在Spring项目中如何配置和使用Bean
发布时间: 2024-03-10 08:41:47 阅读量: 39 订阅数: 30 
# 1. I. 简介
## A. 什么是Bean
在软件开发中,“Bean”通常指的是Java语言中的一个可重用的软件组件。它是一个由属性和方法组成的Java类,通常用于执行特定的业务逻辑或代表一个特定的数据对象。
## B. Spring中的Bean概念
在Spring框架中,Bean是被Spring IoC容器所管理的对象。它可以是一个Java对象,也可以是由Spring所管理的其他资源,例如数据源、事务管理器等。在Spring中,Bean是通过Spring容器来创建、组装和管理的。
## C. Bean的作用和重要性
Bean的作用在于帮助开发者实现松耦合、模块化和可重用的代码。它能够封装代码和数据,提供简洁的接口,并且能够由Spring容器管理其生命周期和依赖关系。由于Bean的重要性,Spring框架提供了多种方式来配置和管理Bean,以便开发者能够更加灵活地使用和组织Bean。
# 2. II. 配置Bean
在Spring项目中,配置Bean是非常重要的,它决定了应用程序的主要组件和功能。Spring框架提供了多种配置Bean的方式,包括使用XML配置和注解配置两种主要方式。在本节中,我们将介绍如何配置Bean,并讨论XML配置和注解配置各自的优缺点。
A. 使用XML配置Bean
1. Bean的声明和定义
在XML文件中,可以使用`<bean>`标签来声明和定义一个Bean。以下是一个简单的Bean声明和定义示例:
```xml
<bean id="userService" class="com.example.UserService">
<property name="userDao" ref="userDao" />
</bean>
```
这里,我们定义了一个id为"userService"的Bean,它的类是"com.example.UserService",并且注入了名为"userDao"的另一个Bean。
2. Bean的作用域和生命周期
除了简单的声明和定义Bean外,XML配置还可以指定Bean的作用域和生命周期。通过在`<bean>`标签中添加scope和init-method、destroy-method属性,可以分别指定Bean的作用域和初始化、销毁方法。
```xml
<bean id="userService" class="com.example.UserService" scope="singleton"
init-method="init" destroy-method="cleanup">
<property name="userDao" ref="userDao" />
</bean>
```
B. 使用注解配置Bean
1. @Component和相关注解
在Spring中,使用注解配置Bean可以通过多种注解完成,其中最常用的是`@Component`及其衍生注解(如`@Service`、`@Repository`等)。通过在类上添加这些注解,Spring容器将会自动扫描并注册这些Bean。
```java
@Service
public class UserService {
@Autowired
private UserDao userDao;
// other properties and methods
}
```
2. 自动扫描和装配Bean
除了单独使用`@Component`等注解外,还可以通过在配置类上添加`@ComponentScan`注解,来指定要扫描的包路径,Spring容器将自动扫描并装配符合条件的Bean。
```java
@SpringBootApplication
@ComponentScan("com.example")
public class AppConfig {
// configuration details
}
```
通过以上方式,可以灵活地配置Bean,并根据实际情况选择适合的配置方式。接下来,我们将讨论如何使用配置好的Bean,并比较XML配置和注解配置的异同。
(代码解释及其他配置细节请参考下文……)
# 3. III. 使用Bean
在Spring项目中,我们经常需要注入不同的Bean来实现业务逻辑或功能。以下是在Spring项目中如何使用Bean的一些方法:
#### A. 在Spring项目中如何注入Bean
1. **构造器注入:**
构造器注入是一种通过Bean的构造函数传递参数的方式。通过在XML配置文件或使用注解的方式,我们可以将依赖的Bean通过构造器直接注入到目标Bean中。示例代码如下:
```java
// Java代码示例
public class UserService {
private UserDao userDao;
public UserService(UserDao userDao) {
this.userDao = userDao;
}
}
```
2. **属性注入:**
属性注入是通过设置Bean的属性来传递依赖的方式。我们可以在XML配置文件或使用注解方式来注入Bean的属性。示例代码如下:
```java
// Java代码示例
public class UserService {
private UserDao userDao;
public void setUserDao(UserDao userDao) {
this.userDao = userDao;
}
}
```
3. **注解驱动的注入方式:**
使用注解可以简化Bean的注入方式,通过在Bean类上使用`@Autowired`等注解,Spring容器会自动帮助我们识别并注入相应的依赖Bean。示例代码如下:
```java
// Java代码示例
@Component
public class UserService {
@Autowired
private UserDao userDao;
}
```
#### B. Bean依赖注入
1. **构造器注入的依赖:**
使用构造器注入可以确保依赖的Bean在实例化目标Bean时就已经注入,避免了可能出现的空指针异常等问题。
2. **属性注入的依赖:**
属性注入的依赖方式比较灵活,我们可以在需要的时候对属性进行设置,但需注意可能出现的循环依赖问题。
3. **使用@Autowired等注解注入依赖:**
注解驱动的依赖注入方式简化了配置的过程,但需要确保被注入的Bean已经在Spring容器中注册,否则会导致注入失败。
通过以上方式,我们可以灵活地使用Bean并管理Bean之间的依赖关系,从而实现复杂的业务逻辑和功能。
# 4. IV. Bean的作用域和生命周期管理
在Spring中,Bean的作用域和生命周期管理是非常重要的概念。了解Bean的作用域和生命周期管理,可以帮助我们更好地控制Bean的创建、销毁和使用方式,从而更好地实现我们的业务逻辑。
### A. 单例和原型模式
在Spring中,我们可以通过作用域来控制Bean的创建方式。最常见的作用域包括单例(Singleton)和原型(Prototype)两种。
- **单例模式:** 在这种模式下,Spring容器中只会创建一个Bean实例,所有对该Bean的请求都会返回同一个实例。我们可以通过配置来指定Bean的作用域为单例模式。
- **原型模式:** 在这种模式下,每次请求Bean时,Spring容器都会创建一个新的Bean实例。我们同样可以通过配置来指定Bean的作用域为原型模式。
### B. Bean的初始化和销毁方法
在Spring中,我们可以通过配置来指定Bean的初始化和销毁方法,以便在Bean被创建和销毁时执行相应的逻辑。
```java
public class MyBean {
// 初始化方法
public void init() {
// 执行初始化逻辑
}
// 销毁方法
public void destroy() {
// 执行销毁逻辑
}
}
```
通过在XML配置文件或使用注解的方式指定初始化和销毁方法,可以让Spring容器在Bean被创建和销毁时调用相应的方法,完成特定的逻辑。
### C. BeanPostProcessor接口的应用
BeanPostProcessor是Spring框架中的一个接口,它允许我们在Bean初始化前后对Bean进行一些处理操作。
```java
public class MyPostProcessor implements BeanPostProcessor {
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
// 在Bean初始化之前的处理逻辑
return bean;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
// 在Bean初始化之后的处理逻辑
return bean;
}
}
```
通过实现BeanPostProcessor接口,并注册为Spring容器的一个Bean,我们可以在Bean初始化前后对Bean进行一些自定义的处理操作,例如动态代理、AOP等。
以上就是Bean的作用域和生命周期管理相关的内容,通过合理地配置Bean的作用域和生命周期管理方式,可以更好地控制Bean的创建和销毁过程,以及实现一些定制化的逻辑处理。
# 5. V. Bean的AOP(面向切面编程)应用
在现代的软件开发中,AOP(Aspect-Oriented Programming,面向切面编程)已经成为一种非常重要且强大的编程范式。它的核心思想是将程序中的业务逻辑与横切逻辑(如日志、事务、安全等)分离开来,以增强代码的模块化和可维护性。Spring框架对AOP的支持非常好,下面我们来看一下在Spring项目中如何配置和使用AOP。
### A. AOP的基本概念和作用
1. **切面(Aspect)**:切面是横切逻辑的模块化单元,它包含了切点和通知。
2. **切点(Pointcut)**:切点是在程序执行过程中某个特定的点,通常是一个方法的执行。在AOP中,我们可以通过表达式选择哪些方法会被应用通知。
3. **通知(Advice)**:通知定义了切点上需要执行的动作,包括前置通知、后置通知、环绕通知、异常通知和最终通知等。
### B. 在Spring项目中如何配置和使用AOP
1. **声明切面和切点**
通过XML配置或注解方式声明切面和切点,指定需要切入的业务方法。
```java
// 使用@Aspect注解声明切面类
@Aspect
public class LoggingAspect {
// 定义切点表达式
@Pointcut("execution(* com.example.service.*.*(..))")
private void selectAll() {}
// 声明前置通知
@Before("selectAll()")
public void beforeAdvice(JoinPoint joinPoint) {
System.out.println("前置通知:执行 " + joinPoint.getSignature().getName() + " 方法");
}
}
```
2. **定义通知类型**
在切面类中定义各种类型的通知,如@Before、@After、@Around、@AfterReturning、@AfterThrowing等。
```java
// 声明环绕通知
@Around("selectAll()")
public Object aroundAdvice(ProceedingJoinPoint joinPoint) throws Throwable {
System.out.println("环绕通知:开始执行 " + joinPoint.getSignature().getName() + " 方法");
Object result = joinPoint.proceed();
System.out.println("环绕通知:结束执行 " + joinPoint.getSignature().getName() + " 方法");
return result;
}
```
以上就是在Spring项目中配置和使用AOP的基本步骤,通过AOP可以实现日志记录、事务管理、权限控制等功能,提高代码的复用性和可维护性。
# 6. VI. 实例演示
在这一章节中,我们将为您展示在Spring项目中实际配置和使用Bean的示例。我们将演示Bean的注入和依赖关系,并对比XML配置和注解配置的不同。
#### A. 在Spring项目中实际配置和使用Bean的示例
下面是一个简单的示例,演示如何在Spring项目中配置和使用Bean。我们将创建一个名为Car的Bean,其中包含属性和方法,然后在另一个类中进行Bean的注入和使用。
1. 首先,我们创建一个Car类作为Bean:
```java
public class Car {
private String brand;
public void setBrand(String brand) {
this.brand = brand;
}
public void start() {
System.out.println("The " + brand + " car is starting.");
}
}
```
2. 接下来,在XML配置文件(applicationContext.xml)中声明和定义Car Bean:
```xml
<bean id="car" class="com.example.Car">
<property name="brand" value="Toyota"/>
</bean>
```
3. 然后,在另一个类中进行Bean的注入和使用:
```java
public class CarOwner {
private Car car;
public void setCar(Car car) {
this.car = car;
}
public void driveCar() {
car.start();
}
}
```
4. 最后,在主程序中进行测试:
```java
public class Main {
public static void main(String[] args) {
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");
CarOwner owner = (CarOwner) context.getBean("carOwner");
owner.driveCar();
context.close();
}
}
```
#### B. 展示Bean的注入和依赖关系
在上述示例中,我们演示了如何注入Car Bean到CarOwner类中,实现了依赖关系的管理。通过setCar方法实现了属性注入,使CarOwner类依赖于Car类。
#### C. 对比XML配置和注解配置的不同
在实际项目中,可以选择使用XML配置或注解配置来定义Bean。XML配置灵活,适合复杂的配置需求;而注解配置简洁,便于维护和阅读。根据实际情况和项目需求选择合适的配置方式是非常重要的。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
贝叶斯优化软件实战:最佳工具与框架对比分析
# 1. 贝叶斯优化的基础理论
贝叶斯优化是一种概率模型,用于寻找给定黑盒函数的全局最优解。它特别适用于需要进行昂贵计算的场景,例如机器学习模型的超参数调优。贝叶斯优化的核心在于构建一个代理模型(通常是高斯过程),用以估计目标函数的行为,并基于此代理模型智能地选择下一点进行评估。
## 2.1 贝叶斯优化的基本概念
### 2.1.1 优化问题的数学模型
贝叶斯优化的基础模型通常包括目标函数 \(f(x)\),目标函数的参数空间 \(X\) 以及一个采集函数(Acquisition Function),用于决定下一步的探索点。目标函数 \(f(x)\) 通常是在计算上非常昂贵的,因此需
大规模深度学习系统:Dropout的实施与优化策略
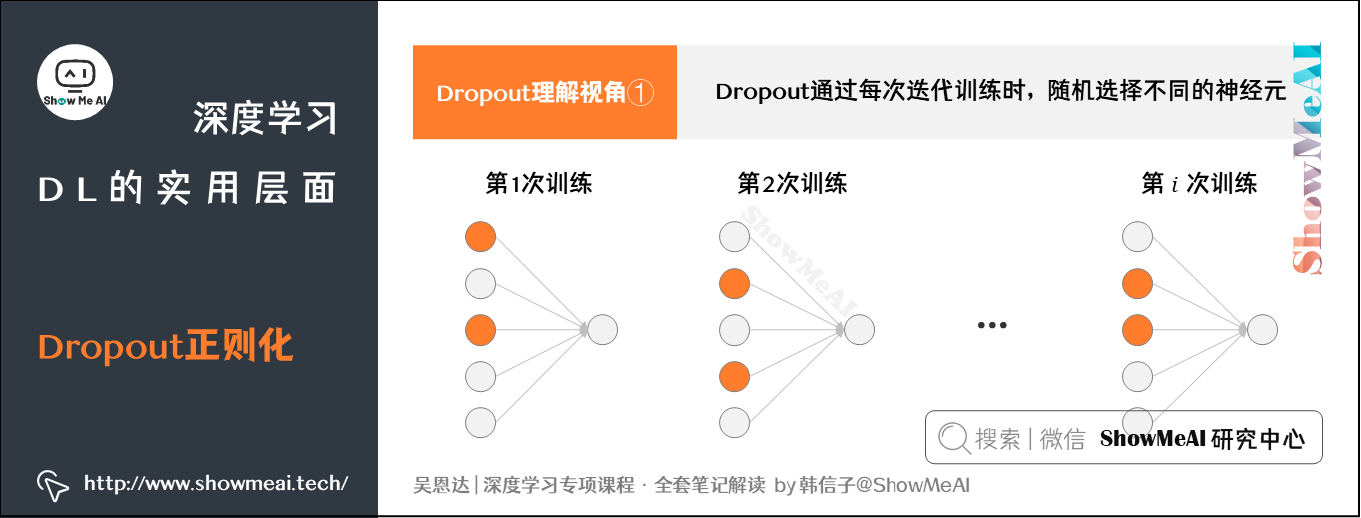
# 1. 深度学习与Dropout概述
在当前的深度学习领域中,Dropout技术以其简单而强大的能力防止神经网络的过拟合而著称。本章旨在为读者提供Dropout技术的初步了解,并概述其在深度学习中的重要性。我们将从两个方面进行探讨:
首先,将介绍深度学习的基本概念,明确其在人工智能中的地位。深度学习是模仿人脑处理信息的机制,通过构建多层的人工神经网络来学习数据的高层次特征,它已
注意力机制与过拟合:深度学习中的关键关系探讨

# 1. 深度学习的注意力机制概述
## 概念引入
注意力机制是深度学习领域的一种创新技术,其灵感来源于人类视觉注意力的生物学机制。在深度学习模型中,注意力机制能够使模型在处理数据时,更加关注于输入数据中具有关键信息的部分,从而提高学习效率和任务性能。
## 重要性解析
数据分布不匹配问题及解决方案:机器学习视角下的速成课

# 1. 数据分布不匹配问题概述
在人工智能和机器学习领域,数据是构建模型的基础。然而,数据本身可能存在分布不一致的问题,这会严重影响模型的性能和泛化能力。数据分布不匹配指的是在不同的数据集中,数据的分布特性存在显著差异,例如,训练数据集和测试数据集可能因为采集环境、时间、样本选择等多种因素而具有不同的统计特性。这种差异会导致训练出的模型无法准确预测新样本,即
深度学习的正则化探索:L2正则化应用与效果评估

# 1. 深度学习中的正则化概念
## 1.1 正则化的基本概念
在深度学习中,正则化是一种广泛使用的技术,旨在防止模型过拟合并提高其泛化能力
图像处理中的正则化应用:过拟合预防与泛化能力提升策略

# 1. 图像处理与正则化概念解析
在现代图像处理技术中,正则化作为一种核心的数学工具,对图像的解析、去噪、增强以及分割等操作起着至关重要
L1正则化模型诊断指南:如何检查模型假设与识别异常值(诊断流程+案例研究)

# 1. L1正则化模型概述
L1正则化,也被称为Lasso回归,是一种用于模型特征选择和复杂度控制的方法。它通过在损失函数中加入与模型权重相关的L1惩罚项来实现。L1正则化的作用机制是引导某些模型参数缩小至零,使得模型在学习过程中具有自动特征选择的功能,因此能够产生更加稀疏的模型。本章将从L1正则化的基础概念出发,逐步深入到其在机器学习中的应用和优势
随机搜索在强化学习算法中的应用

# 1. 强化学习算法基础
强化学习是一种机器学习方法,侧重于如何基于环境做出决策以最大化某种累积奖励。本章节将为读者提供强化学习算法的基础知识,为后续章节中随机搜索与强化学习结合的深入探讨打下理论基础。
## 1.1 强化学习的概念和框架
强化学习涉及智能体(Agent)与环境(Environment)之间的交互。智能体通过执行动作(Action)影响环境,并根据环境的反馈获得奖
机器学习调试实战:分析并优化模型性能的偏差与方差
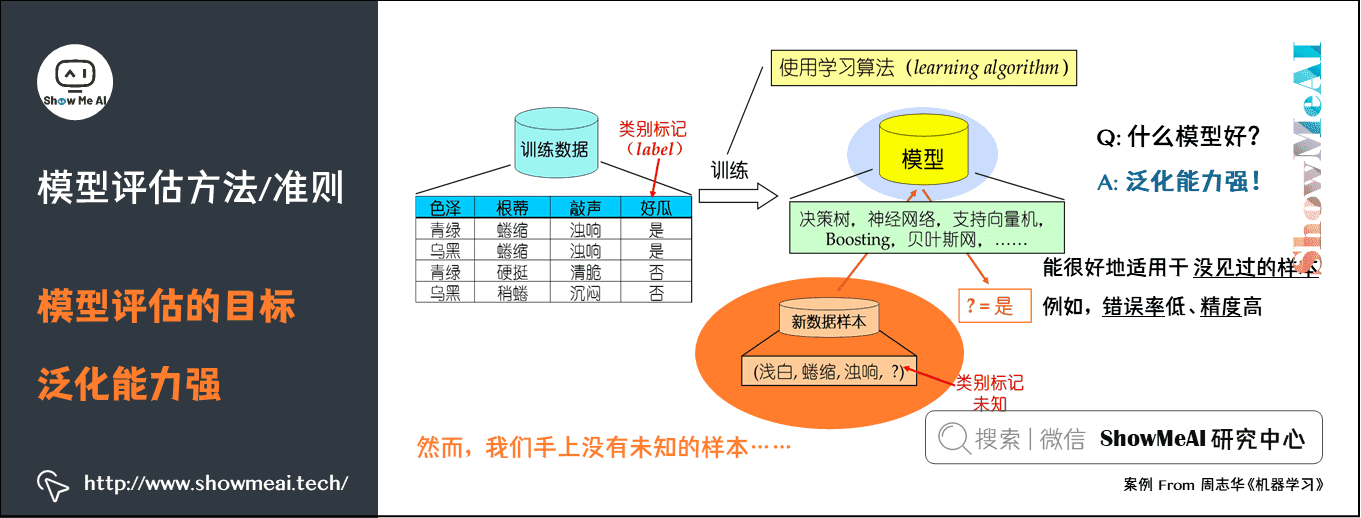
# 1. 机器学习调试的概念和重要性
## 什么是机器学习调试
机器学习调试是指在开发机器学习模型的过程中,通过识别和解决模型性能不佳的问题来改善模型预测准确性的过程。它是模型训练不可或缺的环节,涵盖了从数据预处理到最终模型部署的每一个步骤。
## 调试的重要性
有效的调试能够显著提高模型的泛化能力,即在未见过的数据上也能作出准确预测的能力。没有经过适当调试的模型可能无法应对实
网格搜索:多目标优化的实战技巧

# 1. 网格搜索技术概述
## 1.1 网格搜索的基本概念
网格搜索(Grid Search)是一种系统化、高效地遍历多维空间参数的优化方法。它通过在每个参数维度上定义一系列候选值,并
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )