




【提升HDFS吞吐量】:揭秘数据读写优化的顶级技巧


数据堡垒:揭秘Hadoop HDFS的数据备份与恢复之道
1. HDFS吞吐量的基本概念
在大数据技术生态中,Hadoop分布式文件系统(HDFS)作为一个核心组件,负责存储大量的数据集并提供高吞吐量的数据访问。理解HDFS的吞吐量对于优化存储成本和提高数据处理效率至关重要。
HDFS的工作原理
HDFS具有高度容错性的特点,采用主从(Master/Slave)架构。一个HDFS集群由一个NameNode和多个DataNode组成。NameNode负责管理文件系统的命名空间和客户端对文件的访问;DataNode则在本地文件系统中存储实际数据。数据以块(block)的形式分布在多个DataNode上,以实现并行处理和容错。
吞吐量在HDFS中的意义
吞吐量是指在单位时间内处理的数据量,是衡量HDFS性能的一个关键指标。高吞吐量意味着系统可以在较短时间内处理更多的数据,对于大规模数据分析任务至关重要。优化HDFS的吞吐量可以帮助处理大规模数据集时减少延迟,提高处理速度。
影响HDFS吞吐量的主要因素
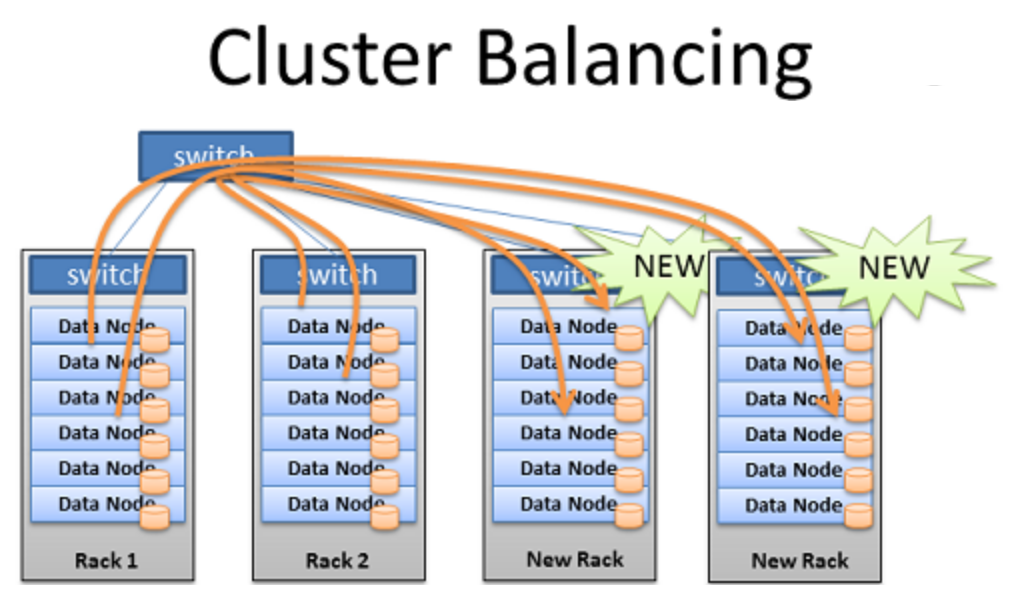
HDFS的吞吐量受到多种因素的影响,包括但不限于硬件性能(如CPU、内存、存储设备)、网络带宽、数据块大小、副本因子以及集群的负载均衡状况。合理配置这些参数和资源,可以在保证数据可靠性的同时,最大程度地提高数据处理的吞吐量。在接下来的章节中,我们将深入探讨如何通过不同的策略和优化手段来提升HDFS的吞吐量。
2. HDFS数据读写机制的理论基础
2.1 HDFS的文件块概念
2.1.1 块的定义和作用
Hadoop分布式文件系统(HDFS)将大文件分割成固定大小的数据块,这些数据块随后存储在不同的DataNode上。块的定义是HDFS设计的基础,它允许分布式存储并支持数据的容错性。每个块的默认大小通常是128MB,但它可以根据具体需求进行调整。块的主要作用包括:
- 分布式存储:每个数据块可存储在不同的数据节点上,增加了存储的可靠性。
- 并行处理:因为数据被分散存储,所以可以并行地进行读写操作。
- 容错性:若某数据节点失败,由于数据的多个副本存在,文件的完整性得以维护。
2.1.2 块的复制策略及其影响
为了提高数据的可靠性,HDFS会对每个数据块创建多个副本并存储在不同的节点上。这种复制策略称为“冗余”,默认情况下副本数量为3。块的复制策略对性能和存储效率影响显著:
- 性能提升:通过并行读取多个数据副本,可提高读取性能。
- 存储开销:副本数量的增加将消耗更多的存储空间,影响存储效率。
- 故障恢复:副本数量越多,系统容错能力越强,但也会导致写入速度变慢。
2.2 数据节点(DataNode)的角色与性能
2.2.1 DataNode的存储策略
DataNode是HDFS集群中负责存储数据块的实体。每个DataNode管理它所拥有的本地文件系统的数据块存储。DataNode的存储策略包括数据块的存储位置选择和存储空间的管理:
- 本地文件系统的优化使用:DataNode利用本地文件系统来存储数据块,这有助于提高数据块读写效率。
- 存储空间管理:DataNode负责监控磁盘空间,并进行数据块的删除和复制,以保证数据的可用性和平衡性。
2.2.2 DataNode与吞吐量的关系
DataNode的数量和性能直接影响HDFS的总体吞吐量。一个高效的数据节点可以提供更快的数据读写速度,而数据节点的不当配置可能导致性能瓶颈:
- 节点数量:增加数据节点的数量可以提供更多的存储容量,但过多的节点也可能导致管理开销增大。
- 硬件配置:数据节点的CPU、内存和磁盘配置直接影响读写性能。
2.3 NameNode的角色与性能
2.3.1 NameNode的元数据管理
NameNode是HDFS的核心组件,负责管理文件系统命名空间和客户端对文件的访问。所有的文件系统元数据都存储在NameNode上:
- 命名空间镜像:NameNode维护了所有文件和目录的信息。
- 数据块定位:客户端需要读写数据时,NameNode提供数据块的位置信息。
2.3.2 NameNode对吞吐量的影响
NameNode的性能会直接影响HDFS的总体吞吐量。特别是当处理大量小文件时,NameNode可能会成为系统的瓶颈:
- 内存限制:NameNode内存大小限制了它可以管理的文件数量。
- 处理速度:NameNode的处理速度会受到其硬件配置的影响。
在处理大规模数据时,为了提高NameNode的性能,可采用二级NameNode、联邦HDFS或高可用性配置等高级配置。
3. HDFS读写操作的性能优化实践
在大数据的存储系统中,Hadoop分布式文件系统(HDFS)因其高可靠性、高吞吐量和硬件成本低的优势,被广泛应用于数据存储解决方案中。尽管HDFS的设计使得它能够很好地应对大数据存储的挑战,但是随着业务的发展和数据量的增长,其性能优化成为了大数据生态系统中不可或缺的一环。本章将深入探讨如何通过不同的策略和技术手段,优化HDFS的读写操作性能。
3.1 优化读取性能的策略
3.1.1 增加块大小
HDFS将文件分割成一系列的块(block),默认大小为128MB。块的大小对读取性能有很大影响,因为读取操作通常需要读取整个块。当块尺寸增加时,块的数量会减少,从而减少了磁盘寻址的次数,减少了NameNode的负载,并且通常情况下,更大的块会减少HDFS上的元数据操作次数,从而提高读取性能。但是,块大小的增加也意味着在进行小文件的读取操作时,需要传输更多的数据。
示例代码:
- # 查看当前HDFS的块大小
- hdfs dfs -D dfs.block.size=128M -ls /path/to/directory
- # 修改HDFS的块大小为256MB(需要重启NameNode)
- hdfs dfsadmin -setBlocksize 256M
3.1.2 调整读缓冲区大小
HDFS客户端在读取数据时会使用缓冲区。通过调整缓冲区的大小,可以影响到读取操作的效率。缓冲区较大时,可以减少网络往返次数,但是也会增加内存消耗和延迟。通常需要在读取性能和内存消耗之间找到一个平衡点。
示例代码:
- Configuration conf = new Configuration();
- FileSystem fs = FileSystem.get

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
选择最佳5G测试工具
【Qt内存管理】:txt内容存储到数组的内存使用优化策略
ZX_1开发板编程效能提升术:代码运行更高效
实名认证系统数据保护:企业如何确保用户信息安全的秘籍
数据结构与算法:揭秘编程语言性能优化的6大关键策略
PCNM空间分析新手必读:R语言实现从入门到精通
【软件开发中的ROI分析】:如何计算项目的投资回报率
【无需繁琐配置】:Spring Boot与OpenCV快速整合的终极解决方案
【CRM行业应用案例】:第10章在不同行业的成功实践
【Docker磁盘清理艺术】:基础知识+高级技巧一次性掌握


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )




















