




【HDFS联邦与Nameservice】:提升命名空间扩展性的前沿技术

1. HDFS联邦与Nameservice简介
1.1 Hadoop Distributed File System (HDFS) 的挑战
随着大数据量的持续增长,传统的HDFS架构面临了前所未有的挑战。存储与管理海量数据的需求日益增长,但其扩展能力、高可用性以及故障转移等方面,对大数据存储解决方案提出了更高的要求。
1.2 Nameservice 的出现
为了解决这些问题,Hadoop社区引入了Nameservice的概念,允许用户创建多个命名空间,并通过增加NameNode的数量来提高系统的扩展性和高可用性。它打破了传统的命名空间和块存储的强绑定关系,为数据管理提供了更大的灵活性。
1.3 HDFS联邦的引入
HDFS联邦是Hadoop 2.0中引入的一项创新技术,它通过分布式命名空间实现了更高级别的扩展性和容错能力。联邦机制的引入使得HDFS可以在不牺牲性能的前提下,支持更多的存储节点和更高的数据吞吐量,是大数据时代背景下HDFS架构的重大演进。
以上内容简要介绍了HDFS联邦和Nameservice的背景和必要性,为理解后续章节提供了铺垫。接下来,我们深入了解HDFS联邦的核心概念和架构原理。
2. HDFS联邦的核心概念
Hadoop分布式文件系统(HDFS)的联邦架构是为了解决大规模集群的扩展性问题而设计的。它通过引入联邦机制和分布式命名服务(Nameservice),改进了HDFS的核心架构,以支持更多节点和更大规模的数据存储。本章将详细探讨HDFS联邦的核心概念,深入分析其架构原理和分布式命名的特点。
2.1 HDFS联邦的架构原理
HDFS联邦的引入是Hadoop社区为了克服单一命名空间带来的扩展性瓶颈所做出的重大改进。在了解联邦架构之前,我们需要先掌握HDFS传统的命名空间与块存储分离的设计,以及联邦机制如何解决扩展性问题。
2.1.1 命名空间与块存储的分离
传统HDFS架构中,一个NameNode负责整个文件系统的命名空间,并且管理所有的元数据。每个DataNode则存储实际的数据块。随着数据量的增长,NameNode的内存成为系统的瓶颈,从而限制了整个集群的扩展性。为了解决这一问题,HDFS联邦采取了命名空间和块存储分离的策略,使得每个NameSpace可以管理自己的元数据,而共享底层的DataNode资源。
架构上,多个NameSpace可以并存,每个NameSpace都有自己的NameNode,而DataNode是被多个NameSpace共享的。这样,即使在单一命名空间中的文件数量非常大,也不会影响到其他命名空间的性能。这种设计极大地提高了系统的可扩展性。
2.1.2 联邦机制的引入与作用
联邦机制是在Hadoop 2.x中引入的概念,它通过引入多个NameSpace来实现水平扩展。每个NameSpace拥有自己的命名空间元数据,但是可以共享数据块的存储,从而实现资源的共享和隔离。
引入联邦机制后的HDFS架构允许系统管理员为不同的应用设置不同的NameSpace,每个NameSpace可以独立进行容量规划,保证关键应用的稳定运行,而不会被其他应用的负载波动所影响。这种设计还支持热备份NameNode,从而提供高可用性。
2.2 Nameservice的分布式命名
在HDFS联邦架构中,Nameservice扮演了至关重要的角色。它负责协调多个NameSpace,实现分布式命名,并保证数据的一致性和高可用性。在这一节中,我们将深入探讨命名空间的隔离与共享机制,以及如何通过Nameservice实现高可用性和故障转移。
2.2.1 命名空间的隔离与共享
在HDFS联邦中,每个命名空间是独立管理其元数据的,因此可以实现命名空间的隔离。不同的命名空间可以对应不同的用户或应用,这样可以为特定群体提供隔离的环境,保证数据访问的安全性和稳定性。
与此同时,多个命名空间可以共享同一组DataNode,从而实现数据块存储的共享。通过联邦集群中的块存储池,数据可以高效地跨命名空间移动,这样的共享机制让数据的存储和访问变得更加灵活。
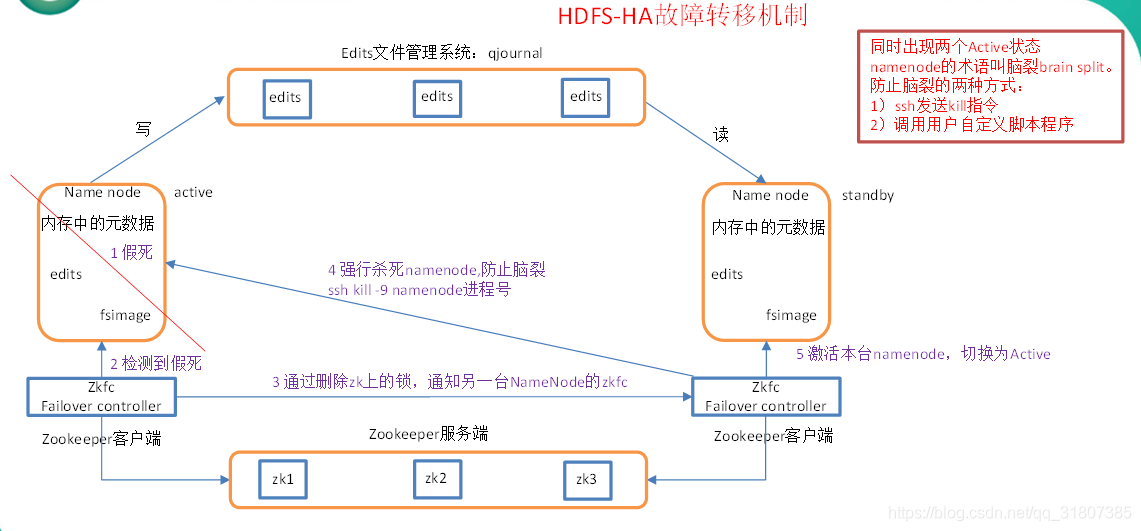
2.2.2 高可用性与故障转移机制
为了保障集群的稳定性,HDFS联邦支持高可用性(HA)和故障转移(Failover)机制。通过配置多个NameNode和相关组件,实现了主备切换和自动故障恢复。这种方式可以让HDFS在面对NameNode故障时,几乎无缝地切换到备用NameNode,从而避免单点故障导致的服务中断。
在故障转移机制中,ZooKeeper等协调服务扮演着关键角色,它帮助集群中的节点进行状态同步和故障检测。此外,通过维护NameNode的元数据日志(EditLog)和镜像(FsImage)的实时同步,确保了在发生故障转移时数据的一致性和完整性。
HDFS联邦架构的部署与配置
在了解了HDFS联邦的核心概念后,接下来将详细介绍如何在实际环境中部署和配置HDFS联邦架构。这将包括集群的环境准备、部署策略与规划,以及具体的配置步骤。
实际部署中的考量
部署HDFS联邦前,我们需要对集群环境进行充分的准备,包括硬件资源的评估、Hadoop版本的选择和软件依赖的安装。
环境配置与版本选择
首先,要根据预期的集群规模和数据处理需求选择合适的硬件配置。例如,需要有足够的内存和CPU资源以支持NameNode的运行。对于Hadoop版本,应选择支持联邦特性的稳定版本,如Hadoop 2.x系列,以确保系统功能的完整性和稳定性。
接下来,需要安装Hadoop软件包,并配置集群环境,包括设置环境变量和配置SSH免密码登录等,以简化集群节点间的通信和管理。
部署策略与规划
部署HDFS联邦时,需要制定详细的规划,包括命名空间的分配、节点角色的定义以及故障转移机制的设计。由于HDFS联邦允许添加更多的NameSpace,因此在规划阶段就需要对未来数据增长和应用需求做出预判。
在部署策略方面,通常推荐从测试环境开始,逐步过渡到生产环境,以便在实际部署中遇到问题时能够快速定位和解决。
Nameservice的配置步骤
完成环境准备和策略规划后,接下来是具体的配置步骤。重点在于配置Nameservice,确保它可以在多个NameNode之间正确地协调元数据。
NameNode配置
在HDFS联邦架构中,每个NameSpace都配置独立的NameNode。配置过程涉及到编辑hdfs-site.xml文件,设置联邦集群的属性,如启用联邦机制和定义Nameservice ID。
- <configuration>
- <property>
- <name>dfs.nameservices</name>
- <value>my-federation</value>
- </property>
- <property>
- <name>dfs.ha.namenodes.my-federation</name>
- <value>nn1,nn2</value>
- </property>
- ...
- </configuration>
每个NameNode还需要配置专用的dfs.namenode.rpc-address和dfs.namenode.http-address属性,以便正确地监听客户端请求。
ZKFailoverController(ZKFC)配置
除了NameNode的配置外,还需要配置ZKFailoverController,该组件负责监控NameNode的健康状态并进行故障转移。这涉及到编辑hdfs-site.xml文件,设置ZKFC相关属性。
- <property>
- <name>dfs.ha.fencing.methods</name>
- <value>sshfence</value>
- </property>
- <property>
- <name>dfs.ha.fencing.ssh.private-key-files</name>
- <value>/path/to/key</value>
- </property>
在这里,我们通过SSH方法来实现故障节点的隔离,确保在发生故障转移时,旧的NameNode不会干扰新的NameNode的正常运行。
联邦HDFS的搭建与配置
在完成Nameservice的配置后,接下来是如何搭建联邦HDFS集群。这包括配置DataNode以支持跨多个NameSpace共享块存储,以及配置集群间网络通信的参数。
DataNode配置
DataNode需要配置以支持联邦HDFS集群,这意味着它需要与所有配置的Nameservice进行通信。这涉及到编辑DataNode的hdfs-site.xml文件,确保DataNode可以连接到所有的Nameservice。
- <configuration>
- <property>
- <name>dfs.namenode.rpc-address.ns1.nn1</name>
- <value>namenode1:rpc-port</value>
- </property>
- <property>
- <name>dfs.namenode.rpc-address.ns1.nn2</name>
- <value>namenode2:rpc-port</value>
- </property>
- ...
- </configuration>
网络通信参数配置
为了确保集群间节点通信的流畅,需要配置适当的网络参数。这通常包括在core-site.xml文件

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【内存分配调试术】:使用malloc钩子追踪与解决内存问题
【T-Box能源管理】:智能化节电解决方案详解
Fluentd与日志驱动开发的协同效应:提升开发效率与系统监控的魔法配方
【Arcmap空间参考系统】:掌握SHP文件坐标转换与地理纠正的完整策略
戴尔笔记本BIOS语言设置:多语言界面和文档支持全面了解
【VCS高可用案例篇】:深入剖析VCS高可用案例,提炼核心实施要点
【精准测试】:确保分层数据流图准确性的完整测试方法
ISO_IEC 27000-2018标准实施准备:风险评估与策略规划的综合指南
Cygwin系统监控指南:性能监控与资源管理的7大要点


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















