【R语言GPU加速实战指南】:代码优化与性能提升的10大策略


dawe_01_1108.pdf
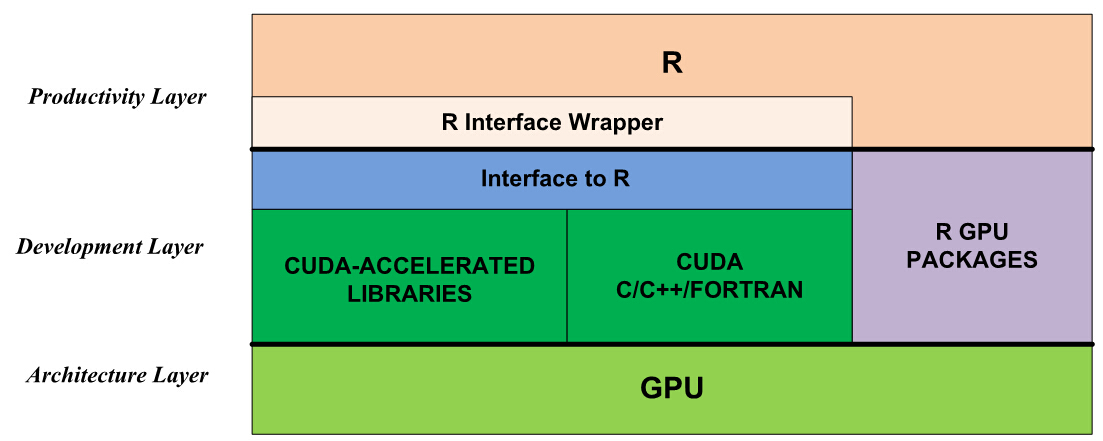
1. R语言GPU加速概述
R语言作为一种强大的统计编程语言,一直以来都因其出色的分析和可视化能力而受到数据科学家们的青睐。然而,随着数据分析的规模不断扩大,R语言处理大规模数据集时的性能成为了瓶颈。为了解决这一问题,引入了GPU加速技术,以期通过图形处理单元的强大并行处理能力来大幅提升计算效率。
GPU加速利用了GPU中成百上千的处理器核心,这些核心可以同时执行成千上万个线程,显著提高了处理数据的速度。在R语言中应用GPU加速,意味着可以从原本受限的单核处理器中解放出来,进行更加高效的数据处理和复杂模型的计算,尤其在涉及重复迭代和矩阵操作的统计计算中效果显著。
本章节将首先介绍GPU加速的基本概念,解释它在不同应用领域的重要性,并梳理目前R语言中支持GPU加速的扩展包和库,为读者理解GPU在R语言中的作用打下基础。随着后续章节的深入探讨,读者将掌握如何在R语言中运用GPU加速技术,以及如何优化相关代码以实现最佳性能。
2. R语言GPU加速基础
2.1 R语言与GPU计算框架的集成
2.1.1 GPU加速的概念及应用领域
GPU加速是一种利用图形处理单元(GPU)来进行科学计算的技术,尤其适用于那些高度并行的计算任务。通过将复杂的计算任务并行化,GPU能够显著提高计算速度,这在数据科学、机器学习、深度学习、生物信息学、金融建模等领域有着广泛的应用。
现代的GPU拥有成百上千个核心,能够同时处理大量的数据,这种并行处理能力是传统CPU无法比拟的。为了实现GPU加速,开发者需要使用特定的GPU计算框架,如CUDA(Compute Unified Device Architecture)或OpenCL(Open Computing Language)。这些框架提供了在GPU上编程的能力,使得开发者能够编写能在GPU上运行的并行程序。
在R语言中,集成GPU加速功能意味着能够使用R语言直接调用GPU资源进行复杂的数据处理和分析任务。这不仅能够加快数据分析的速度,也能够处理以往由于资源限制而无法处理的大量数据。
2.1.2 R语言中支持GPU加速的包与库
为了在R语言中使用GPU加速,开发者可以利用一些专门为此目的设计的R包。一些常用的R包包括:
gputools:提供了一些在GPU上运行的通用数学和统计功能,如矩阵运算等。rcuda:允许R用户通过CUDA调用GPU上的函数。arrayfire:封装了一个高性能的GPU计算库,可以在R中进行高效的数组操作。gpuR:是一个提供GPU加速计算的R接口,支持CUDA和OpenCL。
这些包的设计和实现依赖于底层的GPU计算框架,如CUDA或OpenCL。使用这些包,R语言用户可以在不需要深入了解GPU编程的复杂性的情况下,简单地通过R语法来利用GPU的强大计算能力。
2.2 GPU加速的理论基础
2.2.1 GPU架构与并行计算原理
GPU架构由数以百计的小型、高效的核心组成,专门设计用来处理图形和并行计算任务。与传统的CPU相比,GPU拥有更多的处理单元,能够同时处理大量数据。
在GPU架构中,每个核心都是一个简化版的CPU,它们能够独立执行相同的指令。这种结构称为单指令多数据(SIMD)模型。在SIMD模型下,一个操作指令会被广播到多个核心,核心并行执行该操作。这种设计使得GPU非常适合执行如向量和矩阵运算这样的并行计算任务。
并行计算原理强调的是将任务分解成可以并行执行的小块。在GPU上,这意味着将大的数据集或计算任务分割成许多小块,然后在多个核心上同时执行这些小块。这种并行处理可以极大提高计算效率,尤其是在处理大规模数据时。
2.2.2 数据在GPU中的存储与传输
由于GPU与CPU在架构上的巨大差异,数据在GPU中的存储和传输也具有其特殊性。GPU拥有自己的内存(显存),与CPU的系统内存是独立的。这意味着在进行GPU加速计算时,数据需要从系统内存传输到显存中,计算完成后又需要将结果传回系统内存。
数据在GPU和CPU间的传输需要通过PCI Express(PCIe)总线进行,这一过程相比内存访问来说相对较慢,因此优化数据传输是GPU加速中非常重要的一个环节。对于频繁在CPU和GPU之间传输数据的程序,开发者需要尽可能减少这种传输操作,或者使用异步传输技术,以免造成GPU处理单元的空闲等待。
在R语言中使用GPU进行加速时,合理管理内存是提高性能的关键。开发者需要理解数据如何在CPU和GPU之间传输,如何在GPU内部进行存储和访问,这样才能充分挖掘GPU加速的潜力。
2.3 初识R中的GPU编程
2.3.1 R中的CUDA编程示例
CUDA是NVIDIA推出的并行计算平台和编程模型,允许开发者利用NVIDIA GPU进行通用计算。在R语言中,可以通过rcuda包来使用CUDA进行GPU编程。
以下是一个简单的CUDA编程示例,展示了如何在R中使用CUDA进行向量加法运算:
- # 安装并加载rcuda包
- install.packages("rcuda")
- library(rcuda)
- # 初始化CUDA环境
- init_cuda()
- # 分配内存空间给输入向量x、y和结果向量z
- x <- cudaMalloc(dim=10)
- y <- cudaMalloc(dim=10)
- z <- cudaMalloc(dim=10)
- # 初始化向量x和y的值
- setVector(x, 1:10)
- setVector(y, 10:1)
- # 定义CUDA核函数实现向量加法
- addVectors <- '
- extern "C" {
- __global__ void addVectors(int *x, int *y, int *z, int N) {
- int index = blockIdx.x * blockDim.x + threadIdx.x;
- int stride = blockDim.x * gridDim.x;
- for (int i = index; i < N; i += stride) {
- z[i] = x[i] + y[i];
- }
- }
- }
- '
- # 编译并运行核函数
- compile CUDA code
- addVectors <- cudaDeviceFunction(addVectors)
- # 执行核函数
- addVectors(dim=10, x=x, y=y, z=z, N=10)
- # 从GPU内存中获取结果向量z的值
- z_host <- getVector(z)
- # 清理分配的内存资源
- free(x)
- free(y)
- free(z)
- close_cuda()
- # 输出结果向量z
- print(z_host)
在这个示例中,首先初始化CUDA环境,然后为输入向量和结果向量分配GPU内存空间。接着定义一个CUDA核函数addVectors来执行向量加法。通过compile CUDA code和cudaDeviceFunction函数来编译并注册核函数。最后,调用核函数并从GPU内存中获取结果。
这段代码展示了如何在R语言中使用CUDA进行基本的GPU编程。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【机器人编程101】:入门到实践的完整指南
【联想SR650硬盘识别效率提升】:BIOS设置与系统更新的完美配合
【Kingston SSS6690SK6211 U盘量产:从入门到专家】:软件安装、高级设置与性能优化
【信号完整性的守护者】:如何精确匹配CAN总线中的120Ω终端电阻
OV3660传感器硬件布局与架构:图像质量的秘密揭晓
保护你的系统:EQ2013安全管理手册与最佳实践
【CAN协议2.0B规范】:3大特点与实现细节深度剖析
ACOM516安全最佳实践:权威指南保护设备与数据安全
Ansys在高速SerDes设计中的先进仿真技术:揭秘行业尖端技术


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )