在Spring中如何使用属性注入进行配置
发布时间: 2024-03-10 08:46:31 阅读量: 31 订阅数: 30 
# 1. Spring框架简介
## 1.1 Spring框架概述
Spring框架是一个轻量级的开源框架,用于构建企业级应用程序。它提供了全面的基础设施支持,包括依赖注入(DI)、面向切面编程(AOP)、事件驱动、资源管理等。Spring框架的核心是IoC容器,它可以管理对象的生命周期和配置,在对象之间提供松耦合的方式进行协作。
## 1.2 依赖注入和属性注入的概念
依赖注入(DI)是指通过外部配置来管理类之间的依赖关系,例如一个类依赖于另一个类的实例,而不是通过在类内部直接创建依赖对象。属性注入是依赖注入的一种形式,它通过设置对象的属性来注入依赖。
## 1.3 Spring框架中的配置方式简介
在Spring框架中,可以使用XML文件、Java注解和Java配置类等方式来进行配置。其中XML文件配置是传统的方式,Java注解和Java配置类则是相对较新的方式。这些配置方式可以用来进行依赖注入和属性注入的配置,从而实现灵活的组件化和解耦。
接下来,我们将分别介绍属性注入的基本用法、基于XML配置文件的属性注入、基于Java注解的属性注入、基于Java配置类的属性注入,以及属性注入的最佳实践与注意事项。
# 2. 属性注入的基本用法
在Spring框架中,属性注入是一种常见的依赖注入方式,用于向bean中注入所需的属性值。属性注入可以通过多种方式进行配置,包括使用XML配置文件、Java注解以及Java配置类。接下来,我们将介绍属性注入的基本用法,以及不同配置方式的实现方式。
#### 2.1 使用XML配置文件进行属性注入
在XML配置文件中,我们可以使用`<property>`标签来进行属性注入。下面是一个简单的示例,演示了如何通过XML配置文件注入属性值:
```xml
<!-- 配置文件 applicationContext.xml -->
<bean id="userService" class="com.example.UserService">
<property name="userDao" ref="userDao"/>
</bean>
<bean id="userDao" class="com.example.UserDao">
<property name="dataSource" ref="dataSource"/>
</bean>
<bean id="dataSource" class="com.example.DataSource">
<property name="url" value="jdbc:mysql://localhost:3306/mydb"/>
<property name="username" value="root"/>
<property name="password" value="password"/>
</bean>
```
在上面的示例中,`<property>`标签用于将`userDao`和`dataSource`注入到`UserService`和`UserDao`中。
#### 2.2 使用Java注解进行属性注入
除了XML配置文件外,我们也可以使用Java注解来进行属性注入。常用的注解包括`@Autowired`和`@Value`,它们可以直接用于字段、构造器或方法上。下面是一个简单的示例,演示了如何使用`@Autowired`注解进行属性注入:
```java
@Component
public class UserService {
@Autowired
private UserDao userDao;
// 省略其他代码
}
```
在上面的示例中,`@Autowired`注解用于标记`userDao`字段,Spring容器会自动将匹配的bean注入到该字段中。
#### 2.3 使用Java配置类进行属性注入
另一种常见的属性注入方式是使用Java配置类,通过`@Bean`注解和`@PropertySource`注解来实现属性注入。下面是一个简单的示例,演示了如何使用Java配置类进行属性注入:
```java
@Configuration
@PropertySource("classpath:application.properties")
public class AppConfig {
@Value("${jdbc.url}")
