掌握深度学习框架:Python TensorFlow基础与进阶
发布时间: 2024-12-06 14:42:07 阅读量: 11 订阅数: 17 
# 1. 深度学习与TensorFlow概述
在当今的数据科学领域,深度学习作为人工智能的一个分支,已经渗透到各行各业,引领着科技发展的前沿。TensorFlow,作为谷歌开发的开源机器学习框架,因其灵活性、可扩展性和易用性,成为深度学习领域研究和应用的首选工具。本章旨在为读者提供深度学习以及TensorFlow的入门级介绍,让我们一起揭开深度学习与TensorFlow的神秘面纱。
## 1.1 深度学习基础概念
深度学习是一种模拟人脑神经网络结构和功能,进行学习和决策的算法。它通过多层的神经网络来处理复杂的数据模式和关系。从图像识别、语音识别到自然语言处理,深度学习技术都展现出了其强大的学习能力和泛化性能。
## 1.2 TensorFlow的起源与特点
TensorFlow于2015年发布,它的名字来源于操作数据流图中的多维数组(张量)。TensorFlow之所以受到业界的青睐,主要归功于其以下特点:
- **灵活性**:支持多种深度学习模型,方便研究者和开发人员进行实验。
- **可扩展性**:无论是小规模的实验还是大规模的生产环境,TensorFlow都能胜任。
- **跨平台性**:支持从单个CPU到GPU和TPU的计算资源,能在多种操作系统上运行。
## 1.3 TensorFlow的市场地位与发展
随着人工智能的不断进步,TensorFlow也逐步完善和升级,形成了一个庞大的生态系统。它不仅是科研人员实验的利器,也是企业在生产环境中部署深度学习模型的首选。随着越来越多的教程、工具和社区支持的出现,TensorFlow的市场地位日益稳固,其发展和应用前景广阔。
通过本章的介绍,我们已经对深度学习和TensorFlow有了一个基础的认识。接下来的章节将深入探讨TensorFlow的安装、基本操作和构建神经网络的具体方法。无论你是深度学习的新手还是希望进一步提高技能的专业人士,都可以跟随我们的脚步,一步步深入TensorFlow的世界。
# 2. TensorFlow基础入门
## 2.1 TensorFlow的安装与配置
### 2.1.1 环境要求与安装步骤
对于任何深度学习项目而言,安装和配置开发环境是第一步。TensorFlow适用于多种环境,包括Linux、macOS和Windows。开发人员需要Python环境,并且最好是安装了Anaconda,因为Anaconda环境可以简化安装过程,并且管理不同版本的包。
安装TensorFlow前,请确保你的计算机满足以下基本要求:
- Python版本3.6及以上
- 64位操作系统
- 至少12GB的RAM(推荐)
接下来,安装TensorFlow的推荐步骤如下:
1. **创建虚拟环境**(可选,但推荐),以避免包冲突:
```bash
conda create -n tf_env python=3.7
conda activate tf_env
```
2. **使用pip安装TensorFlow**:
```bash
pip install tensorflow
```
或者使用conda进行安装:
```bash
conda install tensorflow
```
3. **验证安装**。通过运行以下Python代码,确认安装成功:
```python
import tensorflow as tf
print(tf.__version__)
```
如果没有错误发生,并且打印出了TensorFlow版本,说明你的安装是成功的。
### 2.1.2 TensorFlow版本对比与选择
TensorFlow自发布以来,经历了多次版本迭代,当前稳定版为2.x系列。在选择版本时,需要考虑以下几点:
- **稳定性**:较新的版本往往解决了早期版本的bug,同时可能引入新的特性。
- **功能**:最新版本会不断添加新的API和功能,但可能需要时间让社区消化和适应。
- **社区支持**:更老旧的版本可能失去官方的更新支持,但通常拥有更广泛的社区文档和教程。
- **兼容性**:某些旧项目或教程可能只支持老版本的TensorFlow。
一个稳妥的建议是,如果是新项目或学习使用,应选择最新稳定版。但对于依赖特定版本API的旧项目,应保持现有版本不变,或寻找合适的迁移方案。
## 2.2 TensorFlow中的张量操作
### 2.2.1 张量的数据类型和属性
张量是TensorFlow的基础,它是一种多维数组,用于表示数据中的大量元素。在TensorFlow中,张量不仅包含数据类型,还包含了数据所在的设备信息。
张量的数据类型通常包括:
- `float16`, `float32`, `float64`:浮点数,用于存储带小数的数值。
- `int8`, `int16`, `int32`, `int64`:整数,用于存储整数。
- `string`:字符串类型。
- `bool`:布尔值,表示True或False。
- `complex64`, `complex128`:复数类型,用于复数的计算。
张量的属性包括:
- **Rank**:张量的维数,即张量的维度大小。
- **Shape**:一个整数的元组,用于表示张量每个维度上的元素数量。
- **Data type**:张量内数据的类型,如上所示。
操作张量属性的代码如下:
```python
import tensorflow as tf
# 创建一个张量
tensor = tf.constant([[1, 2], [3, 4]])
# 获取张量的属性
rank = tensor.shape.rank # Rank 2
shape = tensor.shape # [Dimension(2), Dimension(2)]
dtype = tensor.dtype # tf.int32
```
### 2.2.2 张量的创建、运算和形状操作
张量的创建方式很多,包括直接定义、使用现有的Numpy数组或从数据集生成。创建后,可以执行各种运算,如元素间的加减乘除等,以及改变形状等操作。
- **创建张量**:
```python
# 从Numpy数组创建
import numpy as np
np_array = np.array([[1, 2], [3, 4]])
tensor = tf.convert_to_tensor(np_array)
```
- **张量的运算**:
```python
# 张量间的加法
tensor1 = tf.constant([[1, 2], [3, 4]])
tensor2 = tf.constant([[5, 6], [7, 8]])
result = tf.add(tensor1, tensor2)
```
- **改变张量形状**:
```python
# 使用reshape改变形状
tensor = tf.constant([[1, 2, 3], [4, 5, 6]])
reshaped_tensor = tf.reshape(tensor, [3, 2])
```
## 2.3 构建神经网络基础
### 2.3.1 激活函数与网络层
激活函数在网络中负责加入非线性因素,使得神经网络能够学习复杂的函数映射。常见的激活函数包括ReLU、Sigmoid和Tanh等。
在TensorFlow中,可以很容易地将激活函数集成到网络层中。例如,在Keras API中,一个带有ReLU激活函数的全连接层(Dense Layer)可以表示为:
```python
from tensorflow.keras.layers import Dense
# 创建一个具有ReLU激活函数的全连接层
dense_layer = Dense(units=128, activation='relu')
```
### 2.3.2 损失函数与优化器
损失函数用于衡量模型预测值与真实值之间的差异。优化器负责更新网络权重,以便最小化损失函数。常见的损失函数有均方误差(MSE)和交叉熵损失。常见的优化器则包括SGD、Adam和RMSprop等。
在Keras中,损失函数和优化器通常在模型编译阶段指定:
```python
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import Adam
# 创建一个顺序模型
model = Sequential()
# 添加一个全连接层
model.add(Dense(units=64, activation='relu'))
# 编译模型,指定损失函数和优化器
model.compile(loss='mean_squared_error', optimizer=Adam())
```
### 2.3.3 模型的训练与评估基础
模型训练是机器学习的核心过程,它通过不断迭代输入数据,更新网络参数来最小化损失函数。
在TensorFlow中,训练模型的基本步骤包括准备数据、构建模型、编译模型,以及使用`fit`方法进行训练:
```python
# 假设我们已经有了输入数据X_train和标签y_train
history = model.fit(X_train, y_train, epochs=10, batch_size=32)
```
模型的评估通常在测试集上进行,评估指标可以是准确率、召回率等:
```python
test_loss, test_accuracy = model.evaluate(X_test, y_test)
```
以上是TensorFlow在构建神经网络时的基础概念和操作。在下一部分中,我们将更深入地探讨如何使用TensorFlow进行数据处理和构建复杂的神经网络架构。
# 3. TensorFlow进阶实践
## 3.1 数据处理与管道
在深度学习中,数据是模型的“养料”。有效的数据处理流程能确保模型能够从中学习到有用的模式,提高模型的泛化能力。在本小节中,我们将详细探讨如何在TensorFlow中进行高效的数据处理和构建输入管道(tf.data)。
### 3.1.1 数据集的加载与预处理
加载数据集是深度学习的第一步。在TensorFlow中,可以使用内置的数据集或加载自定义数据。使用内置数据集非常方便,例如使用`tf.keras.datasets.mnist`加载手写数字数据集:
```python
# 加载MNIST数据集
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.mnist.load_data()
```
然而,很多情况下我们可能需要处理自己的数据集。这时,需要将数据集加载到TensorFlow的格式中,进行预处理。预处理包括归一化、转换为张量、批处理等操作:
```python
# 将图像数据归一化到0-1之间
train_images = train_images.astype('float32') / 255.0
test_images = test_images.astype('float32') / 255.0
# 扩展维度,将图像从2D变为3D
train_images = train_images[..., tf.newaxis]
test_images = test_images[..., tf.newaxis]
# 将标签转换为one-hot编码
train_labels = tf.keras.utils.to_categorical(train_labels, 10)
test_labels = tf.keras.utils.to_categorical(test_labels, 10)
```
### 3.1.2 构建输入管道(tf.data)
`tf.data` API是TensorFlow中用于构建高效数据管道的工具。它能够创建可复用的数据管道,实现复杂的数据变换和训练过程中的快速迭代。构建输入管道的步骤通常包括创建数据集、映射预处理函数和批处理:
```python
# 使用tf.data创建输入管道
train_dataset = tf.data.Dataset.from_tensor_slices((train_images, train_labels))
test_dataset = tf.data.Dataset.from_tensor_slices((test_images, test_labels))
# 数据预处理函数
def preprocess(image, label):
image = tf.image.resize(image, [28, 28]) # 调整图像大小
return image, label
# 将预处理函数映射到数据集
train_dataset = train_dataset.map(preprocess)
test_dataset = test_dataset.map(preprocess)
# 批处理和缓存
BATCH_SIZE = 32
train_dataset = train_dataset.shuffle(buffer_size=10000).batch(BATCH_SIZE).cache()
test_dataset = test_dataset.batch(BATCH_SIZE).cache()
```
通过使用`tf.data`,数据加载和预处理过程更加灵活,能够在不同的内存级别上运行,这样在训练时可以有效减少I/O的开销,提高性能。
## 3.2 高级网络架构与训练技巧
随着深度学习技术的发展,越来越多复杂的网络架构被提出以解决特定的问题。本小节将探讨构建这些高级网络架构的方法,并分享一些训练技巧。
### 3.2.1 卷积神经网络(CNN)构建
卷积神经网络在图像处理领域被广泛使用。构建CNN的过程中,要关注卷积层、池化层和全连接层的组合。以构建一个基本的CNN模型为例:
```python
# 使用tf.keras构建CNN模型
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
```
### 3.2.2 循环神经网络(RNN)构建
循环神经网络擅长处理序列数据,例如时间序列数据和自然语言。以下是如何构建一个简单的RNN模型来处理序列数据:
```python
# 使用tf.keras构建RNN模型
model = tf.keras.Sequential([
tf.keras.layers.SimpleRNN(32, input_shape=(None, 128)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
```
### 3.2.3 正则化与超参数调优
在构建模型时,正则化技术如L1、L2正则化和Dropout能够有效避免过拟合。超参数调优方面,可以使用网格搜索、随机搜索或者贝叶斯优化等技术进行。在TensorFlow中,可以使用`tf.keras`的`callbacks`功能在训练过程中动态调整学习率等参数。
## 3.3 模型的保存与部署
训练好的模型需要被保存和部署,以便在实际的生产环境中使用。本小节将讨论如何保存和加载模型,并介绍模型转换和部署的方法。
### 3.3.1 模型的保存与加载
在TensorFlow 2.x中,保存和加载模型非常简便,使用`model.save`和`tf.keras.models.load_model`即可实现:
```python
# 保存模型
model.save('my_model.h5')
# 加载模型
loaded_model = tf.keras.models.load_model('my_model.h5')
```
### 3.3.2 模型转换与服务部署
在部署模型到生产环境之前,通常需要将模型转换为TensorFlow Lite格式,以便在移动设备上运行。TensorFlow提供了转换工具`tf.lite.TFLiteConverter`:
```python
# 将模型转换为TFLite格式
converter = tf.lite.TFLiteConverter.from_keras_model(model)
tflite_model = converter.convert()
# 保存转换后的模型
with open('model.tflite', 'wb') as f:
f.write(tflite_model)
```
部署模型到服务器或云端,可以使用TensorFlow Serving。TensorFlow Serving是一个灵活、高性能的服务系统,用于部署机器学习模型。
```bash
docker pull tensorflow/serving
docker run -p 8501:8501 \
-mount type=bind,\
source=/path/to/my_model/,\
target=/models/my_model \
-e MODEL_NAME=my_model -t tensorflow/serving &
```
通过上述步骤,模型就能够在云端提供预测服务。TensorFlow的高级特性提供了强大的工具,使得模型的保存、转换和部署变得高效而方便。
经过本章的介绍,读者应该已经掌握了TensorFlow进阶实践的关键点,包括高效的数据处理、构建复杂的网络架构、模型的保存与部署。这些技能是构建高效和可扩展的深度学习应用不可或缺的。在接下来的章节中,我们将继续深入探索TensorFlow的高级特性,并通过实战案例来应用这些知识。
# 4. TensorFlow高级特性探索
## 4.1 自定义层与模型
在TensorFlow中,Keras API已经成为了构建模型的首选接口,它提供了一种高级的、用户友好的方式来构建深度学习模型。随着模型复杂性的提高,自定义层和模型就显得尤为重要。自定义层可以扩展现有的模型,赋予其新的功能,而自定义模型则可以提供完全的灵活性来构建全新的架构。
### 4.1.1 使用tf.keras自定义层
在Keras中,通过继承`tf.keras.layers.Layer`类来创建自定义层。以下是自定义一个简单的全连接层作为示例:
```python
import tensorflow as tf
class CustomDenseLayer(tf.keras.layers.Layer):
def __init__(self, units=32, activation=None):
super(CustomDenseLayer, self).__init__()
self.units = units
self.activation = tf.keras.activations.get(activation)
def build(self, input_shape):
# 创建层的权重
self.kernel = self.add_weight("kernel",
shape=[input_shape[-1], self.units],
initializer='random_normal')
self.bias = self.add_weight("bias",
shape=[self.units],
initializer='zeros')
super(CustomDenseLayer, self).build(input_shape)
def call(self, inputs):
# 自定义前向传播
return self.activation(tf.matmul(inputs, self.kernel) + self.bias)
```
在上面的代码中,`CustomDenseLayer`类首先继承了`Layer`类。在`__init__`方法中初始化层的参数,`build`方法用于创建层的权重,而`call`方法则定义了层的前向传播操作。自定义层的使用和普通层相同,可以直接被添加到模型中。
### 4.1.2 构建复杂的神经网络模型
在构建复杂神经网络模型时,通常会包含多个自定义层,以便于实现特定的网络结构。下面的示例展示了如何使用我们刚才定义的`CustomDenseLayer`来构建一个简单的多层感知器(MLP)模型:
```python
class CustomMLPModel(tf.keras.Model):
def __init__(self):
super(CustomMLPModel, self).__init__()
self.dense1 = CustomDenseLayer(64, activation='relu')
self.dense2 = CustomDenseLayer(10, activation='softmax')
def call(self, inputs):
x = self.dense1(inputs)
return self.dense2(x)
model = CustomMLPModel()
model.build((None, 784)) # 假设输入数据是784维的
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
```
## 4.2 TensorFlow中的GPU加速
在深度学习领域,GPU加速已经成为标准做法。TensorFlow通过CUDA与cuDNN库与GPU进行交互,大幅提升计算效率。
### 4.2.1 GPU计算原理与配置
GPU之所以能够大幅提高计算速度,是因为它具有成千上万的小核心,这些核心可以并行执行计算任务。在深度学习中,卷积层、全连接层等操作可以很好地利用GPU的并行性。
为了在TensorFlow中使用GPU,需要确保系统已经安装了CUDA Toolkit和cuDNN,并且在安装TensorFlow时使用的是支持CUDA的版本。在程序运行时,可以通过设置环境变量`CUDA_VISIBLE_DEVICES`来指定使用哪些GPU。
### 4.2.2 TensorFlow中的GPU使用与优化
在TensorFlow 2.x中,默认情况下,如果检测到GPU可用,模型将会自动在GPU上运行。然而,为了更好地控制资源使用,我们有时需要手动设置运行策略。
```python
# 设置TensorFlow只使用第一个GPU
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
try:
# 设置第一个GPU为可见
tf.config.experimental.set_visible_devices(gpus[0], 'GPU')
except RuntimeError as e:
print(e)
# 创建一个模型实例
strategy = tf.distribute.OneDeviceStrategy('/gpu:0')
with strategy.scope():
model = tf.keras.Sequential([
# 添加模型层...
])
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(train_data, train_labels, epochs=5)
```
在上面的代码中,我们使用`tf.distribute.OneDeviceStrategy`来指定模型运行在第一个GPU上。这种方式在多GPU环境中尤其有用,因为它可以帮助管理多个设备上的分布式训练。
## 4.3 调试与性能分析
在深度学习模型的开发过程中,调试和性能分析是不可或缺的环节。正确地使用工具可以快速定位问题并优化模型性能。
### 4.3.1 TensorFlow调试技巧
TensorFlow提供了丰富的调试工具,可以帮助开发者了解模型的内部状态和数据流动。例如,使用`tf.debugging.set_log_device_placement(True)`可以在控制台中看到每个操作被分配到哪个设备上执行。
```python
tf.debugging.set_log_device_placement(True)
a = tf.constant([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
b = tf.constant([[1.0, 2.0], [3.0, 4.0], [5.0, 6.0]])
c = tf.matmul(a, b)
print(c)
```
在上面的代码中,如果系统中有多个GPU,将会看到每个操作被分配到了哪一个GPU上。
### 4.3.2 性能分析与优化策略
性能分析工具如TensorBoard可以帮助我们可视化训练过程中的各种数据。此外,`tf.profiler`是一个强大的性能分析工具,它能够提供详细的执行时间和内存使用情况。
```python
# 使用tf.profiler进行性能分析
tf.profiler.experimental.start('/tmp/profiler')
# 运行模型训练或其他操作
model.fit(train_data, train_labels, epochs=5)
tf.profiler.experimental.stop()
```
性能优化的策略包括但不限于:选择合适的批处理大小、优化数据加载、减少模型复杂度、使用混合精度训练等。实际应用中,需要结合具体情况,对模型进行针对性的优化。
# 5. TensorFlow实战案例分析
## 5.1 图像识别项目实战
### 5.1.1 数据集准备与预处理
在图像识别项目中,数据集的准备与预处理是至关重要的第一步。良好的数据处理可以大幅提升模型的训练效率和识别准确率。以下是数据集准备与预处理的步骤和要点:
1. **数据集的选择**:选择适合的公开数据集,如CIFAR-10、MNIST或ImageNet,这些数据集已被广泛使用,并有大量研究文献支持。
2. **数据集下载与加载**:使用TensorFlow内置的数据集加载方法,例如`tf.keras.datasets`,它提供了多种常见数据集的下载和加载功能。
3. **数据预处理**:数据预处理通常包括数据归一化、图像缩放、增强等操作。归一化是将图像数据缩放到0到1之间,有助于提升模型训练的速度和稳定性。
4. **数据增强**:通过对图像进行旋转、缩放、裁剪、颜色变换等操作来生成更多的训练样本,防止模型过拟合。
以下是实现上述步骤的一个代码示例:
```python
import tensorflow as tf
# 加载数据集
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.cifar10.load_data()
# 数据预处理:归一化
train_images, test_images = train_images / 255.0, test_images / 255.0
# 数据增强
data_augmentation = tf.keras.Sequential([
tf.keras.layers.experimental.preprocessing.RandomFlip('horizontal'),
tf.keras.layers.experimental.preprocessing.RandomRotation(0.1),
])
# 应用数据增强
train_images = data_augmentation(train_images)
```
### 5.1.2 构建CNN模型进行训练与测试
构建卷积神经网络(CNN)是图像识别的核心。以下是一个简单的CNN模型构建流程:
1. **定义模型架构**:通常包括卷积层(Conv2D)、池化层(MaxPooling2D)、全连接层(Dense)等。
2. **添加Dropout层**:有助于防止过拟合。
3. **输出层**:最后一层使用softmax激活函数,进行多分类任务。
4. **编译模型**:选择优化器、损失函数和评价指标。
5. **模型训练**:使用训练数据对模型进行训练。
6. **模型评估**:使用测试数据对训练好的模型进行评估。
以下是构建和训练CNN模型的代码示例:
```python
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
history = model.fit(train_images, train_labels, epochs=10,
validation_data=(test_images, test_labels))
```
在实际的项目实践中,还需要考虑模型的复杂度、训练时间与精度之间的平衡,进行多次的迭代和调优。此外,TensorFlow提供了强大的可视化工具TensorBoard,可以帮助我们更直观地观察训练过程中的各种指标变化。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 中深度学习的基础概念,涵盖广泛的主题。从理解深度学习背后的数学原理到使用 Python 实现神经网络,再到掌握深度学习框架 TensorFlow 和 Keras,专栏提供了全面的指南。此外,它还深入探讨了卷积神经网络 (CNN)、循环神经网络 (RNN) 和长短期记忆 (LSTM) 等特定技术,以及它们在图像处理、序列数据处理和自然语言处理中的应用。专栏还介绍了强化学习、数据预处理、模型调优、优化算法、激活函数、正则化技术、模型压缩和数据增强等高级话题。通过结合理论解释、代码示例和实际项目,本专栏为读者提供了在 Python 中构建和训练高效深度学习模型所需的全面知识。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
PowerBuilder数据窗口高级技巧:揭秘如何提升数据处理效率
参考资源链接:[PowerBuilder6.0/6.5基础教程:入门到精通](https://wenku.csdn.net/doc/6401abbfcce7214c316e959e?spm=1055.2635.3001.10343)
# 1. 数据窗口的基本概念和功能
数据
ANSYS Fluent UDF 优化秘籍:提升模拟效率的终极指南

参考资源链接:[2020 ANSYS Fluent UDF定制手册(R2版)](https://wenku.csdn.net/doc/50fpnuzvks?spm=1055.2635.3001.10343)
# 1. ANSYS Fluent UDF简介
ANSYS
Tasking编译器最佳实践:嵌入式系统开发的秘籍曝光
参考资源链接:[Tasking TriCore编译器用户指南:VX-toolset使用与扩展指令详解](https://wenku.csdn.net/doc/4ft7k5gwmd?spm=1055.2635.3001.10343)
# 1. Tasking编译器概述及其在嵌入式系统中的作用
在现代嵌入式系统开发中,Tasking编译器扮演着至关重要的角色。Tasking编译器是一类针对特定编程语
【深度剖析FatFS】:构建高效嵌入式文件系统的关键步骤

参考资源链接:[FatFS文件系统模块详解及函数用法](https://wenku.csdn.net/doc/79f2wogvkj?spm=1055.2635.3001.10343)
# 1. FatFS概述与基础架构
FatFS是一个完全用ANSI C编写的通用的 FAT 文件系统模块。它设计用于小型嵌入式系统,例如微控制器,拥有灵活的可配置选项和良好的移植性。本章节将介绍Fat
【处理器设计核心】:掌握计算机体系结构量化分析第六版精髓
参考资源链接:[量化分析:计算机体系结构第六版课后习题解答](https://wenku.csdn.net/doc
【iOS音效提取与游戏开发影响案例研究】:提升游戏体验的音效秘诀

参考资源链接:[iPhone原生提示音提取:全面分享下载指南](https://wenku.csdn.net/doc/2dpcybiuco?spm=1055.2635.3001.10343)
# 1
DisplayPort 1.4 vs HDMI 2.1:技术规格大比拼,专家深入剖析
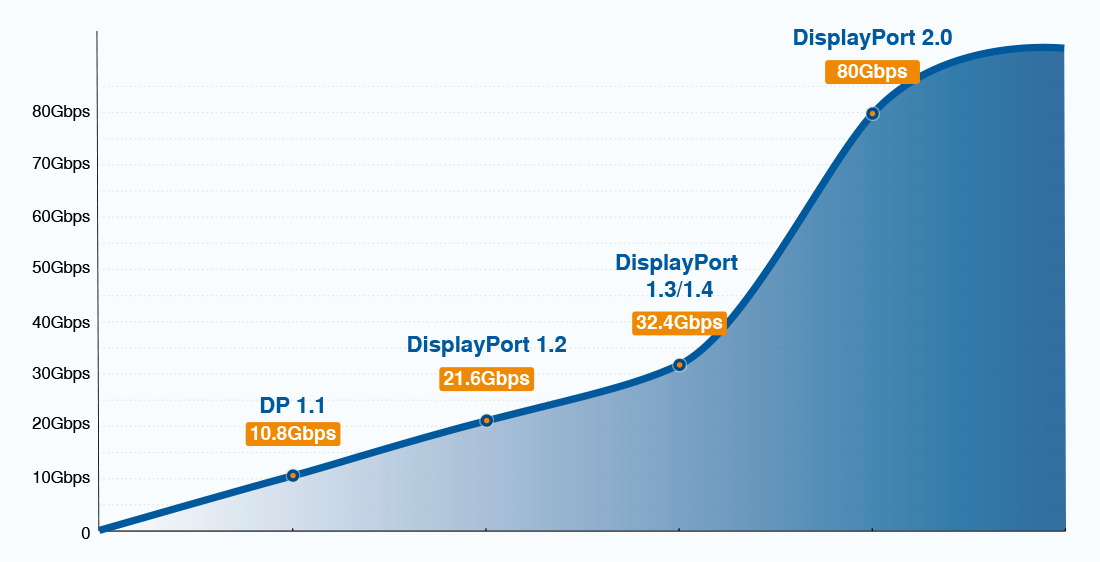
参考资源链接:[display_port_1.4_spec.pdf](https://wenku.csdn.net/doc/6412b76bbe7fbd1778d4a3a1?spm=1055.2635.3001.10343)
# 1. DisplayPort 1.4与HDMI 2.1简介
在数字显示技术的快速演进中,Display
【C语言编程精进】:手把手教你打造高效、易用的计算器
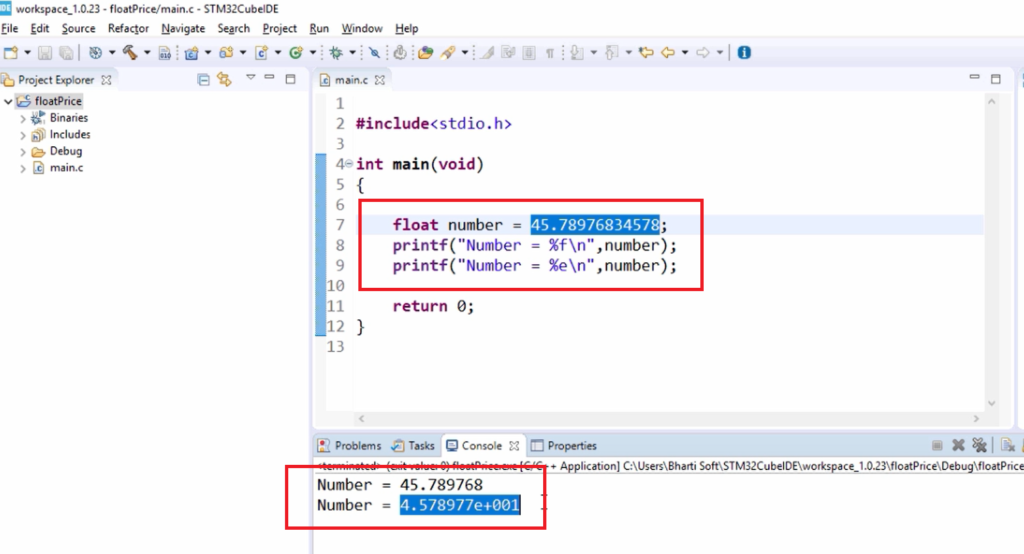
参考资源链接:[编写一个支持基本运算的简单计算器C程序](https://wenku.csdn.net/doc/4d7dvec7kx?spm=1055.2635.3001.10343)
# 1. C语言基础与计算器概念
## 1.1 C语言编程简介
C语言,一种广泛使用的计算机编程语言,具有强大的功能、简洁的语法和高效的执行能力。它诞生于1972年,由Dennis Ritchie开
Ubuntu显卡驱动管理:【手把手教学】关键步骤与高级技巧
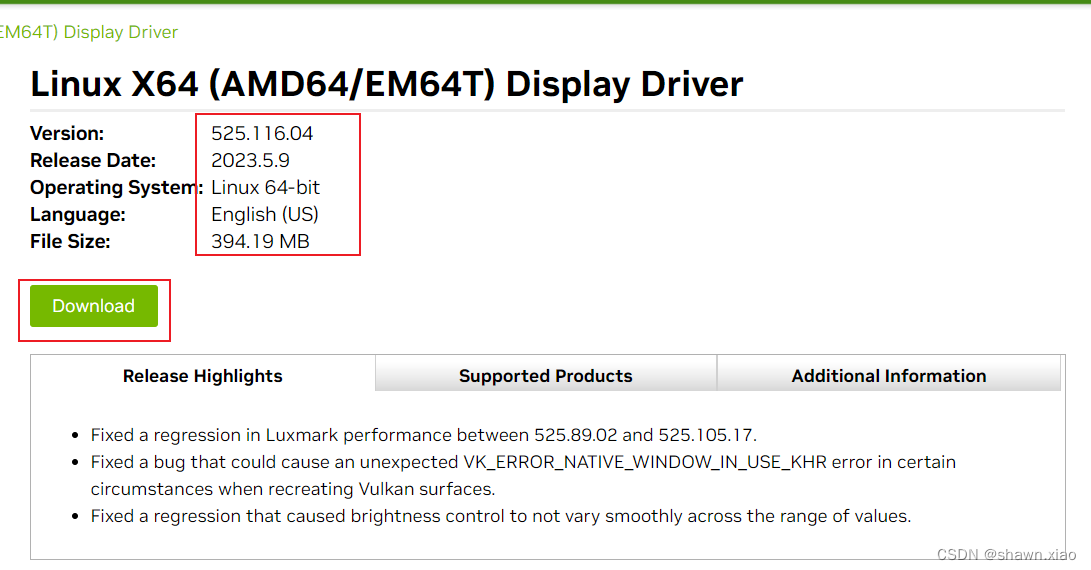
参考资源链接:[Ubuntu vs Debian:AMD显卡驱动在Debian中的安装教程](https://wenku.csdn.net/doc/frnaypmyjc?spm=1055.2635.3001.10343)
# 1. Ubuntu显卡驱动概述
在当今高速发展的信息技术领域中,显卡驱动扮演着不可或缺的角色,尤其在Linux操作系统,如Ubuntu中,驱动的选择和安装对系统性能和稳定性有着直接影响。Ubun
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )