




【HDFS数据块管理揭秘】:掌握保障数据可靠性与一致性的关键


大数据开发:HDFS数据节点与名称节点的通信机制.docx
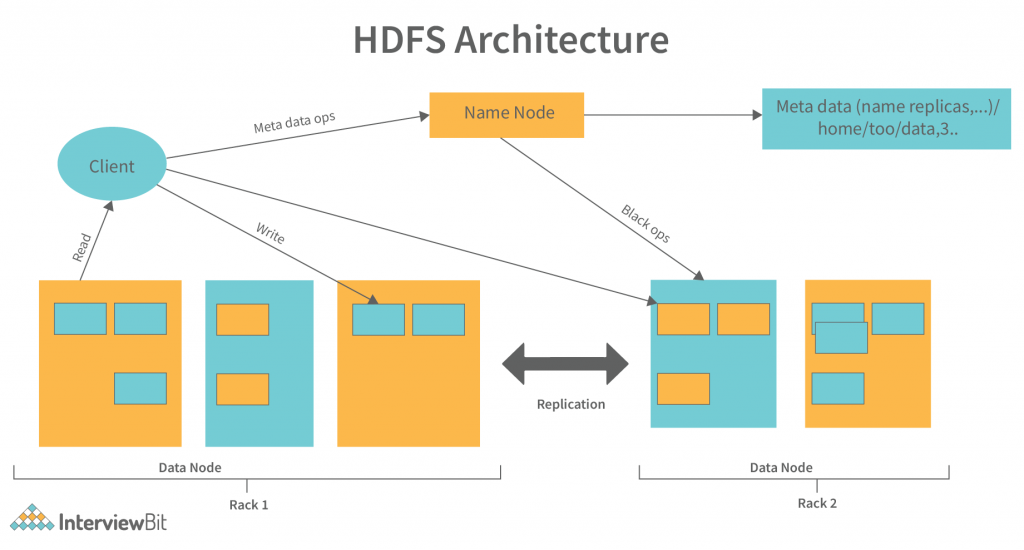
1. HDFS数据块管理概述
在大数据存储领域,Hadoop分布式文件系统(HDFS)作为核心组件,支撑起海量数据的存储与处理。本章将对HDFS中的数据块管理进行概述,为后续章节的深入探讨打下基础。
1.1 HDFS数据块的概念
HDFS将大文件切分成一系列的块(block),每个块默认大小为128MB(可配置),是进行存储和计算的基本单元。数据块的设计既满足了存储的可靠性,也支撑了高效的数据访问和恢复。
1.2 数据块管理的重要性
数据块管理是HDFS高效运转的关键。它涉及到数据块的创建、复制、恢复和优化等多个方面,直接影响到整个系统的性能和可靠性。掌握数据块管理机制,可以帮助我们更好地理解HDFS的工作原理,以及如何在实际应用中进行优化。
通过后续的章节,我们将深入解析HDFS的数据块管理原理及其操作细节,揭示HDFS如何在保证高可用性和伸缩性的同时,实现数据的有效管理和快速访问。
2. HDFS数据块的存储机制
Hadoop分布式文件系统(HDFS)是大数据存储的核心组件之一,它设计用来存储大量数据,并保证数据在出现硬件故障时的高可靠性。数据块是HDFS存储和管理数据的基本单位。深入理解HDFS数据块的存储机制,对于优化系统性能、提升数据可靠性具有重要意义。本章将详细介绍数据块的定义、特性、分布与定位、以及冗余与恢复策略。
2.1 数据块的定义与特性
2.1.1 数据块大小对性能的影响
在HDFS中,文件被切分成一系列的块,称为数据块。每个数据块的大小是预先设定的参数,默认为128MB(Hadoop 2.x之前是64MB)。数据块大小的选择对HDFS的性能有显著影响。
- 读写性能:更大的数据块意味着更少的元数据操作,因为每个文件将有更少的块,从而减少了命名节点的负载。同时,对于大文件,读写操作可以更加高效。
- 网络带宽:较大的数据块可能导致网络传输更加高效,因为它减少了网络包的数量。
- 存储利用率:较大的数据块可能会导致更差的存储利用率,因为文件末尾的剩余空间无法被其他文件复用。
2.1.2 数据块复制策略
数据块复制策略确保了数据的可靠性和容错能力。HDFS的默认复制因子是3,意味着每个数据块将被保存3份在不同的数据节点上。副本的放置策略影响着系统的性能和可靠性。
- 位置感知副本放置:HDFS努力将数据块的一个副本放在与写入数据的客户端相同的机架上,另外两个副本放在不同机架的节点上,这样即使有一个机架失效,数据仍然可用。
- 副本的自动恢复:当某个数据节点失效时,HDFS会自动创建新的副本,以保持复制因子不变。
2.2 数据块的分布与定位
2.2.1 名称节点的元数据管理
名称节点(NameNode)负责维护整个文件系统的元数据,包括文件与数据块的映射、数据块副本的位置信息等。这些信息对于管理数据块至关重要。
- 命名空间镜像:为了避免单点故障,HDFS会将命名空间镜像保存到多个辅助名称节点(Secondary NameNode)上,确保系统可靠性。
- 元数据操作:数据块的创建、删除和重命名等操作都会更新到命名节点的内存中,并定期写入到磁盘中。
2.2.2 数据节点的角色与作用
数据节点(DataNode)是HDFS的工作节点,它们存储实际的数据块,并在数据块上执行读写操作。
- 数据存储:每个数据节点都存储一部分数据块,并负责管理其生命周期。
- 块报告:数据节点会定期向名称节点发送它持有的数据块列表,这样名称节点可以准确地了解数据块的分布情况。
2.3 数据块的冗余与恢复
2.3.1 冗余策略的实现原理
数据块的冗余是通过创建和维护多个副本实现的。这使得在节点发生故障时,可以通过其他副本快速恢复数据。
- 副本放置:副本通常放置在不同的机架上,以避免机架故障导致数据丢失。
- 副本同步:写入操作在所有副本中同步完成,直到所有副本成功写入,才向客户端确认写入操作成功。
2.3.2 数据恢复流程分析
当HDFS检测到某个数据节点失效时,会启动数据恢复流程,以保证数据的高可用性。
- 副本检查:HDFS定期检查副本的一致性,并修复不一致的数据块。
- 自愈机制:当副本数量少于复制因子时,HDFS会自动创建额外的副本以满足复制要求。
在接下来的章节中,我们将深入探讨HDFS数据块的读写操作,这是数据块管理中的另一个关键话题。
3. HDFS数据块的读写操作
在存储系统中,读写操作是数据块管理的核心环节。Hadoop分布式文件系统(HDFS)对于数据的读写管理采取了独特的处理策略,确保了高吞吐量和系统的稳定性。接下来,我们将深入探讨HDFS数据块的读写操作的内部机制。
3.1 数据写入流程解析
HDFS的数据写入过程涉及到客户端与多个数据节点之间的交互。数据写入时,需要考虑到数据块的持久化和容错机制。
3.1.1 客户端写操作的步骤
客户端首先将要写入的文件分割成一系列的块(默认大小为128MB),然后将这些块分别写入到数据节点中。在这个过程中,客户端会向名称节点询问哪些数据节点可用,并从这些数据节点中选择合适的节点开始写入数据块。以下是客户端写操作的详细步骤:
- 与名称节点通信:客户端向名称节点发送写请求,并获取可用的数据节点列表。
- 建立数据管道:客户端将数据块拆分成数据包,并建立一个数据管道,将数据包顺序写入到数据节点。
- 数据写入:客户端并行向管道中的数据节点发送数据包。
- 数据确认:数据节点收到数据包后进行写入,并向客户端发送确认响应。
- 完成写入:客户端收到所有数据节点的成功确认后,认为数据块写入完成,并向名称节点报告。
3.1.2 数据块的本地写入与同步
当客户端将数据包写入到本地数据节点后,这些数据包会存储在数据节点的本地磁盘上。同时,为了保持系统的可靠性,数据包需要被复制到其他的数据节点上。数据同步和复制通常采用以下策略:
- 默认副本数设置:HDFS支持设置默认的副本数量,通常为三个。
- 写入确认机制:每个数据包在写入成功后都会收到确认,当所有副本写入成功时,才认为写入操作完成。
- 数据同步:数据节点之间会进行数据的同步,确保每个副本的数据都是一致的。
- # 示例代码:在HDFS客户端启动一个写入操作
- hadoop fs -put localfile /path/to/hdfs
上述命令会触发HDFS客户端程序,将本地文件localfile上传到HDFS上的指定路径/path/to/hdfs。这个过程背后实际上是通过调用Hadoop的Java API来实现的,涉及到客户端与名称节点、数据节点之间的通信。
3.2 数据读取流程解析
数据读取操作是从HDFS中检索数据块并将其传输给请求的客户端。HDFS通过一系列优化措施来提高读取性能,包括数据的本地化读取和负载均衡。
3.2.1 客户端读操作的步骤
当客户端发起读取请求时,HDFS会根据文件的元数据找到数据块的位置,并尽可能从最近的数据节点读取数据。以下是数据读取操作的详细步骤:
- 与名称节点通信:客户端向名称节点请求文件的数据块位置信息。
- 获取数据节点信息:名称节点返回包含所需数据块的数据节点列表。
- 选择数据节点:客户端选择最近的数据节点进行读取。
- 数据读取:客户端从选定的数据节点获取数据。
- 数据传输:数据被传输回客户端,完成读取操作。
3.2.2 数据块的定位与负载均衡
为了提高读取性能,HDFS通过数据块的定位机制和负载均衡来确保数据能够尽可能在本地或者网络上最近的数据节点被读取。
- 数据定位:名称节点通过维护的元数据来追踪每个数据块的位置。
- **

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【FLUKE_8845A_8846A维护秘籍】:专家分享的快速故障排除与校准技巧
【通信优化攻略】:深入BSW模块间通信机制,提升网络效率
EPLAN 3D功能:【从2D到3D的飞跃】:掌握设计转变的关键技术
内存优化:快速排序递归调用栈的【深度分析】与防溢出策略
无线定位技术:GPS与室内定位系统的挑战与应用
【Web开发者福音】:一站式高德地图API集成指南
【云网络模拟新趋势】:eNSP在VirtualBox中的云服务集成
【精挑细选RFID系统组件】:专家教你如何做出明智选择
【故障快速排除】:三启动U盘制作中的7大常见问题及其解决策略
空间数据分析与可视化:R语言与GIS结合的6大实战技巧


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