private String jdbcUrl;
@Bean
public DataSource dataSource() {
BasicDataSource dataSource = new BasicDataSource();
dataSource.setUrl(jdbcUrl);
// 省略其他代码
return dataSource;
}
}
```
在上面的示例中,`@PropertySource`注解用于指定属性文件的位置,`@Value`注解用于注入属性值。
通过以上示例,我们介绍了属性注入的基本用法,包括使用XML配置文件、Java注解以及Java配置类进行属性注入。接下来,我们将深入讨论不同方式下的具体实现细节和最佳实践。
# 3. 基于XML配置文件的属性注入
在Spring框架中,我们可以通过XML配置文件来实现属性注入,这种方式非常常见也非常灵活,可以实现构造器注入、Setter方法注入,甚至可以使用p命名空间进行简化配置。接下来,让我们详细介绍基于XML配置文件的属性注入方式。
#### 3.1 构造器注入
构造器注入是通过构造函数来注入依赖项的方式。在XML配置文件中,我们可以使用<constructor-arg>元素来指定构造器参数。下面是一个简单的示例:
```xml
<!-- 定义一个名为ExampleBean的Bean,并使用构造器注入 -->
<bean id="exampleBean" class="com.example.ExampleBean">
<constructor-arg index="0" value="张三"/>
<constructor-arg index="1" ref="anotherBean"/>
</bean>
```
这里,我们通过<constructor-arg>元素为ExampleBean指定了两个参数,一个是值类型的参数,一个是引用类型的参数。
#### 3.2 Setter方法注入
Setter方法注入是通过调用对象的Setter方法来注入依赖项的方式。在XML配置文件中,我们可以使用<property>元素来指定属性的值。示例如下:
```xml
<!-- 定义一个名为AnotherBean的Bean,并使用Setter方法注入 -->
<bean id="anotherBean" class="com.example.AnotherBean">
<property name="name" value="李四"/>
<property name="age" value="25"/>
</bean>
```
在这个示例中,我们为AnotherBean指定了name和age属性的值,Spring会自动调用对应的Setter方法将值注入到Bean中。
#### 3.3 使用p命名空间进行简化配置
除了上述传统的构造器注入和Setter方法注入外,Spring还提供了p命名空间来进行简化配置,可以更加简洁地进行属性注入。示例如下:
```xml
<!-- 使用p命名空间进行简化配置 -->
<bean id="exampleBean" class="com.example.ExampleBean" p:name="王五" p:age="30"/>
```
通过p命名空间,我们可以直接在<bean>元素中使用p:name和p:age来指定对应的属性值,避免了繁琐的<property>元素配置过程。
通过以上介绍,你可以根据实际情况选择适合的属性注入方式,更好地进行依赖注入和配置管理。接下来,让我们深入学习基于Java注解的属性注入方式。
# 4. 基于Java注解的属性注入
在Spring框架中,除了XML配置文件外,我们还可以使用Java注解来进行属性注入。Java注解提供了一种更加简洁、便捷的方式来配置属性注入,能够让我们的代码更加优雅和易于理解。
#### 4.1 @Autowired注解的使用
`@Autowired`注解是Spring框架提供的一种依赖注入方式,用于自动装配Bean,通过类型进行匹配注入。在属性、构造器、Setter方法以及方法上使用`@Autowired`注解,Spring容器就会自动对其对应的Bean进行注入。
下面我们通过一个简单的示例来演示@Autowired注解的使用:
```java
// 定义一个UserService接口
public interface UserService {
void addUser();
}
// 定义一个UserServiceImpl实现类
@Service("userService")
public class UserServiceImpl implements UserService {
public void addUser() {
System.out.println("添加用户成功");
}
}
// 在另一个类中使用@Autowired注解进行属性注入
@Component
public class UserController {
@Autowired
private UserService userService;
public void addUser() {
userService.addUser();
}
}
```
在上面的示例中,我们使用`@Autowired`注解将`UserService`注入到`UserController`中,这样就可以在`UserController`中直接使用`userService`而无需手动实例化。这样的方式极大地简化了代码,提高了代码的可维护性。
#### 4.2 @Value注解的使用
`@Value`注解允许我们将值直接注入到属性中,非常适合注入简单类型的属性,如基本数据类型、String类型等。我们可以将配置文件中的值直接注入到Bean中,避免了硬编码的方式,提高了灵活性。
下面是一个简单的示例,演示了`@Value`注解的使用:
```java
// 定义一个DataSource类
@Component
public class DataSource {
@Value("${db.url}")
private String url;
@Value("${db.username}")
private String username;
@Value("${db.password}")
private String password;
// 省略getter和setter方法
}
// 配置文件application.properties
db.url=jdbc:mysql://localhost:3306/mydb
db.username=admin
db.password=123456
```
在上面的示例中,我们使用`@Value`注解将配置文件中的值注入到`DataSource`类的属性中,这样就可以在使用`DataSource`时直接引用这些值,而无需硬编码在代码中。
#### 4.3 @Resource注解的使用
`@Resource`注解是另一种用于注入Bean的注解,在Spring框架中通常用于按名称进行注入。它可以标注在字段或者setter方法上,提供了一个name属性,用于指定要注入的Bean的名称。
下面是一个简单的示例,演示了`@Resource`注解的使用:
```java
// 定义一个TaskService接口
public interface TaskService {
void executeTask();
}
// 定义一个TaskServiceImpl实现类
@Component
public class TaskServiceImpl implements TaskService {
public void executeTask() {
System.out.println("执行定时任务成功");
}
}
// 使用@Resource注解进行属性注入
@Component
public class TaskController {
@Resource(name = "taskServiceImpl")
private TaskService taskService;
public void executeTask() {
taskService.executeTask();
}
}
```
在上面的示例中,我们使用`@Resource`注解按照名称将`TaskServiceImpl`注入到`TaskController`中,这样就可以在`TaskController`中直接引用`taskService`而无需手动实例化。
通过以上示例,我们可以看到使用Java注解进行属性注入能够使代码更加简洁、清晰,同时也提高了代码的可读性和可维护性。这种方式在实际项目开发中得到了广泛的应用和推崇。
# 5. 基于Java配置类的属性注入
在Spring框架中,我们可以使用Java配置类来进行属性注入。通过配置类的方式,可以更加灵活地管理Bean的创建与属性注入。下面我们将介绍Java配置类属性注入的基本用法。
#### 5.1 配置类的创建与使用
首先,我们需要创建一个Java配置类,并在该类中使用@Bean注解来定义Bean,并使用@PropertySource注解来指定属性文件。
```java
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.PropertySource;
@Configuration
@PropertySource("classpath:config.properties")
public class AppConfig {
@Bean
public MyBean myBean() {
return new MyBean();
}
}
```
#### 5.2 @Bean注解的使用
在上面的配置类中,我们使用@Bean注解来定义了一个名为"myBean"的Bean,该Bean的类型为MyBean。通过@Bean注解,Spring容器可以管理该Bean的创建和属性注入。
```java
public class MyBean {
private String name;
// 省略构造方法和其他属性
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
```
#### 5.3 @PropertySource注解的使用
在配置类中使用@PropertySource注解可以指定属性文件的位置,从而实现属性的注入。
```java
// config.properties文件内容
myBean.name=John Doe
```
在属性文件"config.properties"中定义了属性"myBean.name",我们可以通过@PropertySource注解将其注入到MyBean的name属性中。
```java
@Autowired
private MyBean myBean;
public void printName() {
System.out.println(myBean.getName());
}
```
通过@Autowired注解将MyBean注入到其他Bean中,然后调用printName方法可输出"John Doe"。
通过Java配置类进行属性注入,可以更加灵活地管理Bean的创建与属性注入,提高了代码的可维护性和可读性。
# 6. 属性注入的最佳实践与注意事项
在使用属性注入进行配置时,有一些最佳实践和注意事项需要我们遵循和注意。下面我们将介绍一些在实践中应该注意的方面。
#### 6.1 最佳实践:构造器注入 vs Setter方法注入
在使用属性注入时,我们通常会遇到使用构造器注入和Setter方法注入两种方式。那么在选择时应该如何取舍呢?
- **构造器注入**:
- 适用于那些必须的属性,即对象创建时就必须提供的属性。
- 帮助确保对象在实例化后就是完全初始化的。
- 使对象实例在不可变性方面更好,提供了更好的线程安全性。
- **Setter方法注入**:
- 适用于那些可选的属性,即某些属性对于对象的功能并不是必须的。
- 提供了更好的灵活性,可以根据需要随时更改属性的值。
通常情况下,应该遵循以下几个原则:
- 对于必需的属性,优先考虑使用构造器注入。
- 对于可选的属性,使用Setter方法注入更为合适。
#### 6.2 属性注入的注意事项与常见问题解决
在使用属性注入时,可能会遇到一些常见的问题和需要注意的地方,下面列举一些解决方案:
- 确保属性的数据类型与配置文件中的数据类型一致,避免类型转换错误。
- 使用@Value注解时,需要注意占位符的使用和格式,确保配置文件中的值正确注入。
- 当出现注入失败或者找不到bean的情况时,检查配置文件路径、包扫描路径是否设置正确。
- 注意循环依赖的问题,尽量避免对象之间相互依赖引起的死锁问题。
通过遵循最佳实践和注意事项,可以更好地使用属性注入进行配置,确保代码的可维护性和性能优化。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
贝叶斯优化软件实战:最佳工具与框架对比分析
# 1. 贝叶斯优化的基础理论
贝叶斯优化是一种概率模型,用于寻找给定黑盒函数的全局最优解。它特别适用于需要进行昂贵计算的场景,例如机器学习模型的超参数调优。贝叶斯优化的核心在于构建一个代理模型(通常是高斯过程),用以估计目标函数的行为,并基于此代理模型智能地选择下一点进行评估。
## 2.1 贝叶斯优化的基本概念
### 2.1.1 优化问题的数学模型
贝叶斯优化的基础模型通常包括目标函数 \(f(x)\),目标函数的参数空间 \(X\) 以及一个采集函数(Acquisition Function),用于决定下一步的探索点。目标函数 \(f(x)\) 通常是在计算上非常昂贵的,因此需
大规模深度学习系统:Dropout的实施与优化策略
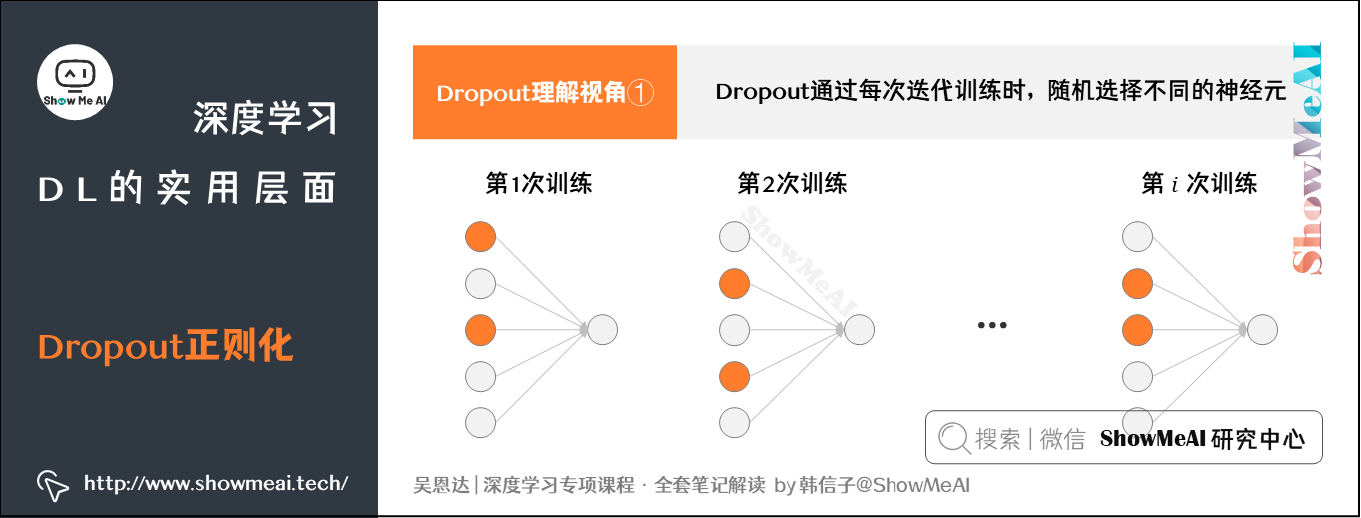
# 1. 深度学习与Dropout概述
在当前的深度学习领域中,Dropout技术以其简单而强大的能力防止神经网络的过拟合而著称。本章旨在为读者提供Dropout技术的初步了解,并概述其在深度学习中的重要性。我们将从两个方面进行探讨:
首先,将介绍深度学习的基本概念,明确其在人工智能中的地位。深度学习是模仿人脑处理信息的机制,通过构建多层的人工神经网络来学习数据的高层次特征,它已
注意力机制与过拟合:深度学习中的关键关系探讨

# 1. 深度学习的注意力机制概述
## 概念引入
注意力机制是深度学习领域的一种创新技术,其灵感来源于人类视觉注意力的生物学机制。在深度学习模型中,注意力机制能够使模型在处理数据时,更加关注于输入数据中具有关键信息的部分,从而提高学习效率和任务性能。
## 重要性解析
数据分布不匹配问题及解决方案:机器学习视角下的速成课

# 1. 数据分布不匹配问题概述
在人工智能和机器学习领域,数据是构建模型的基础。然而,数据本身可能存在分布不一致的问题,这会严重影响模型的性能和泛化能力。数据分布不匹配指的是在不同的数据集中,数据的分布特性存在显著差异,例如,训练数据集和测试数据集可能因为采集环境、时间、样本选择等多种因素而具有不同的统计特性。这种差异会导致训练出的模型无法准确预测新样本,即
深度学习的正则化探索:L2正则化应用与效果评估

# 1. 深度学习中的正则化概念
## 1.1 正则化的基本概念
在深度学习中,正则化是一种广泛使用的技术,旨在防止模型过拟合并提高其泛化能力
图像处理中的正则化应用:过拟合预防与泛化能力提升策略

# 1. 图像处理与正则化概念解析
在现代图像处理技术中,正则化作为一种核心的数学工具,对图像的解析、去噪、增强以及分割等操作起着至关重要
L1正则化模型诊断指南:如何检查模型假设与识别异常值(诊断流程+案例研究)

# 1. L1正则化模型概述
L1正则化,也被称为Lasso回归,是一种用于模型特征选择和复杂度控制的方法。它通过在损失函数中加入与模型权重相关的L1惩罚项来实现。L1正则化的作用机制是引导某些模型参数缩小至零,使得模型在学习过程中具有自动特征选择的功能,因此能够产生更加稀疏的模型。本章将从L1正则化的基础概念出发,逐步深入到其在机器学习中的应用和优势
随机搜索在强化学习算法中的应用

# 1. 强化学习算法基础
强化学习是一种机器学习方法,侧重于如何基于环境做出决策以最大化某种累积奖励。本章节将为读者提供强化学习算法的基础知识,为后续章节中随机搜索与强化学习结合的深入探讨打下理论基础。
## 1.1 强化学习的概念和框架
强化学习涉及智能体(Agent)与环境(Environment)之间的交互。智能体通过执行动作(Action)影响环境,并根据环境的反馈获得奖
机器学习调试实战:分析并优化模型性能的偏差与方差
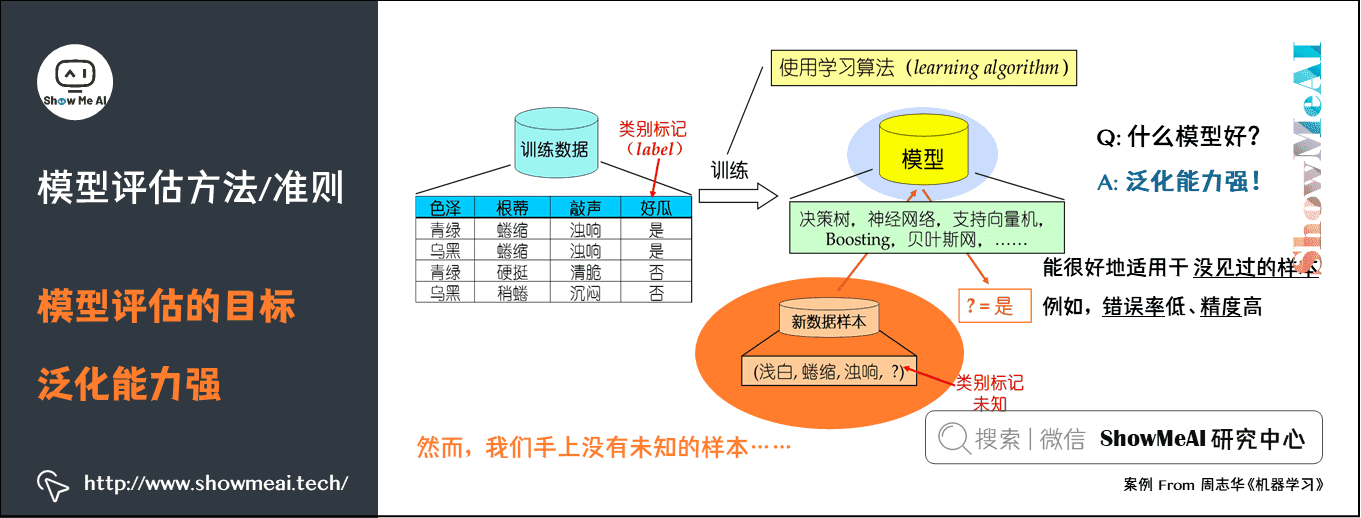
# 1. 机器学习调试的概念和重要性
## 什么是机器学习调试
机器学习调试是指在开发机器学习模型的过程中,通过识别和解决模型性能不佳的问题来改善模型预测准确性的过程。它是模型训练不可或缺的环节,涵盖了从数据预处理到最终模型部署的每一个步骤。
## 调试的重要性
有效的调试能够显著提高模型的泛化能力,即在未见过的数据上也能作出准确预测的能力。没有经过适当调试的模型可能无法应对实
网格搜索:多目标优化的实战技巧

# 1. 网格搜索技术概述
## 1.1 网格搜索的基本概念
网格搜索(Grid Search)是一种系统化、高效地遍历多维空间参数的优化方法。它通过在每个参数维度上定义一系列候选值,并
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )