以叠加使用,即将多个装饰器应用于同一个函数。Python 将按照它们被指定的顺序来应用这些装饰器,如下所示:
```python
@decorator_with_args(10)
@simple_decorator
def say_goodbye(name):
print(f"Goodbye {name}!")
say_goodbye("Bob")
```
在这里,`say_goodbye` 函数首先应用 `simple_decorator`,然后应用 `decorator_with_args(10)`。装饰器的这种叠加功能提供了极大的灵活性。
装饰器是 Python 中一个非常强大的特性,可以用于日志记录、性能测试、缓存、授权等多种场景。通过理解和掌握装饰器的原理和应用,开发者可以编写更加高效和可维护的代码。
## 3.3 错误与异常处理
Python 中的错误和异常处理是保证程序健壮性和用户友好性的关键。通过正确的异常处理,程序在遇到错误时可以优雅地执行错误处理代码,而不是直接崩溃。
### 3.3.1 常见错误类型及处理方式
Python 用异常对象来表示错误情况,并使用 `try...except` 语句来捕获和处理异常。常见的异常类型包括 `SyntaxError`、`IndentationError`、`IndexError`、`KeyError`、`NameError`、`TypeError` 等。
```python
try:
result = 10 / 0
except ZeroDivisionError:
print("You can't divide by zero!")
finally:
print("This line will always be executed.")
```
在这个例子中,如果 `try` 块中的除法操作发生错误,Python 将捕获 `ZeroDivisionError` 并执行 `except` 块中的代码。无论是否发生异常,`finally` 块中的代码都将被执行。
异常处理的正确方式是捕获特定的异常类型,避免使用过于宽泛的异常捕获(例如使用 `except Exception`)。这有助于保持代码的清晰和可维护性,并确保不会无意中掩盖了其他重要错误。
### 3.3.2 自定义异常与上下文管理
在某些情况下,标准异常类型可能无法完全满足你的需求,这时你可以通过继承 `Exception` 类来自定义异常类型。自定义异常通常用于提供更明确的错误信息和更精确的错误处理。
```python
class MyCustomError(Exception):
pass
try:
raise MyCustomError("This is a custom error message.")
except MyCustomError as e:
print(f"Caught a custom error: {e}")
```
Python 3.6 引入了上下文管理器,可以使用 `with` 语句来管理资源,例如文件操作。`with` 语句可以确保即使发生异常,资源也会被正确释放。
```python
with open("somefile.txt", "w") as f:
f.write("Hello, world!")
# 如果在写文件时发生异常,文件将被正确关闭。
```
上下文管理器的实现依赖于对象的 `__enter__()` 和 `__exit__()` 方法。`__enter__()` 方法在进入 `with` 语句块时被调用,`__exit__()` 方法在退出 `with` 语句块时被调用,无论退出时是否发生了异常。
异常和错误处理是编程中的重要部分,了解和利用 Python 提供的工具可以大大提高程序的健壮性和用户体验。
# 4. Python面试题深度解析
## 4.1 核心数据结构应用题
### 4.1.1 链表、树、图等复杂结构的Python实现
链表、树和图是数据结构中的高级主题,它们在面试中经常出现,以检验候选人的编码能力和对复杂数据结构的理解。在实现这些数据结构时,Python的灵活性和简洁性可以大大简化代码。
#### 链表
链表是一种常见的数据结构,它由一系列节点组成,每个节点包含数据和指向下一个节点的链接。Python没有内置的链表类型,但我们可以很容易地创建自己的链表类。
```python
class ListNode:
def __init__(self, value=0, next=None):
self.value = value
self.next = next
class LinkedList:
def __init__(self):
self.head = None
def append(self, value):
if not self.head:
self.head = ListNode(value)
else:
current = self.head
while current.next:
current = current.next
current.next = ListNode(value)
def display(self):
elements = []
current = self.head
while current:
elements.append(str(current.value))
current = current.next
return ' -> '.join(elements)
```
以上是单向链表的一个基本实现。面试官可能会要求实现双向链表、循环链表或提供对特定算法的支持,如反转链表。
#### 树
树是一种非线性数据结构,它由节点组成,每个节点都有零个或多个子节点。在Python中,树可以用类递归地表示。
```python
class TreeNode:
def __init__(self, value=0, children=None):
self.value = value
self.children = children if children is not None else []
```
面试时,可能会要求实现二叉树、二叉搜索树、堆等,并且实现树的遍历(前序、中序、后序、层序)。
#### 图
图是由节点(顶点)和边组成的复杂数据结构。在Python中,图可以用字典表示,其中键是顶点,值是与顶点相连的边的列表。
```python
class Graph:
def __init__(self):
self.graph = {}
def add_vertex(self, vertex):
if vertex not in self.graph:
self.graph[vertex] = []
def add_edge(self, edge):
(vertex1, vertex2) = edge
self.add_vertex(vertex1)
self.add_vertex(vertex2)
self.graph[vertex1].append(vertex2)
self.graph[vertex2].append(vertex1)
```
在面试中,图的问题常常围绕着图遍历算法(深度优先搜索DFS和广度优先搜索BFS)和图算法(如最短路径算法)。
### 4.1.2 字符串与正则表达式应用
字符串和正则表达式是面试中常见的问题,因为它们在处理文本数据时非常有用。Python的内置字符串处理能力很强,而正则表达式则通过`re`模块来支持。
#### 字符串处理
```python
# 字符串反转
def reverse_string(s):
return s[::-1]
# 查找字符串中最大字母
def find_max_letter(s):
return max(s)
# 字符串压缩
def compress_string(s):
return ''.join([len(list(group)) + x for x, group in itertools.groupby(s)])
```
这些函数展示了字符串处理的基本思路,面试官可能会要求实现更复杂的字符串处理逻辑。
#### 正则表达式
```python
import re
# 验证电子邮件地址
def validate_email(email):
pattern = r"[^@]+@[^@]+\.[^@]+"
return re.match(pattern, email) is not None
# 提取网页上的所有链接
def extract_links(text):
pattern = r'https?://(?:[-\w.]|(?:%[\da-fA-F]{2}))+'
return re.findall(pattern, text)
```
在面试中,通常会涉及匹配模式的编写,以及对正则表达式库的使用细节进行深入提问。
## 4.2 算法与数据处理
### 4.2.1 排序、搜索算法及其实现
排序和搜索算法是编程面试中的经典话题,不仅因为它们是计算机科学的基础,也因为它们在实际软件开发中的广泛应用。面试官通常会要求你不仅要实现算法,还要分析算法的时间复杂度和空间复杂度。
#### 排序算法
```python
def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n-i-1):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
return arr
def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quick_sort(left) + middle + quick_sort(right)
# 使用示例
array = [3, 6, 8, 10, 1, 2, 1]
print("Sorted array:", bubble_sort(array))
print("Sorted array:", quick_sort(array))
```
#### 搜索算法
```python
def binary_search(arr, x):
left, right = 0, len(arr) - 1
while left <= right:
mid = (left + right) // 2
if arr[mid] == x:
return mid
elif arr[mid] < x:
left = mid + 1
else:
right = mid - 1
return -1
# 使用示例
array = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
x = 5
print("Index of element is:", binary_search(array, x))
```
### 4.2.2 数据清洗与分析技巧
数据清洗是数据分析中的重要步骤,Python通过`pandas`库提供了强大的数据处理能力。
```python
import pandas as pd
def clean_data(df):
# 删除缺失值
df_cleaned = df.dropna()
# 删除重复数据
df_cleaned = df_cleaned.drop_duplicates()
# 数据类型转换
df_cleaned['column'] = df_cleaned['column'].astype('int')
# 数据填充
df_cleaned['column'].fillna(df_cleaned['column'].mean(), inplace=True)
return df_cleaned
# 使用示例
data = {'column': [1, None, 3, 4, 5, None]}
df = pd.DataFrame(data)
print("Original data:", df)
df = clean_data(df)
print("Cleaned data:", df)
```
在数据分析和清洗中,候选人需要展示他们理解数据结构的能力,并运用适当的函数和方法来处理数据。
## 4.3 系统设计与架构问题
### 4.3.1 Web应用架构理解
在面试中,可能会要求候选人设计一个简单的Web应用架构。这不仅仅是为了测试编码能力,更是为了考察对整个应用的组件、服务以及它们之间如何协作的理解。
```mermaid
graph TD
A[客户端] -->|请求| B[负载均衡器]
B -->|分发请求| C[应用服务器]
C -->|业务逻辑处理| D[数据库服务器]
D -->|数据存储和检索| C
C -->|返回响应| B
B -->|响应| A
```
在这个基本架构中,负载均衡器负责分配客户端的请求到不同的应用服务器,应用服务器处理业务逻辑并查询数据库服务器,数据库服务器负责存储和检索数据。
在面试中,应能够讨论如何在不同的层之间进行通信、如何实现负载均衡、数据缓存策略以及如何保证系统的可伸缩性和高可用性。
### 4.3.2 缓存策略与数据库优化
面试官可能还会询问如何优化数据库访问和实现缓存机制,以提高Web应用的性能和响应时间。
```mermaid
graph LR
A[用户请求] -->|不命中| C[查询数据库]
C -->|数据| D[写入缓存]
D -->|缓存数据| E[返回用户]
A -->|命中| D
D -->|缓存数据| E
```
在这个流程中,缓存位于应用服务器和数据库之间,用于存储最近查询的数据。当相同的数据被再次请求时,系统会从缓存中读取数据,从而减少了对数据库的访问次数。
在讨论数据库优化时,可以考虑索引的使用、查询优化、事务的管理和分库分表策略等。缓存策略可能涉及内存缓存(如Redis)、数据库查询缓存、页面缓存以及缓存失效策略等。
这些内容展示了对核心数据结构应用题、算法与数据处理以及系统设计与架构问题的深度解析,以及如何运用Python解决这些问题。在面试中,候选人应该能够清晰地解释每个步骤的原因,并展示出良好的编程实践和优化思维。
# 5. Python项目实战经验
在IT行业中,理论知识固然重要,但是没有实践经验,就如同纸上谈兵,无法真正解决问题。本章节将深入探讨Python项目实战经验,我们将从项目的构思与需求分析、开发与测试,以及部署与维护等方面,详细地介绍如何将理论知识应用于实际项目中。
## 5.1 项目构思与需求分析
### 5.1.1 如何定义项目范围和目标
在任何项目开始之前,明确项目范围和目标是最为关键的步骤。项目范围定义了项目的界限,决定了哪些工作是必须完成的,哪些是超出了当前项目的范围。而项目目标则指明了项目的最终成果,它是评估项目成功与否的重要标准。
在定义项目范围和目标时,可以采取以下步骤:
1. **需求收集**:与项目相关的人员进行沟通,了解他们的需求和期望。
2. **可行性分析**:分析项目的技术可行性、资源可用性以及预算和时间限制。
3. **目标设定**:根据收集到的需求和可行性分析结果,设置SMART(具体、可衡量、可达成、相关、时限性)目标。
4. **范围界定**:明确项目的具体边界,列出包括在项目内和项目外的各项工作。
### 5.1.2 需求分析与用户故事编写
需求分析是项目管理的重要环节,其主要目标是理解和记录项目的业务需求。在软件开发领域,用户故事是一种常见的需求表达方式,它从用户的角度描述了用户对系统的需求和期望。
编写用户故事的步骤包括:
1. **确定利益相关者**:识别那些会影响项目或受项目影响的人。
2. **访谈和问卷**:收集利益相关者的需求和期望。
3. **编写故事**:创建简洁明了的用户故事,它们通常以“作为一个[角色],我想要[目标],以便于[收益]”的格式编写。
## 5.2 开发与测试
### 5.2.1 代码编写最佳实践
在Python项目中,遵循一定的代码编写最佳实践能够提高代码的可读性、可维护性和可扩展性。
1. **命名规范**:类名应使用大驼峰式(CamelCase),变量和函数使用小驼峰式或下划线命名法。
2. **代码简洁性**:尽量保持代码行简洁,避免过长的代码行。
3. **注释与文档**:添加清晰的注释和完善的文档,帮助他人理解代码的用途和功能。
### 5.2.* 单元测试与集成测试策略
单元测试是软件测试中的一种,它针对代码中的最小单元进行检查和验证。单元测试能够保证代码的改动不会破坏现有的功能。
集成测试则是在单元测试之后进行的,它确保不同的代码单元按照设计要求组合在一起后能够正常工作。
测试策略应包括:
1. **编写测试用例**:为每个功能编写一个或多个测试用例。
2. **选择测试框架**:例如使用pytest或unittest等。
3. **持续集成**:将测试集成到持续集成/持续部署(CI/CD)流程中,确保代码的持续质量。
### 代码块示例与逻辑分析
```python
def add(a, b):
"""Add two numbers and return the result.
Args:
a (int): First number
b (int): Second number
Returns:
int: Sum of a and b
"""
return a + b
# 单元测试示例
def test_add():
assert add(2, 3) == 5
assert add(-1, 1) == 0
print("All tests passed.")
test_add()
```
在这个简单的示例中,`add` 函数用于计算两个数字的和。我们编写了相应的单元测试 `test_add` 函数,使用了 `assert` 语句来确保函数的行为符合预期。如果测试失败,将会抛出一个异常,并且可以提供附加的调试信息。如果测试通过,将输出 "All tests passed."。
## 5.3 部署与维护
### 5.3.1 部署流程与自动化部署
在项目开发完成后,代码需要被部署到服务器上供用户使用。自动化部署是指使用工具或脚本自动完成部署流程,减少人为错误,提高部署效率。
自动化部署流程通常包括:
1. **代码检出**:自动从版本控制系统中检出最新的代码。
2. **依赖安装**:自动安装项目所需的所有依赖。
3. **数据库迁移**:自动处理数据库的版本管理。
4. **应用启动**:自动启动应用,确保其在服务器上正常运行。
### 5.3.2 持续集成/持续部署(CI/CD)
CI/CD 是现代软件开发实践中,提升开发效率和软件质量的重要环节。持续集成(CI)指的是频繁地(一天多次)将代码集成到主干,而持续部署(CD)指的是自动化将代码部署到生产环境。
CI/CD 的好处包括:
1. **快速反馈**:在开发过程中及时发现和修复错误。
2. **自动化测试**:自动化执行测试,保证代码质量。
3. **版本控制**:管理代码的不同版本,易于回滚。
### 表格示例
| 部署策略 | 优点 | 缺点 |
|---------|------|------|
| 手动部署 | 对于小型项目简单快捷 | 效率低下,容易出错,难以扩展 |
| 自动化部署 | 高效、一致、可靠 | 初始设置较为复杂,需要专业知识 |
| 持续集成 | 持续保证软件质量,快速发现问题 | 需要持续的维护和监控 |
| 持续部署 | 确保代码快速更新到生产环境 | 需要自动化测试确保稳定性 |
以上表格展示了不同部署策略的优缺点,可以帮助项目团队选择适合的部署方式。
### mermaid 流程图
```mermaid
graph LR
A[开始部署] --> B{检查环境}
B -- 通过 --> C[检出代码]
B -- 失败 --> Z[部署失败]
C --> D[安装依赖]
D --> E[运行测试]
E -- 测试成功 --> F[部署到生产环境]
E -- 测试失败 --> Z
F --> G[部署成功]
```
流程图描述了自动化部署的步骤,以及如何根据不同的条件分支到不同的结果。
通过本章节的介绍,我们了解了在实际的Python项目中,从项目构思到部署维护的完整流程。每个环节都至关重要,缺一不可。实践是检验真理的唯一标准,通过不断的项目实践,不仅可以提高个人技术能力,还能够学会如何管理和运营项目,为未来的职业发展奠定坚实的基础。
# 6. Python面试技巧与准备
面试是每个求职者必须经历的重要环节,尤其对于技术职位来说,面试不仅仅是考察技术能力,更是沟通、表达和逻辑思维能力的考验。在Python面试中,如何突出自己的优势、展示自己的项目经验、并有效回答技术问题至关重要。这一章节将深入探讨Python面试技巧与准备,帮助求职者更好地应对挑战。
## 6.1 面试准备与简历制作
面试前的准备对于成功应聘至关重要。这部分将详细介绍如何撰写一份让面试官眼前一亮的简历,以及面试前应该做哪些准备。
### 6.1.1 简历撰写技巧与要点
简历是求职者给面试官的第一印象,一份好的简历应该简洁明了,突出自己的优势和与职位相关的经历。
- **个人信息**:确保包含你的全名、联系方式和LinkedIn个人资料链接。
- **职业目标**:简洁地描述你的职业方向和求职目标。
- **技术技能**:列出你熟练掌握的Python技术栈和相关工具。
- **项目经验**:描述关键项目,用动词开头来突出你的贡献。
- **教育背景**:列出最高学历及所学相关课程。
- **工作经验**:按时间顺序列出工作经历,突出在Python项目中的角色和成就。
### 6.1.2 面试前的准备工作
面试前的准备包括对职位要求的理解、对应聘公司的研究、以及技术问题的复习。
- **职位要求**:阅读职位描述,了解应聘职位所需的技术和软技能要求。
- **公司背景**:研究公司的背景、文化、产品及服务,以展示你对该公司的兴趣和了解。
- **技术复习**:回顾Python基础知识、框架和工具,准备几个与职位相关的项目案例。
## 6.2 应对技术面试
技术面试是检验应聘者技术能力的重要环节,掌握面试技巧和准备充足的案例对顺利通过面试至关重要。
### 6.2.1 技术问题的回答策略
回答技术问题时,清晰的思路和条理是关键。
- **理解问题**:确保你完全理解了问题,必要时可以向面试官寻求澄清。
- **分步解答**:将复杂问题分解为几个简单的步骤,逐一解决。
- **代码示例**:对于编程问题,可以提供伪代码或简单示例来说明你的思路。
- **最佳实践**:展示你如何应用最佳实践和设计模式解决问题。
- **测试案例**:提供测试用例来展示代码的健壮性。
### 6.2.2 代码面试技巧与注意事项
代码面试通常需要在白板或计算机上进行,有效展示你的编码能力很重要。
- **环境熟悉**:如果有机会,提前熟悉面试中可能使用的编程环境和工具。
- **代码清晰**:编写可读性强的代码,使用有意义的变量名和注释。
- **调试能力**:演示你的调试技巧,即使代码出现问题也要保持冷静。
- **沟通交流**:边写代码边解释你的思路,这可以帮助面试官理解你的思路。
## 6.3 面试后的跟进与反馈
面试结束后,并不意味着整个应聘过程的结束。面试后的跟进和反馈也是重要的环节。
### 6.3.1 面试后的感谢信
发送一封感谢信,表示你对面试机会的感谢以及再次强调你对该职位的兴趣。
- **及时性**:最好在面试结束后的24小时内发送。
- **个性化**:提到面试中的特定问题或与面试官的对话,表明你很重视这次面试。
- **简洁性**:信件内容要简洁明了,避免冗长。
### 6.3.2 对反馈的处理与改进
根据面试反馈,找出自己的不足之处,并制定改进计划。
- **客观分析**:即使没有获得职位,也要客观分析面试中的表现,找出可以提高的地方。
- **积极改进**:针对反馈制定改进措施,并在下一个面试中展现进步。
通过以上章节的内容,我们可以看出面试准备的重要性以及在面试过程中所需掌握的技巧。接下来的章节将会探讨在实际工作中如何高效利用Python进行项目开发和维护。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
Python全面面试题专栏是一个全面的指南,涵盖了Python面试中常见的各种主题。它包括算法、网络编程、并发编程、数据分析、机器学习、项目经验、性能优化、异步编程、测试和消息队列。专栏深入探讨了这些主题,提供了清晰的解释、代码示例和面试技巧。通过研究本专栏,求职者可以全面了解Python面试中可能遇到的问题,并提高他们在面试中的表现。该专栏旨在帮助求职者在竞争激烈的Python职位市场中脱颖而出,并获得他们梦寐以求的工作。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
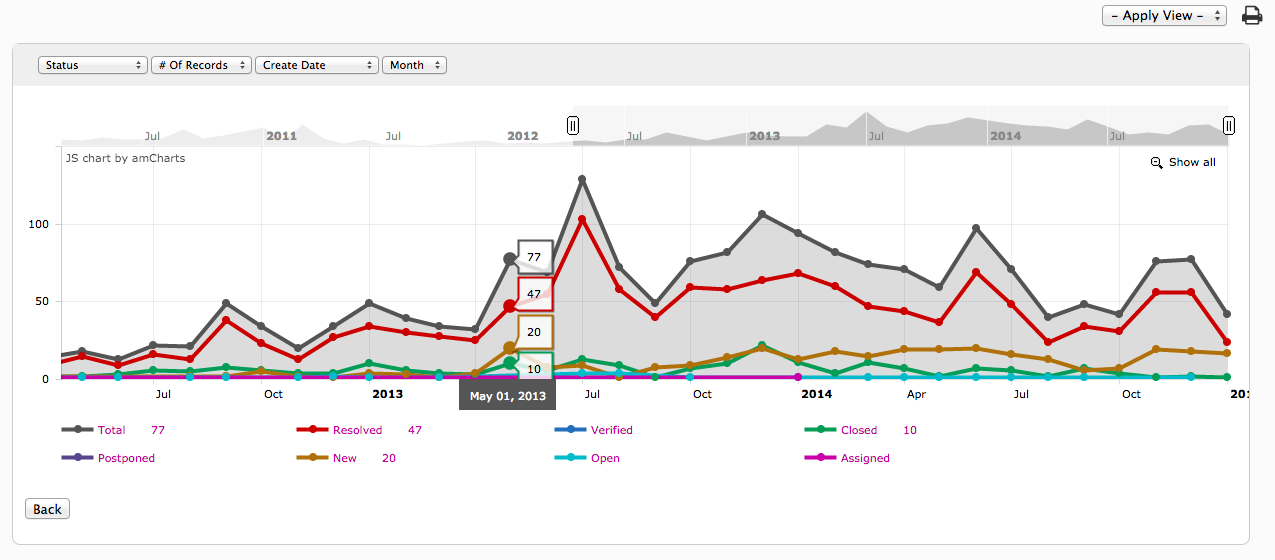
Catia曲线曲率分析深度解析:专家级技巧揭秘(实用型、权威性、急迫性)
# 摘要
本文全面介绍了Catia软件中曲线曲率分析的理论、工具、实践技巧以及高级应用。首先概述了曲线曲率的基本概念和数学基础,随后详细探讨了曲线曲率的物理意义及其在机械设计中的应用。文章第三章和第四章分别介绍了Catia中曲线曲率分析的实践技巧和高级技巧,包括曲线建模优化、问题解决、自动化定制化分析方法。第五章进一步探讨了曲率分析与动态仿真、工业设计中的扩展应用,以及曲率分析技术的未来趋势。最后,第六章对Catia曲线曲率分析进行了
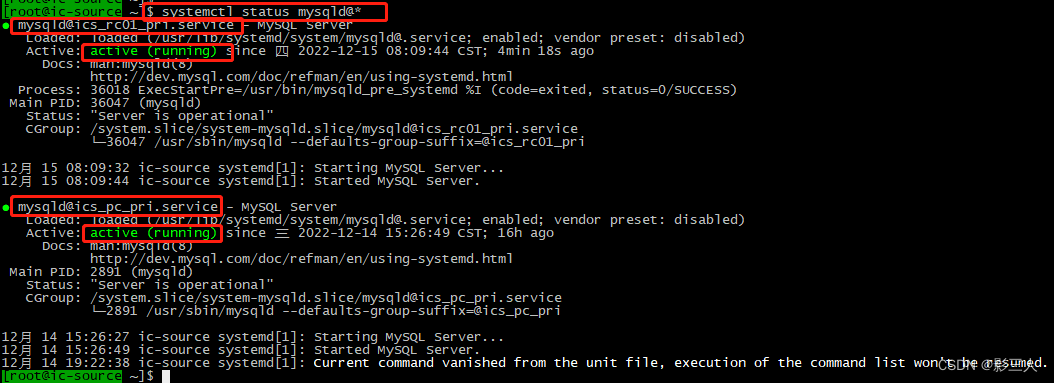
【MySQL日常维护】:运维专家分享的数据库高效维护策略
# 摘要
本文全面介绍了MySQL数据库的维护、性能监控与优化、数据备份与恢复、安全性和权限管理以及故障诊断与应对策略。首先概述了MySQL基础和维护的重要性,接着深入探讨了性能监控的关键性能指标,索引优化实践,SQL语句调优技术。文章还详细讨论了数据备份的不同策略和方法,高级备份工具及技巧。在安全性方面,重点分析了用户认证和授权机制、安全审计以及防御常见数据库攻击的策略。针对故障诊断,本文提供了常
EMC VNX5100控制器SP硬件兼容性检查:专家的完整指南

# 摘要
本文旨在深入解析EMC VNX5100控制器的硬件兼容性问题。首先,介绍了EMC VNX5100控制器的基础知识,然后着重强调了硬件兼容性的重要性及其理论基础,包括对系统稳定性的影响及兼容性检查的必要性。文中进一步分析了控制器的硬件组件,探讨了存储介质及网络组件的兼容性评估。接着,详细说明了SP硬件兼容性检查的流程,包括准备工作、实施步骤和问题解决策略。此外
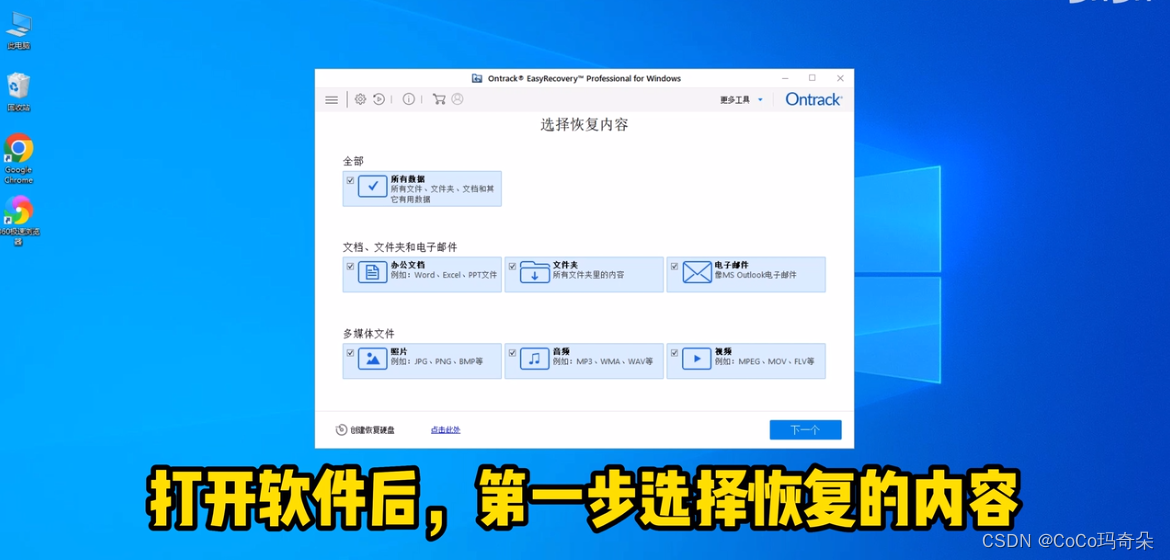
【IT专业深度】:西数硬盘检测修复工具的专业解读与应用(IT专家的深度剖析)
# 摘要
本文旨在全面介绍硬盘的基础知识、故障检测和修复技术,特别是针对西部数据(西数)品牌的硬盘产品。第一章对硬盘的基本概念和故障现象进行了概述,为后续章节提供了理论基础。第二章深入探讨了西数硬盘检测工具的理论基础,包括硬盘的工作原理、检测软件的分类与功能,以及故障检测的理论依据。第三章则着重于西数硬盘修复工具的使用技巧,包括修复前的准备工作、实际操作步骤和常见问题的解决方法。第四章与第五章进一步探讨了检测修复工具的深入应
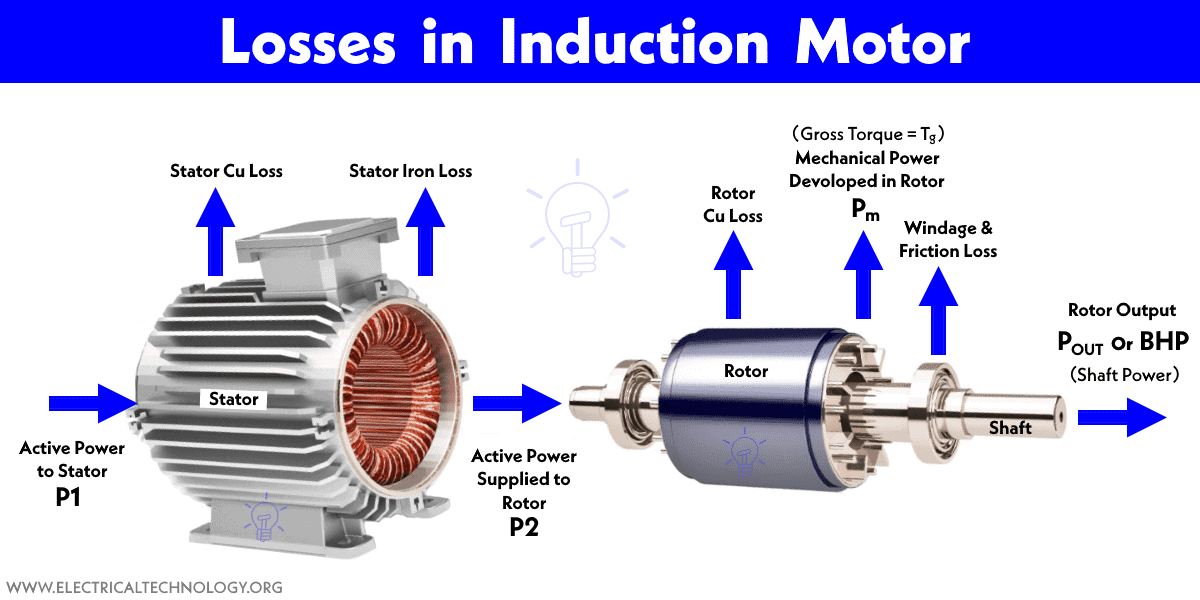
【永磁电机热效应探究】:磁链计算如何影响电机温度管理
# 摘要
本论文对永磁电机的基础知识及其热效应进行了系统的概述。首先,介绍了永磁电机的基本理论和热效应的产生机制。接着,详细探讨了磁链计算的理论基础和计算方法,以及磁链对电机温度的影响。通过仿真模拟与分析,评估了磁链计算在电机热效应分析中的应用,并对仿真结果进行了验证。进一步地,本文讨论了电机温度管理的实际应用,包括热效应监测技术和磁链控制策略的
【代码重构在软件管理中的应用】:详细设计的革新方法

# 摘要
代码重构是软件维护和升级中的关键环节,它关注如何提升代码质量而不改变外部行为。本文综合探讨了代码重构的基础理论、深
【SketchUp设计自动化】

# 摘要
本文系统地探讨了SketchUp设计自动化在现代设计行业中的概念与重要性,着重介绍了SketchUp的基础操作、脚本语言特性及其在自动化任务中的应用。通过详细阐述如何通过脚本实现基础及复杂设计任务的自动化
【CentOS 7时间同步终极指南】:掌握NTP配置,提升系统准确性
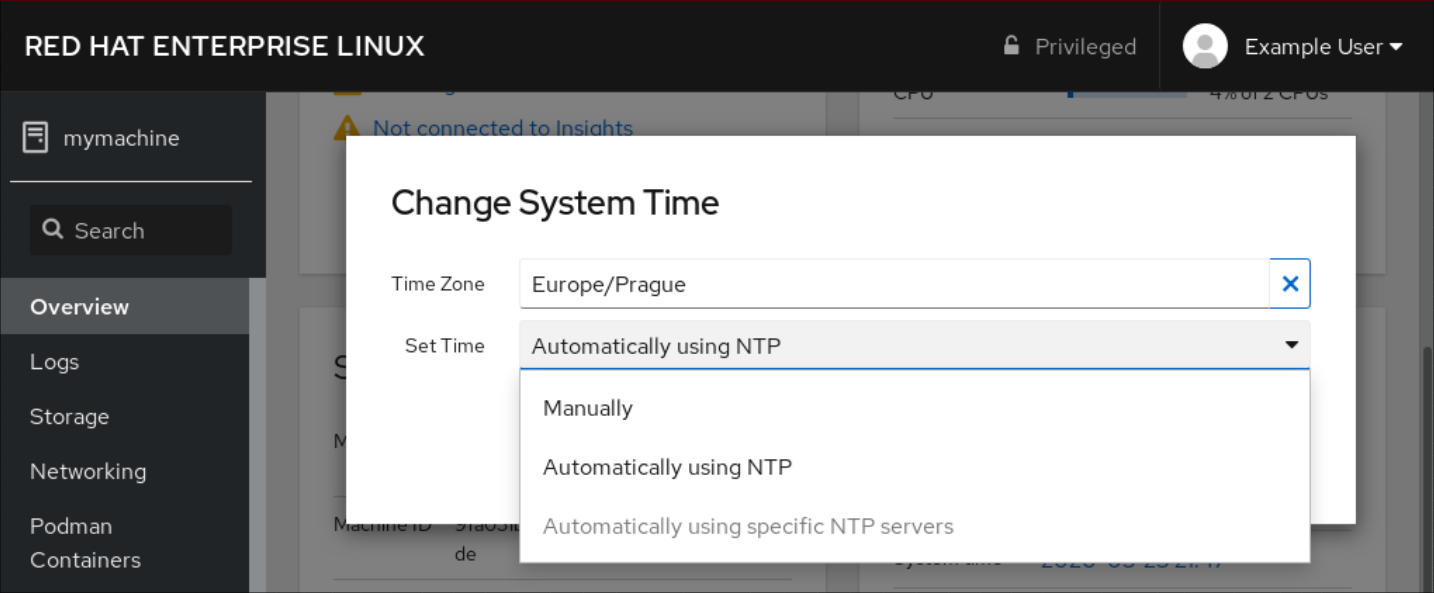
# 摘要
本文深入探讨了CentOS 7系统中时间同步的必要性、NTP(Network Time Protocol)的基础知识、配置和高级优化技术。首先阐述了时
轮胎充气仿真深度解析:ABAQUS模型构建与结果解读(案例实战)

# 摘要
轮胎充气仿真是一项重要的工程应用,它通过理论基础和仿真软件的应用,能够有效地预测轮胎在充气过程中的性能和潜在问题。本文首先介绍了轮胎充气仿真的理论基础和应用,然后详细探讨了ABAQUS仿真软件的环境配置、工作环境以及前处理工具的应用。接下来,本文构建了轮胎充气模型,并设置了相应的仿真参数。第四章分析了仿真的结果,并通过后处理技术和数值评估方法进行了深入解读。最后,通过案例实战演练,本文演示了
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )