【Python数学建模】:Stat库背后的统计分析数学原理
发布时间: 2024-10-10 21:04:48 阅读量: 178 订阅数: 60 
# 1. Python数学建模与Stat库概述
Python在数学建模领域持续发光发热,因其简洁语法和丰富的科学计算库,成为诸多数据分析师和科研工作者的首选工具。Stat库,作为Python众多统计分析库中的佼佼者,它将统计学的精华融入编程,为研究者提供了构建模型、进行假设检验、回归分析以及时间序列分析的强大武器。
Stat库之所以能够大放异彩,得益于它的核心特性——灵活性与强大功能的结合。它不仅简化了数据处理的流程,还提供了从描述性统计到推断性统计的各种统计方法。例如,在描述性统计分析中,Stat库能够让用户快速计算数据集的均值、中位数、方差,并通过可视化工具对数据分布进行深入探索。
随着统计分析的需求不断增长,Stat库正逐步发展成一个不可或缺的资源,支撑着数据分析和建模的各个环节。让我们揭开Python与Stat库相结合所带来的无限可能。
```python
import stat
# 加载数据集
data = stat.load('sample_data.csv')
# 基本描述性统计分析
description = data.describe()
# 输出数据集的基本统计信息
print(description)
```
以上代码块展示了如何使用Stat库进行基本的数据加载和描述性统计分析。对于数据科学家来说,Stat库不仅仅是一个工具,它更是一个深入了解数据内在规律和潜在价值的桥梁。
# 2. Python在统计分析中的基础应用
在统计分析的世界里,Python已经成为一种流行的工具,它凭借强大的数据处理能力和丰富的库支持,为数据科学家和统计分析师提供了前所未有的便利。本章将详细介绍Python在统计分析中的基础应用,涵盖数据处理、描述性统计分析,以及假设检验等方面。通过本章的学习,读者将掌握使用Python进行统计分析的基本技能,并能够将这些技能应用于实际问题的解决过程中。
### 2.1 数据处理与分析基础
数据处理是进行有效统计分析的前提。在这一部分,我们将首先介绍Python中的数据结构和数据类型,然后探讨数据清洗与预处理的基本方法。
#### 2.1.1 数据结构和数据类型
在Python中,数据结构是组织和存储数据的方式。最常用的数据结构包括列表(list)、元组(tuple)、字典(dict)和集合(set)。
- 列表是可变的有序集合,用于存储序列化的数据。
- 元组是不可变的有序集合,常用于存储异构数据。
- 字典是无序的键值对集合,用于存储键值映射关系。
- 集合是无序的唯一元素集,用于执行集合运算。
数据类型方面,Python提供了多种内置的数据类型,包括整型(int)、浮点型(float)、布尔型(bool)、字符串(str)、列表(list)、元组(tuple)、字典(dict)和集合(set)等。
```python
# 示例代码:数据结构的使用
my_list = [1, 2, 3, 4, 5] # 创建一个列表
my_tuple = (1, 2, 3, 4, 5) # 创建一个元组
my_dict = {'name': 'Alice', 'age': 25} # 创建一个字典
my_set = {1, 2, 3, 4, 5} # 创建一个集合
# 数据类型的转换
int_value = int(3.14) # 浮点转整型
float_value = float(3) # 整型转浮点型
str_value = str(123) # 整型转字符串
```
#### 2.1.2 数据清洗与预处理
数据清洗与预处理是统计分析中的关键步骤,目的是确保分析的数据质量。这通常包括处理缺失值、异常值和数据标准化。
- 缺失值处理可以通过删除缺失数据的行或列、填充缺失值(例如使用平均数、中位数或特定值填充)来完成。
- 异常值的处理通常涉及识别和修正这些值,或者在分析中排除它们。
- 数据标准化是将数据按比例缩放,使之落入一个小的特定区间,常见的方法有最小-最大标准化和z-score标准化。
```python
import pandas as pd
# 示例代码:处理缺失值
df = pd.DataFrame({
'A': [1, 2, None, 4],
'B': [4, None, 3, 1]
})
# 删除包含缺失值的行
df_cleaned = df.dropna()
# 填充缺失值
df_filled = df.fillna(0)
# 示例代码:处理异常值(使用标准差)
# 计算均值和标准差
mean = df['A'].mean()
std = df['A'].std()
# 按3倍标准差过滤异常值
df['A'] = df['A'].apply(lambda x: x if (x > (mean - 3 * std) and x < (mean + 3 * std)) else None)
```
### 2.2 描述性统计分析
描述性统计分析是对数据集的特征进行概括和总结的过程。它包括计算基本统计量,如均值、中位数和方差,以及数据分布的可视化分析。
#### 2.2.1 常用的统计度量:均值、中位数、方差
- 均值是所有数据值的总和除以数据的个数。
- 中位数是将数据集从小到大排列后位于中间位置的数。
- 方差是衡量数据分布离散程度的统计量,方差越大,数据越分散。
```python
import numpy as np
# 示例代码:计算基本统计量
data = np.array([1, 2, 3, 4, 5])
# 计算均值
mean_value = np.mean(data)
# 计算中位数
median_value = np.median(data)
# 计算方差
variance_value = np.var(data)
print(f"Mean: {mean_value}, Median: {median_value}, Variance: {variance_value}")
```
#### 2.2.2 数据分布的可视化分析
数据分布可视化分析是利用图形展示数据分布的中心位置、离散程度和形状。最常用的可视化工具是直方图和箱线图。
- 直方图通过将数值数据分组到连续的区间或“桶”中,并计算每个桶中的数据点数量,来展示数据分布。
- 箱线图展示了数据的五个主要统计特征:最小值、第一四分位数(Q1)、中位数、第三四分位数(Q3)和最大值。
```python
import matplotlib.pyplot as plt
# 示例代码:绘制直方图和箱线图
plt.figure(figsize=(12, 6))
# 绘制直方图
plt.subplot(1, 2, 1)
plt.hist(data, bins=5, color='blue', alpha=0.7)
plt.title("Histogram of Data")
# 绘制箱线图
plt.subplot(1, 2, 2)
plt.boxplot(data, vert=False)
plt.title("Boxplot of Data")
plt.show()
```
### 2.3 假设检验基础
假设检验是统计决策的一种方法,它通过样本数据来推断总体的参数。其基本概念和步骤包括建立原假设和备择假设、选择适当的检验方法、计算检验统计量、确定显著性水平和作出决策。
#### 2.3.1 假设检验的概念和步骤
- 原假设(H0)通常表示一个关于总体参数的假设,没有效应或者没有差异。
- 备择假设(H1 或 Ha)与原假设相对立,表示效应或者有差异。
- 显著性水平(α)是犯第一类错误(拒真错误)的概率阈值。
- 检验统计量的计算根据样本数据和分布规律进行。
- 最后,根据检验统计量和显著性水平比较,决定是拒绝原假设还是不拒绝原假设。
```python
from scipy.stats import ttest_1samp
# 示例代码:单样本t检验
sample_data = np.array([1, 2, 3, 4, 5])
population_mean = 3 # 假设的总体均值
# 进行单样本t检验
t_stat, p_value = ttest_1samp(sample_data, population_mean)
print(f"t-statistic: {t_stat}, p-value: {p_value}")
alpha = 0.05
if p_value < alpha:
print("拒绝原假设")
else:
print("不拒绝原假设")
```
#### 2.3.2 常用的统计检验方法
在统计学中,有许多常用的检验方法,如t检验、卡方检验、ANOVA等。每种检验方法适用于不同类型的数据和研究设计。
- t检验用于比较两个均值差异是否显著,分为独立样本t检验和配对样本t检验。
- 卡方检验用于检验两个分类变量是否独立。
- ANOVA(方差分析)用于比较三个或更多样本均值。
```python
from scipy.stats import f_oneway
# 示例代码:单因素ANOVA
group1 = np.random.normal(0, 1, 100)
group2 = np.random.normal(0.5, 1, 100)
group3 = np.random.normal(1, 1, 100)
# 进行ANOVA检验
f_stat, p_value = f_oneway(group1, group2, group3)
print(f"F-statistic: {f_stat}, p-value: {p_value}")
```
通过本章的内容,您将掌握Python在统计分析中的基础应用,包括数据处理与分析、描述性统计分析以及假设检验。接下来的章节将进一步介绍Stat库的核心统计功能,包括参数估计、回归分析、时间序列分析等内容,为深入理解和应用统计方法打下坚实的基础。
# 3. Stat库的核心统计功能
## 3.1 参数估计与置信区间
### 3.1.1 点估计和区间估计的概念
在统计推断中,参数估计是用来从样本数据中推断总体参数的方法。点估计是指用单个值作为总体参数的估计,这个值是样本统计量的函数。点估计的一个典型例子是对均值、方差、比例等的估计。
区间估计则提供了估计的范围,这个范围被称为置信区间,它给出了总体参数的可能范围,而不是单一值。这个区间是以一定的置信水平确定的,通常用百分比表示,例如95%置信区间。构建置信区间的核心思想是,如果实验无限次,那么总体参数将有95%的概率落在这个区间内。
### 3.1.2 置信区间的计算与解释
要计算置信区间,首先需要确定总体参数的估计值,然后根据样本统计量的分布确定置信区间的边界。例如,对于正态分布的总体均值的估计,如果总体方差已知,可以使用z分布;如果总体方差未知,则使用t分布。
在Python中,我们可以使用`scipy.stats`模块来计算置信区间。假设我们有一个样本数据集,我们可以如下计算均值的95%置信区间:
```python
import numpy as np
from scipy import stats
# 假设样本数据集
data = np.array([1.2, 1.5, 2.3, 3.2, 4.5, 5.7, 6.1])
# 计算均值
mean = np.mean(data)
# 计算
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以 Python 的 stat 库为中心,提供了一系列全面且深入的指南,涵盖从入门到高级技巧的各个方面。通过一系列文章,专栏探讨了 stat 库的统计编程功能,包括数据分析、模型构建、性能优化和可视化。它还深入研究了 stat 库的工作机制、常见陷阱、大数据环境中的应用以及机器学习中的角色。此外,专栏还提供了自定义工具、数据安全分析和数学建模等高级主题的见解。无论您是数据分析新手还是经验丰富的专业人士,本专栏都将为您提供宝贵的知识和技巧,帮助您充分利用 stat 库进行统计编程。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【DEH调节逻辑图解】:掌握基础知识,精通应用

# 摘要
本文系统地介绍了DEH(Digital Electro-Hydraulic)调节系统的理论基础与实践应用。首先解释了DEH系统的工作原理,阐述了其组成和基本流程。接着,文章深入分析了DEH调节中的关键参数,包括压力、温度设定点,流量控制和功率调节,以及PID(比例、积分、微分)控制的解析。此外,本文还探讨了DEH调节系统与其他系统的协同
【AT32F435手册深度解读】:揭秘隐藏性能参数与应用技巧
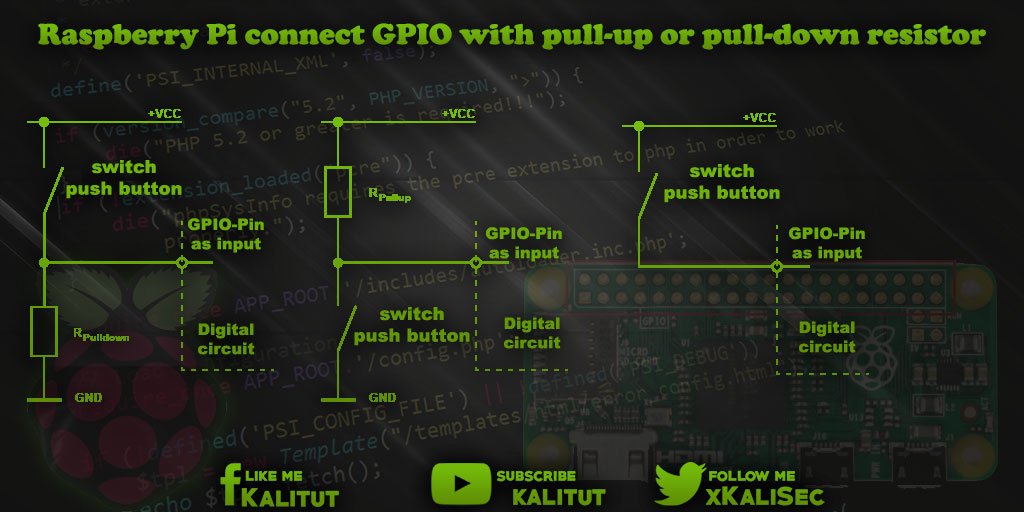
# 摘要
本文全面介绍了AT32F435微控制器,从其概述开始,深入分析了硬件架构和内存存储配置,探讨了高性能的ARM Cortex-M4内核特性及其性能参数。详细讨论了编程与开发环境,强调了IDE配置、调试技巧以及编程接口的优化。文章进一步探索了AT32F435的高级功能,包括电源管理、安全特性、实时时钟等,并分析了在工业自动化控制、消费电子产品和无线通信应用中的
【sCMOS相机驱动电路全攻略】:20年经验大师带你破解设计与故障处理的神秘面纱
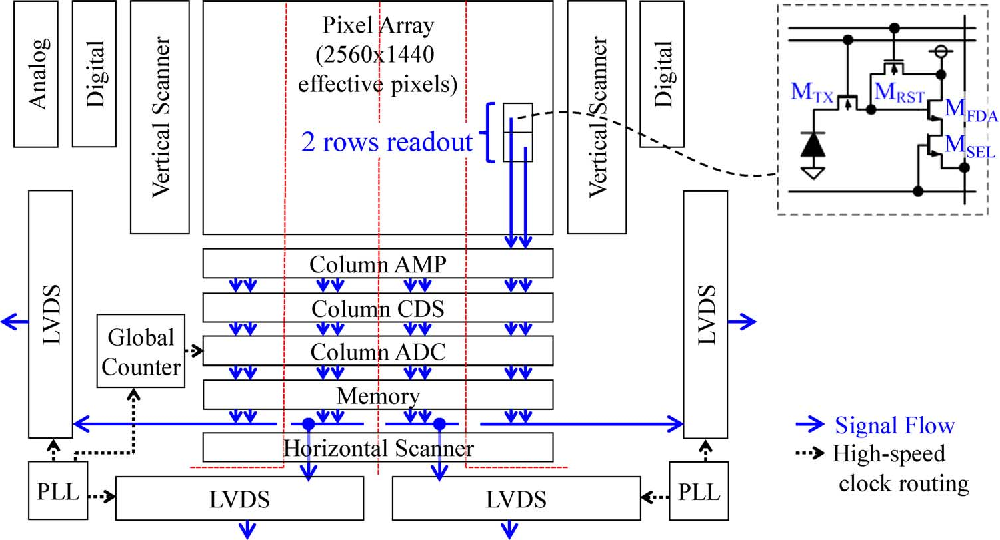
# 摘要
本论文全面介绍了sCMOS相机驱动电路的设计原理、实践与高级应用,并对故障处理技巧和未来发展趋势进行了深入探讨。首先概述了sCMOS相机驱动电路的基本概念及其重要性,接着从理论基础入手,详尽分析了sCMOS相机的工作原理、关键参数和信号完整性。在设计实践章节中,讨论了电路设计前期准备、布局布线以及调试测试的
【自动售货机界面设计】:交互逻辑实现的秘诀

# 摘要
自动售货机界面设计是提升用户体验、增强交互效率及实现技术革新的关键要素。本文详细探讨了自动售货机界面设计的理论基础,如用户体验的重要性、界面设计的交互原则及布局视觉层次。接着,文章深入分析了界面交互逻辑,包括导航、交易流程和错误处理的设计。在实践层面,本文阐述了用户研究、原型设计、用户测试以及迭代优化的过程。技术实现部分则讨论了界面开发工具、功能模块编码和测试方法。最后
【CAD2002块操作全攻略】
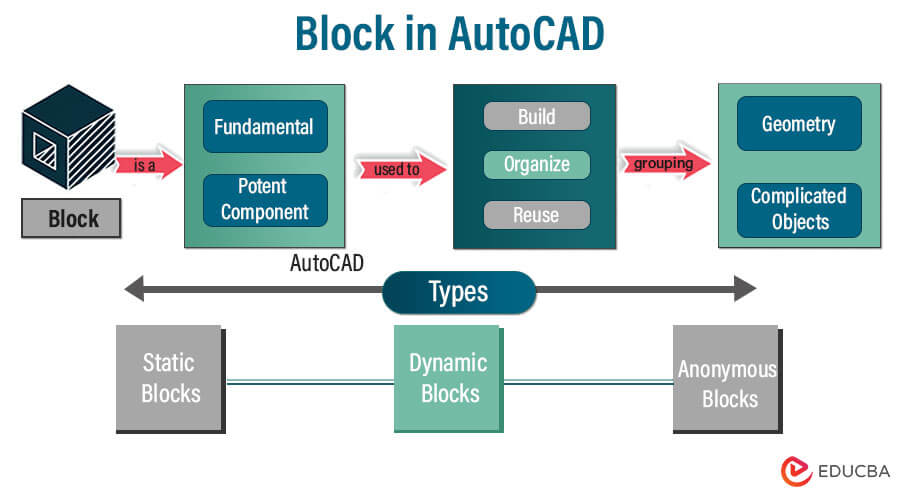
# 摘要
CAD块操作是提高CAD绘图效率和标准化的关键技术。本文旨在介绍CAD块操作的基本知识,包括块的创建、编辑、命名及属性管理。进一步探讨高级技巧,如动态块的创建和使用,以及块与外部数据库的交互。文章还涵盖了块操作在实际应用中的案例分析,例如工程图纸中的块应用,协作设计中块操作的应用,以及自动化工具的开发。最后,本文针对块操作中可能遇到的常见问题,提出相应的诊断方法和性能优化策略,并通过案例
【MATLAB内存布局精通】:数组方向性对性能影响的深入剖析

# 摘要
本文综合探讨了MATLAB中数组方向性对性能的影响,并提出了相应的性能优化策略。首先,从理论层面分析了数组方向性的重要性以及其如何影响缓存效率,并构建了相应的数学模型。其次,本文深入到MATLAB的实践操作,探讨了方向性在性能优化中的具体应用,并通过案例研究展示了方向性优化的实际效果。文章还详细阐述了优化算法的设计原则,研究了MATLAB内置函数及自定义函
C语言回调函数:使用技巧与实现细节详解
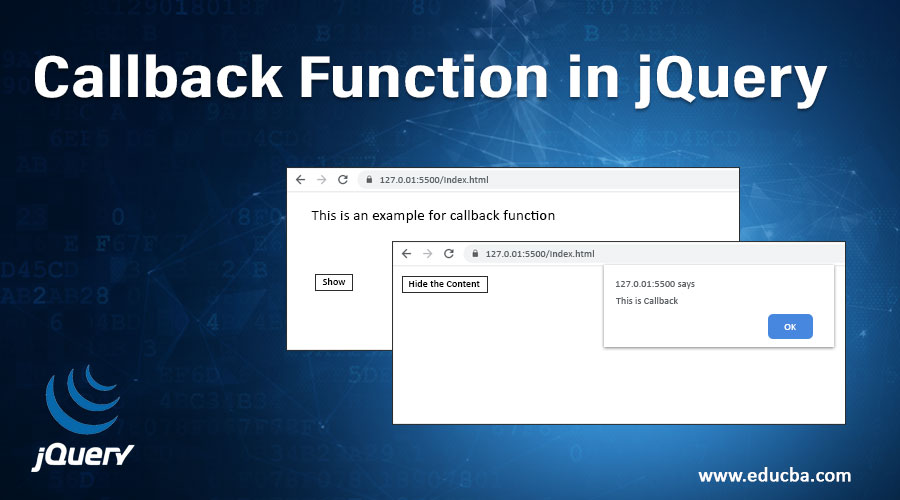
# 摘要
回调函数是软件开发中广泛应用的一种编程技术,它允许在程序执行的某个点调用一个预先定义的函数,从而实现模块化和事件驱动的程序设计。本文详细探讨了回调函数的基本概念和在C语言中使用函数指针实现回调的技巧。通过分析典型的使用场景,如事件处理和算法设计模式,本文提供了如何在C语言中高效且安全地使用回调函数的深入指导。此外,文中还介绍了性能优化和安全注意事项,包括减少开销、防止内存泄漏、回调注入攻
【监控大师】:掌握西门子SINUMERIK测量循环,实现生产过程全面监控
# 摘要
本文全面探讨了SINUMERIK测量循环的理论基础、实践应用以及监控大师系统在其中所扮演的角色。首先介绍了测量循环的基本概念、分类、特点和参数设置,其次解析了监控大师系统的架构和功能模块,并说明了如何利用该系统实现对生产过程的全面监控。文章重点通过实际案例分析,展示了测量循环在生产中的应用,并探讨了监控大师在实时监控和故障预测中的作用,以及如何通过这些技术提升生产效率和质量。最后,文章讨论了系统优化的策略,面临的挑战和未来发展趋势,并分享了成功的案例研究与经验。
# 关键字
SINUMERIK测量循环;系统架构;实时监控;生产效率;故障预测;案例研究
参考资源链接:[西门子SIN
Word 2016 Endnotes加载项:提升工作流的十个技巧

# 摘要
本文系统地介绍了Word 2016中Endnotes加载项的使用方法和技巧,阐述了Endnotes的基本概念、作用以及其在提升文档质量和优化工作流中的重要性。文章详细描述了Endnotes加载项的安装、配置和个性化设置,同时提供了管理尾注的策略和与文献管理软件整合的方法。此外,文章还探讨了在Word中快速插入和编辑Endnotes的技巧,分享了提高文档一致性和工作效率的高
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )