TensorFlow与PyTorch对比:迁移学习在图像分类中的最佳框架选择
发布时间: 2024-09-03 16:00:05 阅读量: 138 订阅数: 46 

# 1. 迁移学习和深度学习框架概述
## 1.1 迁移学习基础
迁移学习是一种机器学习方法,它允许一个已经学习好的模型应用于新的但相关的问题。它减少了训练时间和数据需求,因为模型可以利用之前学习到的特征来加速新任务的学习过程。迁移学习在图像分类、自然语言处理和其他领域取得了巨大成功。
## 1.2 深度学习框架的重要性
深度学习框架为研究人员和开发者提供了一套高级API和工具,用于构建、训练和部署深度神经网络。流行的框架如TensorFlow、PyTorch、Keras等已经改变了深度学习项目的开发方式,它们通过优化性能和易用性来简化复杂的工作流程。
## 1.3 本章小结
在本章中,我们介绍了迁移学习的基础概念及其在深度学习中的作用。同时,我们强调了深度学习框架的重要性,它们不仅加速了模型的开发过程,还为研究提供了强大的工具。接下来的章节将分别深入探讨TensorFlow和PyTorch,以及它们在图像分类项目中的应用。
# 2. TensorFlow基础与图像分类
## 2.1 TensorFlow的基本构成和安装
### 2.1.1 TensorFlow的计算图和会话
在 TensorFlow 中,计算图(Graph)是所有计算过程的定义,它描述了各种张量(Tensor)之间的关系。图是由节点(Node)和边(Edge)组成的,节点代表操作(Operation),边代表在这些操作之间流动的数据。TensorFlow 支持在本地或云端进行复杂的数值计算,并且对这些计算进行优化。
会话(Session)用于运行 TensorFlow 计算图。它提供了环境,用于运行图中的操作,并将操作输出到张量变量。当你创建一个会话时,计算图中的操作会在会话中运行。会话分为两种:默认会话和非默认会话。
下面是一个简单的 TensorFlow 会话的使用示例:
```python
import tensorflow as tf
# 定义两个常量节点
a = tf.constant(2)
b = tf.constant(3)
# 定义一个加法操作,将 a 和 b 作为输入
addition = tf.add(a, b)
# 创建一个默认会话来运行图
with tf.Session() as sess:
# 运行加法操作,计算结果
result = sess.run(addition)
print(result) # 输出: 5
```
### 2.1.2 安装TensorFlow和环境配置
安装 TensorFlow 可以通过 Python 的包管理工具 pip 来完成。TensorFlow 提供了针对 CPU 和 GPU 的不同版本,安装前请确认你的系统环境。
在终端或命令提示符中,可以使用以下命令来安装 CPU 版本的 TensorFlow:
```bash
pip install tensorflow
```
如果要安装 GPU 版本的 TensorFlow,需要在你的系统中安装 CUDA 和 cuDNN,并且确保它们的版本与 TensorFlow 的版本兼容。然后使用以下命令安装:
```bash
pip install tensorflow-gpu
```
安装完成后,你可以使用 Python 的交互模式来确认 TensorFlow 是否安装正确:
```python
import tensorflow as tf
print(tf.__version__)
```
如果安装成功,上述代码会输出 TensorFlow 的版本号。
## 2.2 TensorFlow在图像分类中的应用
### 2.2.1 数据预处理和增强
在机器学习任务中,特别是图像分类,数据预处理是至关重要的一步。它包括缩放图像到统一尺寸、归一化像素值、增强数据集等操作。数据增强能够通过旋转、缩放、裁剪等方法人工扩展训练集,提高模型的泛化能力。
TensorFlow 提供了强大的数据处理工具,如 `tf.data` API,可以通过组合简单的操作来构建复杂的数据管道。下面是一个使用 `tf.data` API 进行数据预处理和增强的示例:
```python
import tensorflow as tf
# 创建一个数据集
dataset = tf.data.Dataset.from_tensor_slices((data, labels))
# 应用预处理和增强
dataset = dataset.map(lambda image, label: (tf.image.resize(image, [224, 224]), label))
# 数据增强,例如随机裁剪
def random_crop(image):
return tf.image.random_crop(image, size=[224, 224, 3])
dataset = dataset.map(lambda image, label: (random_crop(image), label))
# 打乱数据集
dataset = dataset.shuffle(buffer_size=10000)
# 批量化数据集
dataset = dataset.batch(batch_size=32)
```
### 2.2.2 构建卷积神经网络模型
卷积神经网络(CNN)是图像分类任务中的常用模型。在 TensorFlow 中,可以通过定义层的顺序和类型来构建 CNN 模型。`tf.keras` 是 TensorFlow 的高级API,它提供了构建和训练模型的简单而强大的方式。
构建一个简单的 CNN 模型可以按照以下步骤进行:
```python
import tensorflow as tf
# 构建一个序贯模型
model = tf.keras.models.Sequential([
# 卷积层
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(224, 224, 3)),
# 池化层
tf.keras.layers.MaxPooling2D(2, 2),
# Dropout层减少过拟合
tf.keras.layers.Dropout(0.25),
# Flatten层将多维输入一维化
tf.keras.layers.Flatten(),
# 全连接层
tf.keras.layers.Dense(128, activation='relu'),
# Dropout层
tf.keras.layers.Dropout(0.5),
# 输出层使用softmax激活函数
tf.keras.layers.Dense(10, activation='softmax')
])
# 编译模型
***pile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
```
### 2.2.3 训练和验证模型
在定义好模型后,接下来的步骤是使用训练数据来训练模型,并用验证数据来评估模型的性能。在 TensorFlow 中,可以使用模型的 `fit` 方法进行训练,并使用 `evaluate` 方法进行验证。
```python
# 训练模型
history = model.fit(train_dataset, epochs=10, validation_data=val_dataset)
# 评估模型
test_loss, test_acc = model.evaluate(test_dataset)
print('Test accuracy:', test_acc)
```
在训练过程中,`history` 对象会记录损失值和准确率等指标。这些记录可以帮助我们绘制训练曲线,并且有助于调试和优化模型。
## 2.3 TensorFlow模型的迁移学习
### 2.3.1 加载预训练模型
迁移学习的核心思想是利用在大规模数据集(如ImageNet)上预先训练好的模型来解决特定任务。在 TensorFlow 中,可以利用 `tf.keras.applications` 模块来加载预训练的模型。
```python
from tensorflow.keras.applications import MobileNetV2
# 加载预训练的 MobileNetV2 模型,不包括顶层的分类器
pretrained_model = MobileNetV2(weights='imagenet', include_top=False)
# 固定预训练模型的权重
for layer in pretrained_model.layers:
layer.trainable = False
```
### 2.3.2 微调和模型评估
加载完预训练模型之后,我们可以根据自己的数据集来微调模型。微调时,通常只调整模型的最后几层,因为这些层包含的是通用特征,而最后的分类器则与特定任务密切相关。微调过程中,模型的大部分权重保持不变,只更新顶层的权重。
```python
# 在预训练模型上添加新的分类层
x = pretrained_model.output
x = tf.keras.layers.GlobalAveragePooling2D()(x)
x = tf.keras.layers.Dense(1024, activation='relu')(x)
predictions = tf.keras.layers.Dense(num_classes, activation='softmax')(x)
# 构建最终的模型
model = tf.keras.Model(inputs=pretrained_model.input, outputs=predictions)
# 编译模型,这里使用一个较小的学习率
***pile(optimizer=tf.keras.optimizers.Adam(lr=1e-4),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 微调模型
history_fine = model.fit(train_dataset, epochs=10, validation_data=val_dataset)
```
模型微调后,使用与之前相同的评估方法来验证模型的性能:
```python
test_loss, test_acc = model.evaluate(test_dataset)
print('Test accuracy:', test_acc)
```
微调过程允许模型在保持已有知识的同时学习新任务的特征。通过这种方式,即使是有限的数据集也能训练出表现良好的模型。
# 3. PyTorch基础与图像分类
PyTorch是由Facebook的AI研究团队开发的开源机器学习库,它使用动态计算图,提供了极大的灵活性和易用性,尤其在研究社区中受到广泛欢迎。在本章节中,我们将深入探讨PyTorch的基础知识,并通过图像分类任务的实际应用,展示如何使用PyTorch构建和训练深度学习模型。同时,我们

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了迁移学习在图像分类中的应用,提供了全面而实用的指南。通过11个技巧,读者可以提高图像分类模型的准确率。专栏涵盖了迁移学习的优势、理论基础、最佳实践、挑战和应对策略,以及调优技巧。此外,还介绍了迁移学习与数据增强、领域自适应、特征对齐和深度学习相结合的应用。专栏深入分析了 TensorFlow 和 PyTorch 在迁移学习中的作用,并提供了医疗图像分析、自动驾驶和遥感图像分析等领域的实际应用。通过本专栏,读者将获得图像分类中迁移学习的全面知识,并掌握提升模型性能的实用技能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Proteus高级操作】:ESP32模型集成与优化技巧
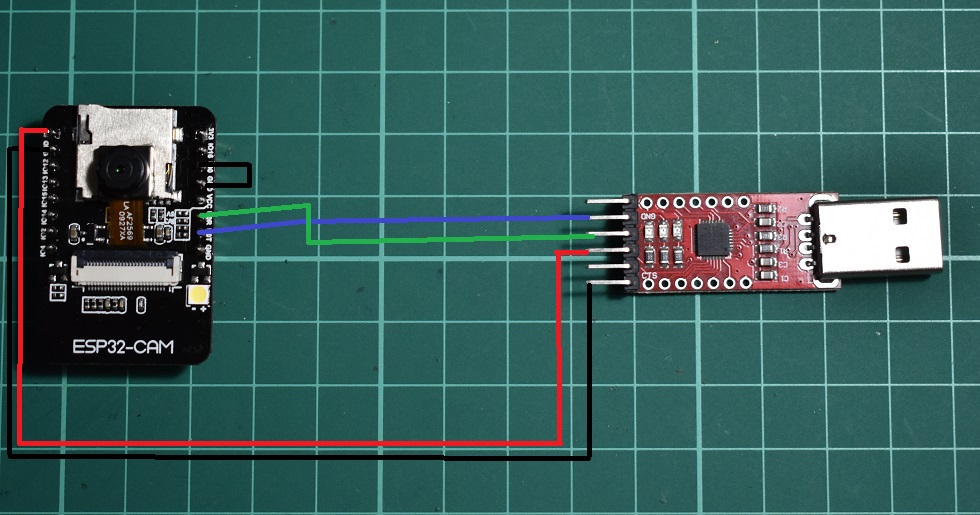
# 摘要
本文深入探讨了ESP32模型的集成与性能优化技巧,涉及理论基础、集成过程、系统性能优化以及高级功能的实现与应用。首先介绍了ESP32集成的准备工作,包括软件环境配置和硬件模型的导入。然后详细描述了硬件模拟、软件编程的集成过程,以及如何在Proteus中进行代码调试。接下来,文章着重讲述系统性能优化,涵盖电源管理、代码效率提升以及硬件与固件的协同优化。此外,还介绍了ESP
自动控制原理课件深度分析:王孝武与方敏的视角
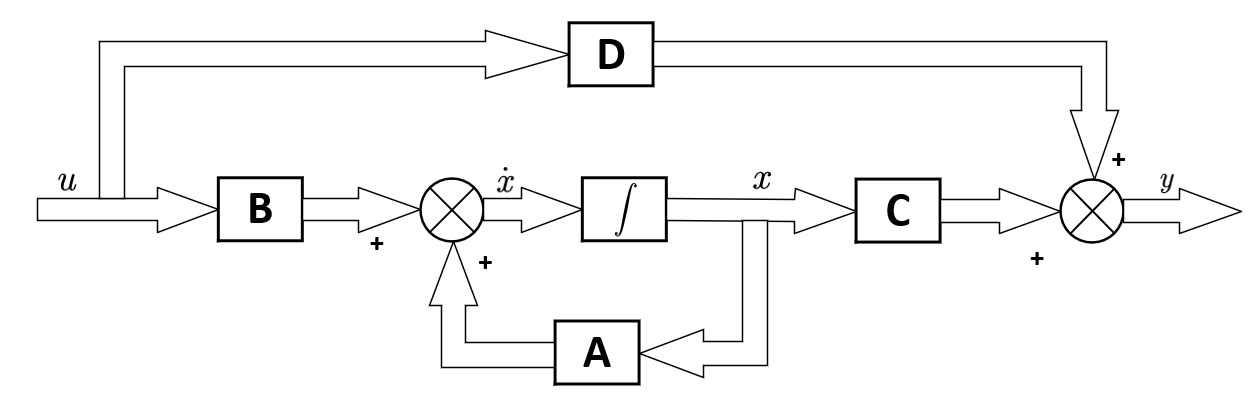
# 摘要
本文对自动控制原理课程进行了全面的概述,重点探讨了控制系统的基本理论,包括线性系统分析、非线性系统与混沌现象、以及控制器设计的原则与方法。随后,文章引入了控制理论的现代方法,如状态反馈、鲁棒控制、自适应控制以及智能控制算法,并分析了其在实际应用中的重要性。此外,本文还详细介绍了控制系统的软件实现与仿真,以及如何利用常用软件工具如MATLAB、Simulink和LabVIEW进行控制工
【QSPr工具全方位攻略】:提升高通校准综测效率的10大技巧
# 摘要
本文旨在全面介绍QSPr工具,该工具基于高通综测技术,具备强大的校准流程和高效的数据处理能力。首先,从理论基础出发,详细阐述了QSPr工具的工作原理和系统架构,强调了校准流程和系统集成的重要性。随后,针对实践技巧进行了深入探讨,包括如何高效设置、配置QSPr工具,优化校准流程,以及如何进行数据分析和结果解读。在高级应用章节,本文提供了自动化脚本编写、第三方工具集成和性能监
【鼎捷ERP T100性能提升攻略】:让系统响应更快、更稳定的5个方法
# 摘要
鼎捷ERP T100系统在面对高性能挑战时,需要从硬件、数据库和软件等多方面进行综合优化。本文首先概述了ERP T100系统的特点及性能挑战。随后,重点探讨了硬件优化策略,包括硬件升级的必要性、存储系统与内存管理的优化。在数据库性能调优方面,本文提出了结构优化、查询性能提升和事务处理效率增强的方法。此外,还分析了软件层面的性能提升手段,如ERP软件配置优化、业务流程重组与简化
STM32F334外设配置宝典:掌握GPIO, ADC, DAC的秘诀

# 摘要
本文全面介绍STM32F334微控制器的基础知识,重点阐述了GPIO、ADC和DAC外设的配置及实践操作,并通过应用实例深入分析了其在项目中的运用。通过系统配置策略、调试和性能优化的讨论,进一步探索了在综合应用中的系统优化方法。最后,结合实际项目案例,分享了开发过程中的经验总结和技巧,旨在为工程师在微
跨平台开发者必备:Ubuntu 18.04上Qt 5.12.8安装与调试秘籍
# 摘要
本文针对Ubuntu系统环境下Qt 5.12.8的安装、配置及优化进行了全面的流程详解,并深入探讨了跨平台开发实践技巧与案例研究。首先,介绍了系统环境准备和Qt安装流程,强调了官方源与第三方源的配置及安装过程中的注意事项。随后,文章详细阐述了Qt Creator的环境配置、编译器与工具链设置,以及性能调优和内存管理技术。在跨平台开发部分,本文提出了有效的项目配置、界面设
【多云影像处理指南】:遥感图像去云算法实操与技巧
# 摘要
本文全面探讨了多云影像处理的理论与实践,从遥感影像的云污染分析到去云算法的分类原理、性能评估,再到实际操作的技巧和案例研究。重点介绍了遥感影像去云的重要性、常用去云软件工具、操作流程以及后处理技术。同时,文章也研究了多云影像处理在农业、城市规划和灾害监测中的应用,并讨论了人工智能技术如何优化去云算法,展望了多云影像处理的未来趋势和面临的挑战。通过对多云影像处理技术的深入剖析
波形发生器频率控制艺术

# 摘要
波形发生器作为电子工程中的关键组件,其技术进步对频率控制领域产生了深远影响。本文综合概述了波形发生器技术,深入探讨了频率控制的基础理论,包括频率与波形生成的关系、数字频率控制理论以及频率合成技术。在实践应用部分,详细分析了频率调整的硬件和软件实现方法,以及提高频率控制精确度和稳定性的技术。先进方法章节讨论了自适应和智能化频率调整方法,以及多波形系统
延长标签寿命:EPC C1G2协议的能耗管理秘籍
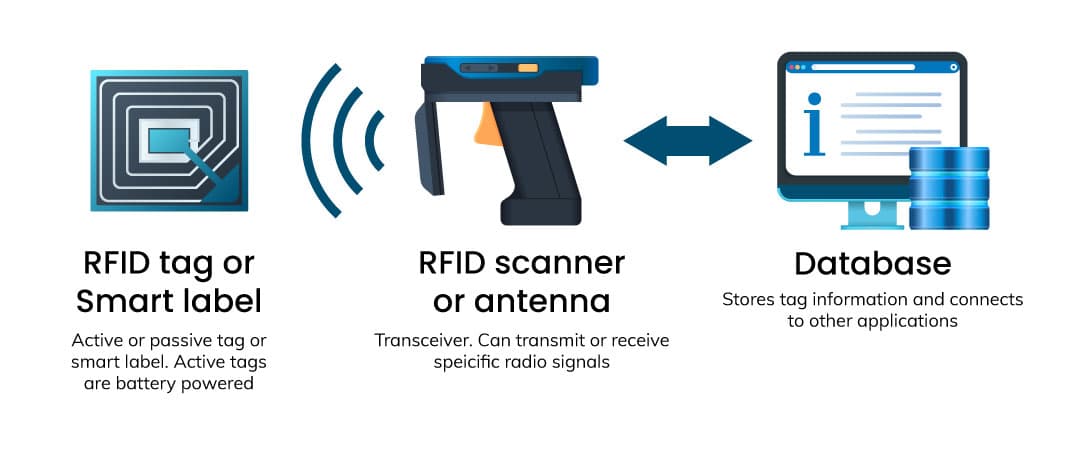
# 摘要
本文针对EPC C1G2协议在实际应用中面临的能耗问题进行了深入研究,首先介绍了EPC C1G2协议的基本概念及能耗问题现状。随后,构建了基于EPC C1G2协议架构的能耗模型,并详细分析了通信过程中关键能耗因素。通过理论与实践相结合的方式,本文探讨了静态和动态节能技术,并对EPC C1G2标签的寿命延长技术进行了实验设计和评估。最后,文章展望了EPC C1G2协议能耗管理的未来趋势,
【热参数关系深度探讨】:活化能与其他关键指标的关联

# 摘要
本论文对热化学动力学中一个核心概念——活化能进行系统性探讨。首先介绍了活化能的基本理论及其在化学反应中的重要性,随后详述了活化能的计算方法,包括阿伦尼乌斯方程以及实验技术的应用。本文深入分析了活化能与其他动力学参数如速率常数、反应焓变和熵的关系,并探讨了在工业化学反应和新能源领域中活化能的应用与优化。此外,文中还讨论了现代实验技术在活化能测定中的重要性以及实
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )