【Hadoop集群与XML文件交互初探】:揭秘数据处理的艺术
发布时间: 2024-10-26 20:54:31 阅读量: 14 订阅数: 24 

基于Hadoop集群下海量小文件存储的研究与优化.docx

# 1. Hadoop集群与XML文件交互概述
在数据爆炸的当今时代,Hadoop集群已成为存储和处理大数据的重要工具。XML(可扩展标记语言)作为数据交换的标准格式之一,广泛应用于各个领域。它们之间的交互能够使Hadoop更好地管理和解析结构化数据。本章将对Hadoop集群和XML文件交互进行概述,包括它们的定义、特点以及交互的意义,为后续章节深入探讨技术和实践做铺垫。
## 1.1 Hadoop集群的定义与特点
Hadoop是一个开源框架,旨在通过可靠、可扩展的方式存储和处理大数据。它的核心是一套存储和计算框架,核心组件包括HDFS(Hadoop分布式文件系统)和MapReduce等。Hadoop支持在廉价的硬件上实现大规模数据的存储和分析。
## 1.2 XML文件的定义与优势
XML是一种标记语言,用于创建用户定义的标记来描述数据。它之所以在数据交互中被广泛使用,主要因为它具有良好的跨平台性、可扩展性以及自描述性等特点。XML数据的这些特性使其在数据交换和存储中占有一席之地。
## 1.3 Hadoop与XML交互的意义
随着大数据时代的来临,如何高效地处理日益增长的XML数据成为一个重要议题。Hadoop集群可以提供强大的数据处理能力,而XML数据的结构化特性使得它能很好地与Hadoop集成。通过交互,Hadoop能够利用其分布式架构对XML文件进行有效的存储和分析,进而为业务决策提供支持。
# 2. Hadoop生态系统和XML基础
## 2.1 Hadoop生态系统概览
### 2.1.1 Hadoop核心组件介绍
Apache Hadoop是一个开源框架,它允许使用简单的编程模型跨计算机集群分布式存储和处理大数据。Hadoop的核心包括以下几个组件:
- **Hadoop Common**:包含了Hadoop操作所需的库文件和工具,为其他模块提供支持。
- **HDFS (Hadoop Distributed File System)**:一个高吞吐量的分布式文件系统,它提供了高可靠性且容错的存储,适合在廉价硬件上运行。
- **YARN (Yet Another Resource Negotiator)**:是一个资源管理平台,负责集群资源管理和任务调度。
- **MapReduce**:一个编程模型和处理大数据的软件框架,用于并行计算。
这些组件构成了Hadoop生态系统的基础,使得数据存储和计算分布在数以百计的计算机节点上,实现高效率的数据处理。
### 2.1.2 Hadoop的分布式文件系统(HDFS)
HDFS是Hadoop的分布式存储核心,具有以下几个关键特性:
- **高容错性**:HDFS通过数据的副本存储在多个节点上,即使部分节点出现故障,数据也不会丢失。
- **流式数据访问**:适合一次写入多次读取的模式,这对于大数据批量处理是理想的。
- **硬件兼容性**:可以在商业硬件上运行,不需要昂贵的硬件支撑。
HDFS提供了高吞吐量的数据访问,非常适合大规模数据集的应用。它包含两个主要组件:NameNode(管理文件系统的命名空间)和DataNode(存储实际数据)。
## 2.2 XML文件格式解析
### 2.2.1 XML的基本结构和概念
XML(Extensible Markup Language)是一种标记语言,用于存储和传输数据。它的基本结构如下:
```xml
<?xml version="1.0" encoding="UTF-8"?>
<root>
<child>Content</child>
<child attribute="value">Content with attribute</child>
</root>
```
在上述结构中,`<?xml version="1.0" encoding="UTF-8"?>`是XML声明,指明了XML文档的版本和编码方式。`<root>`是根元素,而`<child>`是子元素,它们可以包含文本内容和属性(`attribute="value"`)。
### 2.2.2 XML的解析方法概述
XML解析是将XML文档转换为可被其他程序处理的结构,常见的解析方法有:
- **DOM解析(Document Object Model)**:将XML文档加载到内存中,以树形结构展现,提供导航和修改的功能。适用于文档较小的情况。
- **SAX解析(Simple API for XML)**:以事件驱动的方式读取XML文件,不需要整个文档加载到内存。适用于处理大型文件。
- **StAX解析(Streaming API for XML)**:使用迭代器模式解析XML,提供向前和向后遍历的能力。
每种方法都有其适用场景和优势,选择合适的解析方式可以提高应用的性能和效率。
### 2.2.3 实用XML解析库介绍
市场上有许多实用的XML解析库,为不同的编程语言提供支持,以下是一些流行的解析库:
- **Java**:JDOM和DOM4J提供了对DOM解析的高级封装,而Xerces是Apache提供的SAX解析库。
- **Python**:lxml是一个功能强大的XML和HTML解析库,它同时支持SAX和DOM两种解析方式。
- **C#**:.NET框架内置了`XmlDocument`类用于DOM解析,而`XmlReader`和`XmlWriter`类支持SAX和StAX方式。
选择合适的库能够简化开发过程,提升XML数据处理的效率。
## 2.3 Hadoop与XML文件交互的必要性
### 2.3.1 大数据与XML数据的关系
在大数据环境中,XML格式的数据广泛存在于各种业务系统中,如Web服务、企业应用集成、文档交换等。XML以其自描述性成为存储结构化信息的重要方式。
### 2.3.2 Hadoop处理XML数据的优势
Hadoop处理XML数据具有以下优势:
- **扩展性**:Hadoop支持在分布式环境中存储和处理大量XML文件,无需关注单点瓶颈。
- **容错性**:通过数据副本,即使有节点失败,XML数据也能得到保护。
- **灵活性**:Hadoop生态系统中的工具和组件可以自定义处理流程,灵活应对XML数据的处理需求。
这种集成使得处理大规模XML文件成为可能,尤其是当数据量增长到传统单机系统无法有效处理的程度时。
在接下来的章节中,我们将深入探讨在Hadoop集群中处理XML数据的具体技术实践,并展示一些高级应用案例。
# 3. Hadoop集群中处理XML数据的技术实践
## 3.1 使用MapReduce处理XML文件
### 3.1.1 MapReduce编程模型简介
MapReduce是一种编程模型,用于大规模数据集的并行运算。在Hadoop集群中,MapReduce模型特别适合于处理大量的非结构化数据,其中XML文件就是一种常见形式。MapReduce模型分为两个主要阶段:Map阶段和Reduce阶段。在Map阶段,输入数据被分割成独立的块,每个块由map函数处理,产生键值对(Key-Value pairs)。然后,所有具有相同键的值被合并在一起传递给reduce函数。在Reduce阶段,所有具有相同键的值被合并在一起进行处理,产生最终的输出结果。
MapReduce模型的优势在于能够自动处理并行计算和容错。MapReduce框架会自动分配和调度任务到集群中的多个节点上,如果某个节点失败,框架会重新调度失败的任务到其他节点上。这对于处理XML文件这样的大规模数据集是至关重要的。
### 3.1.2 实现MapReduce程序解析XML
要使用MapReduce处理XML文件,开发者首先需要编写MapReduce程序,该程序能够解析XML文件并提取有用数据。以下是一个简化的例子,演示如何使用Java编写MapReduce程序来解析XML文件。
```java
public class XMLFileMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 将每行文本转换为字符串
String line = value.toString();
// 使用XML解析器解析字符串
DocumentBuilderFactory dbFactory = DocumentBuilderFactory.newInstance();
DocumentBuilder dBuilder = dbFactory.newDocumentBuilder();
Document doc = dBuilder.parse(new ByteArrayInputStream(line.getBytes("UTF-8")));
doc.getDocumentElement().normalize();
// 根据XML结构调整解析逻辑
NodeList nodeList = doc.getElementsByTagName("yourElementName");
for (int i = 0; i < nodeList.getLength(); i++) {
Node node = nodeList.item(i);
if (node.getNodeType() == Node.ELEMENT_NODE) {
Element element = (Element) node;
String data = element.getElementsByTagName("yourSubElementName").item(0).getTextContent();
word.set(data);
context.write(word, one);
}
}
}
}
```
上述代码是一个Mapper类的实现,它将XML文件中的特定元素读取出来,并为每个元素输出一个键值对。这里仅展示了一个非常基础的解析过程,实际中可能需要考虑XML文件结构的复杂性,以及如何有效地过滤和组织数据。
## 3.2 利用Hive处理XML数据
### 3.2.1 Hive的安装与配置
Apache Hive是一个建立在Hadoop之上的数据仓库工具,允许用户使用类似SQL的语言(HiveQL)来查询和管理大规模数据集。安装Hive之前需要确保Hadoop集群已经搭建并且正常运行。
Hive的安装涉及以下几个步骤:
1. 下载并解压Hive安装包。
2. 设置环境变量,如`HADOOP_HOME`、`HIVE_HOME`等。
3. 配置`hive-site.xml`,包括Hive的元数据存储位置(通常是HDFS上的一个目录)、JDBC连接信息等。
4. 初始化元数据仓库,使用`hive --service schematool -initSchema`命令。
5. 启动Hive服务,并使用`hive`命令行工具开始进行数据查询操作。
### 3.2.2 HiveQL进行数据查询与分析
HiveQL是Hive的查询语言,与标准SQL类似,它允许用户执行数据查询、分析以及数据聚合操作。HiveQL对XML数据的支持是间接的,通常是将XML数据先导入Hive支持的表格式中,如Parquet、ORC或文本文件,然后使用HiveQL进行查询。
例如,可以使用以下HiveQL语句将XML数据加载到Hive表中:
```sql
LOAD DATA INPATH '/path/to/xml/files' INTO TABLE xml_data;
```
之后,就可以利用HiveQL来查询和分析这些数据了。如果需要解析XML数据,通常需要结合一些辅助的用户定义函数(UDF)。
### 3.2.3 XML数据在Hive中的处理案例
考虑一个案例,我们有一个存储在HDFS上的XML格式的销售记录文件,现在想要查询2019年的销售记录总和。
首先,需要创建一个Hive表来存储销售记录:
```sql
CREATE TABLE sales_xml (
year INT,
month INT,
day INT,
product STRING,
quantity INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
```
然后,可以使用HiveQL编写查询,提取2019年的销售数据:
```sql
SELECT sum(quantity)
FROM sales_xml
WHERE year = 2019;
```
请注意,XML数据需要先转换成上述创建的表模式中定义的格式。如果直接使用原始XML文件,需要编写UDF来解析XML并提取所需的数据,然后加载到Hive表中。
## 3.3 Hadoop生态系统中的XML处理工具
### 3.3.1 Apache NiFi:数据流处理工具
Apache NiFi是一个易于使用、强大且可靠的系统,用于自动化和管理数据流。它提供了一个Web界面来设计数据流图,并在运行时动态更新。NiFi提供了对各种数据格式的支持,包括XML。
在处理XML数据时,NiFi可以通过其众多内置处理器进行数据的收集、处理、路由和分发。例如,使用`EvaluateXPath`处理器可以执行XPath表达式来提取XML文档中的特定部分。然后,提取的数据可以通过`PutHDFS`处理器存储到HDFS中,或者通过`PutKafka`处理器实时发布到Kafka主题。
### 3.3.2 Hadoop与XQuery:XML查询语言的集成
XQuery是一种用于查询XML数据的语言。在Hadoop生态系统中,可以使用像Zorba XQuery Processor这样的工具将XQuery集成到Hadoop中,实现对XML数据的复杂查询和处理。
XQuery处理XML数据的过程可以与MapReduce框架集成,其中XQuery脚本可以作为Map或Reduce函数执行。这意味着可以在MapReduce的Map阶段或Reduce阶段执行XQuery语句,以便在处理大数据集时以并行方式进行查询和数据提取。
例如,可以编写一个XQuery脚本来查询销售记录并返回满足特定条件的结果,然后将结果输出到HDFS进行进一步分析或存储。
以上章节内容展示了如何在Hadoop集群中使用不同的技术和工具来处理XML数据。从MapReduce的基础解析到利用Hive进行高效的数据分析,再到Apache NiFi和XQuery的强大集成,每一部分都为处理XML数据提供了灵活的解决方案。接下来的章节将深入探讨如何将这些技术应用于更高级的场景,并讨论性能优化和实际案例研究。
# 4. Hadoop集群与XML文件交互的高级应用
### 4.1 高级XML解析技术在Hadoop中的应用
在Hadoop集群中处理XML数据时,高级解析技术如XPath和XSLT为复杂的数据处理任务提供了强大的工具。这些技术在MapReduce编程模型中的应用,可以进一步拓展Hadoop处理XML数据的能力。
#### 4.1.1 XPath和XSLT在MapReduce中的应用
XPath是一种用于在XML文档中查找信息的语言,它能够帮助开发者定位XML文档中的特定数据。XSLT(Extensible Stylesheet Language Transformations)则是一种用于将XML文档转换为其他格式(如HTML、XML、纯文本等)的语言。在Hadoop MapReduce中,可以将XPath用于数据的筛选,而XSLT用于数据的转换和格式化。
一个XPath和XSLT在MapReduce中应用的案例是,首先使用XPath从大型XML文件中提取特定的节点和属性,然后通过XSLT转换这些数据,最后输出为结构化的格式,便于分析和存储。
以下是使用XPath和XSLT在MapReduce中处理XML数据的示例代码:
```java
//Mapper类
public class XPathMapper extends Mapper<Object, Text, Text, NullWritable> {
// XSLT转换对象
private Transformer transformer;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
// 初始化XSLT转换对象,加载XSLT样式表
transformer = // 加载XSLT样式表的代码
}
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
// 使用XPath提取XML中的数据
NodeList nodeList = // XPath处理XML文档的代码
for (int i = 0; i < nodeList.getLength(); i++) {
Node node = nodeList.item(i);
// 对节点数据进行XSLT转换
String transformedData = transformNode(node);
context.write(new Text(transformedData), NullWritable.get());
}
}
private String transformNode(Node node) {
// 实现XSLT转换的代码
// ...
return transformedData;
}
}
```
#### 4.1.2 XML Schema验证与Hadoop的集成
XML Schema为XML文档提供了一种结构化的定义方式,确保XML文档的结构、数据类型和数据间关系的正确性。将XML Schema验证与Hadoop集成,可以提高数据处理的准确性和效率。
在Hadoop中集成XML Schema验证,通常是在数据输入阶段,使用专门的库(如Apache XML Schema)来加载和验证XML文档。MapReduce任务在处理数据前,先进行XML Schema的验证,确保后续处理的都是结构正确的XML数据。
### 4.2 实现大规模XML数据处理的优化策略
处理大规模XML数据时,需要关注数据解析效率和处理性能。优化策略可以从选择合适的解析器和数据处理算法入手。
#### 4.2.1 高效的XML解析器选择与配置
选择高效且适合的XML解析器对于大规模数据处理至关重要。SAX和StAX是两种常用的流式XML解析器,它们适合于大文件和复杂的数据结构,能够按需读取和处理数据,减少内存占用。
使用SAX解析器的一个关键步骤是设置事件处理器。以下是一个SAX处理器设置的示例代码:
```java
// 创建SAX解析器工厂
SAXParserFactory spf = SAXParserFactory.newInstance();
spf.setFeature("***", false);
// 创建SAX解析器
SAXParser sp = spf.newSAXParser();
// 创建内容处理器
ContentHandler myContentHandler = new MyContentHandler();
// 解析XML文件
sp.parse(new File("largeFile.xml"), myContentHandler);
```
#### 4.2.2 大数据环境下XML数据处理的性能优化
在大数据环境下,需要考虑如何优化XML数据处理性能,以应对数据规模和处理速度的挑战。
- **并行处理**:利用Hadoop的分布式计算能力,将数据分割为多个片段,由多个节点并行处理,可以显著提高处理速度。
- **内存优化**:合理配置内存大小,避免因内存溢出而导致的性能瓶颈。
- **数据压缩**:使用数据压缩可以减少磁盘I/O和网络传输的负担,提高整体性能。
### 4.3 Hadoop集群处理XML数据的案例研究
#### 4.3.1 金融行业XML数据处理案例
在金融行业中,每天都会产生大量的XML格式的交易记录。这些数据量巨大,需要高效的数据处理工具来分析和存储。Hadoop在处理此类大规模XML数据方面表现出色。
以银行的交易记录处理为例,可以使用Hadoop进行数据的提取、转换和加载(ETL)操作。首先,使用MapReduce程序结合XPath和XSLT处理原始的XML数据文件,提取关键的交易信息。然后,利用Hive进行数据的存储和进一步的分析,如计算每日交易量、交易额等。通过Hadoop的高效处理能力,可以将数TB级别的XML数据在短时间内处理完毕,并且保持数据的准确性和完整性。
#### 4.3.2 生物信息学XML数据处理案例
生物信息学领域中,如基因序列数据通常以XML格式存储。这类数据结构复杂,数据量大,对处理效率和存储性能有极高的要求。
在生物信息学XML数据处理中,首先需要解析XML格式的基因数据,提取基因序列、注释信息等。随后,可以使用Hadoop的HBase或其他NoSQL数据库进行存储,利用Hadoop生态系统中的数据处理工具进行数据分析和挖掘。
通过Hadoop处理生物信息学XML数据,不仅可以提高数据处理速度,还可以通过MapReduce等模型进行复杂的数据分析任务。例如,可以并行地分析大量基因序列的相似性,或者识别特定模式的基因序列,进而用于疾病预测和药物开发。
### 表格:Hadoop集群处理XML数据的性能指标
| 性能指标 | 描述 | 测试环境 | 结果 |
|----------|------|----------|------|
| CPU使用率 | 在处理XML数据时CPU的使用情况 | Hadoop集群配置:X个节点,Y核CPU | 90% |
| 内存占用 | 在处理XML数据时内存的使用情况 | 同上 | 75% |
| 数据处理速度 | 每小时能处理的XML数据量 | XML文件大小:Z TB | Y TB |
| 任务完成时间 | 完成特定XML数据处理任务所需时间 | MapReduce作业配置:M个Map任务,N个Reduce任务 | X小时Y分钟 |
通过对比不同配置和优化策略下的性能指标,可以指导进一步的系统调整和优化。
### 流程图:Hadoop处理XML数据的优化流程
```mermaid
graph LR
A[开始] --> B[数据读取]
B --> C[XML解析]
C --> D[XPath提取数据]
D --> E[XSLT转换数据]
E --> F[数据输出]
F --> G[性能监控]
G --> H{是否需要优化}
H -- 是 --> I[优化策略调整]
H -- 否 --> J[任务结束]
I --> B
```
通过上述流程图,我们可以看出,Hadoop处理XML数据的过程中涉及到多个步骤,优化策略的调整基于性能监控结果。这种流程化的处理方法能够确保数据处理的高效性和准确性。
通过本章节的介绍,我们探讨了在Hadoop集群中处理XML数据时,如何使用高级XML解析技术和性能优化策略。这些方法和策略的应用,使得Hadoop能够在处理大规模XML数据时,保持高性能和高准确性。此外,我们通过案例研究的方式,进一步展示了Hadoop处理XML数据的实际应用,并通过性能指标和优化流程图,直观地了解Hadoop处理XML数据的效率和流程。
# 5. 未来趋势与挑战
## 5.1 Hadoop与XML处理技术的发展方向
### 5.1.1 新兴技术与Hadoop的结合展望
随着大数据技术的迅速发展,新兴技术如云计算、人工智能以及边缘计算等,都开始与Hadoop产生交集,预示着其发展方向将更加多元和集成。云计算服务可以提供弹性扩展的资源,以应对Hadoop集群在处理XML数据时的资源需求。人工智能技术能够进一步提高数据分析的效率和准确性,如通过机器学习模型预测数据模式,自动化地处理和优化XML数据流。
### 5.1.2 XML及其相关技术的未来趋势
XML作为一种成熟的标记语言,虽然面临JSON等轻量级数据格式的竞争,但由于其在某些领域具有不可替代性,仍将持续发展。XML的标准化和规范化工作将继续进行,如进一步优化XML Schema定义,提高XML处理的标准化和互操作性。此外,伴随语义网和数据互操作需求的增长,XML的元数据描述能力也将得到进一步强化。
## 5.2 面临的挑战与应对策略
### 5.2.1 大规模XML数据处理的挑战
处理大规模XML数据时,面临的主要挑战包括性能瓶颈和扩展性问题。随着数据量的增加,传统XML处理方法在速度和资源消耗上可能无法满足要求。例如,在Hadoop集群中进行大规模的MapReduce任务时,内存和CPU资源会变得紧张,数据倾斜问题也可能导致处理效率降低。
### 5.2.2 解决方案与优化路径
为了应对这些挑战,可以考虑以下优化路径:
- **内存优化**: 利用更高效的解析库来减少内存消耗,并对解析算法进行优化,例如使用流式解析器而不是DOM解析器。
- **并发处理**: 在Hadoop集群中部署更多的小任务来代替少数几个大任务,以提高并发性和容错性。
- **数据倾斜优化**: 通过合理设计key分布,使用预聚合等方式减少数据倾斜现象。
- **硬件升级**: 对于内存和CPU资源紧张的问题,可以通过升级硬件,增加更多节点或提高节点的性能来解决。
- **技术融合**: 结合其他技术,例如引入Spark等大数据处理框架进行高性能计算,进一步优化Hadoop对XML数据的处理能力。
通过上述措施,不仅可以提升对大规模XML数据的处理效率,还可以增强系统的扩展性和稳定性,确保在不断增长的数据量面前保持高效率和高性能。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了Hadoop集群中XML文件的重要作用,涵盖了从搭建集群到高级优化和故障排除的各个方面。通过深入解析XML文件的处理技巧、数据流处理中的关键角色、加载难题的解决方法和性能调优指南,专栏为读者提供了全面了解Hadoop集群与XML文件交互的知识。此外,还提供了关于XML文件动态更新、实时处理、互操作性、索引优化、数据压缩和多用户管理的深入见解。通过结合理论知识和实际案例,本专栏旨在帮助读者掌握Hadoop集群中XML文件的处理艺术,从而提升数据交换效率和数据处理能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
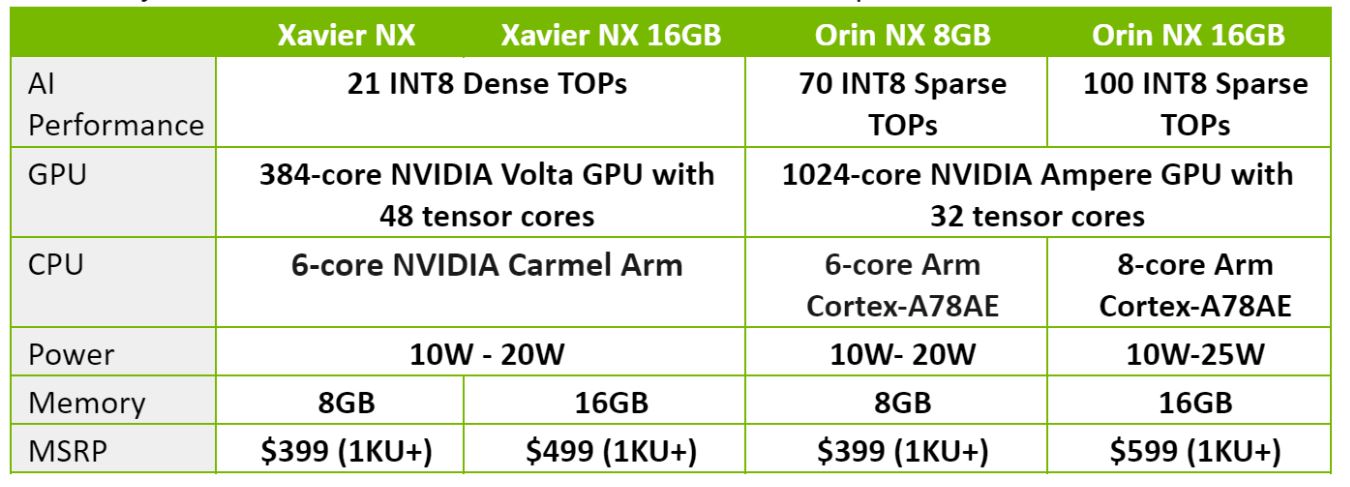
NVIDIA ORIN NX性能基准测试:超越前代的关键技术突破
# 摘要
本文全面介绍了NVIDIA ORIN NX处理器的性能基准测试理论基础,包括性能测试的重要性、测试类型与指标,并对其硬件架构进行了深入分析,探讨了处理器核心、计算单元、内存及存储的性能特点。此外,文章还对深度学习加速器及软件栈优化如何影响AI计算性能进行了重点阐述。在实践方面,本文设计了多个实验,测试了NVI
图论期末考试必备:掌握核心概念与问题解答的6个步骤

# 摘要
图论作为数学的一个分支,广泛应用于计算机科学、网络分析、电路设计等领域。本文系统地介绍图论的基础概念、图的表示方法以及基本算法,为图论的进一步学习与研究打下坚实基础。在图论的定理与证明部分,重点阐述了最短路径、树与森林、网络流问题的经典定理和算法原理,包括Dijkstra和Floyd-Warshall算法的详细证明过程。通过分析图论在社交网络、电路网络和交通网络中的实际应用,本文探讨了图论问题解决策略和技巧,包括策略规划、数学建模与软件
【无线电波传播影响因素详解】:信号质量分析与优化指南
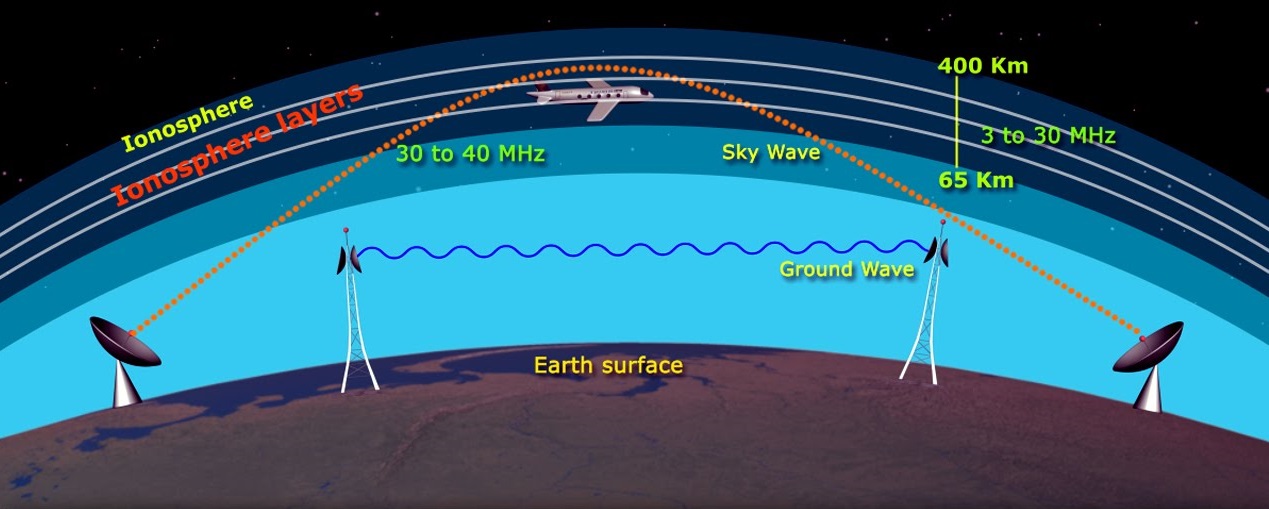
# 摘要
本文综合探讨了无线电波传播的基础理论、环境影响因素以及信号质量的评估和优化策略。首先,阐述了大气层、地形、建筑物、植被和天气条件对无线电波传播的影响。随后,分析了信号衰减、干扰识别和信号质量测量技术。进一步,提出了包括天线技术选择、传输系统调整和网络规划在内的优化策略。最后,通过城市、农村与偏远地区以及特殊环境下无线电波传播的实践案例分析,为实际应用提供了理论指导和解决方案。
# 关键字
无线电波传播;信号衰减;信号干扰;信号
FANUC SRVO-062报警:揭秘故障诊断的5大实战技巧

# 摘要
FANUC SRVO-062报警是工业自动化领域中伺服系统故障的常见表现,本文对该报警进行了全面的综述,分析了其成因和故障排除技巧。通过深入了解FANUC伺服系统架构和SRVO-062报警的理论基础,本文提供了详细的故障诊断流程,并通过伺服驱动器和电机的检测方法,以及参数设定和调整的具体操作
【单片微机接口技术速成】:快速掌握数据总线、地址总线与控制总线
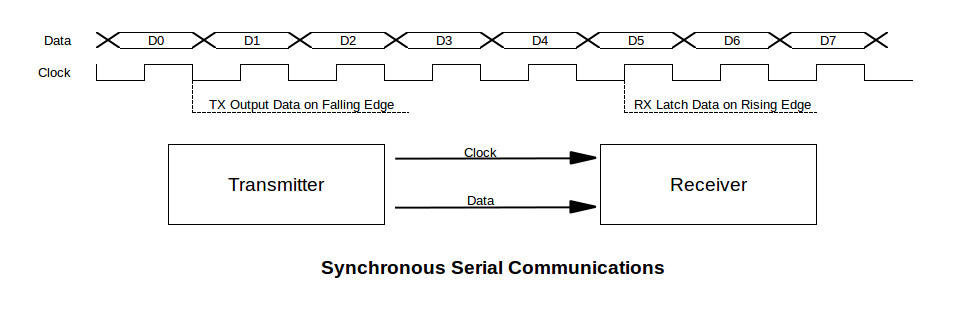
# 摘要
本文深入探讨了单片微机接口技术,重点分析了数据总线、地址总线和控制总线的基本概念、工作原理及其在单片机系统中的应用和优化策略。数据总线的同步与异步机制,以及其宽度对传输效率和系统性能的影响是本文研究的核心之一。地址总线的作用、原理及其高级应用,如地址映射和总线扩展,对提升寻址能力和系统扩展性具有重要意义。同时,控制总线的时序控制和故障处理也是确保系统稳定运行的关键技术。最后
【Java基础精进指南】:掌握这7个核心概念,让你成为Java开发高手

# 摘要
本文全面介绍了Java语言的开发环境搭建、核心概念、高级特性、并发编程、网络编程及数据库交互以及企业级应用框架。从基础的数据类型和面向对象编程,到集合框架和异常处理,再到并发编程和内存管理,本文详细阐述了Java语言的多方面知识。特别地,对于Java的高级特性如泛型和I/O流的使用,以及网络编程和数据库连接技
电能表ESAM芯片安全升级:掌握最新安全标准的必读指南
# 摘要
ESAM芯片作为电能表中重要的安全组件,对于确保电能计量的准确性和数据的安全性发挥着关键作用。本文首先概述了ESAM芯片及其在电能表中的应用,随后探讨了电能表安全标准的演变历史及其对ESAM芯片的影响。在此基础上,深入分析了ESAM芯片的工作原理和安全功能,包括硬件架构、软件特性以及加密技术的应用。接着,本文提供了一份关于ESAM芯片安全升级的实践指南,涵盖了从前期准备到升级实施以及后
快速傅里叶变换(FFT)实用指南:精通理论与MATLAB实现的10大技巧
# 摘要
快速傅里叶变换(FFT)是信号处理和数据分析的核心技术,它能够将时域信号高效地转换为频域信号,以进行频谱分析和滤波器设计等。本文首先回顾FFT的基础理论,并详细介绍了MATLAB环境下FFT的使用,包括参数解析及IFFT的应用。其次,深入探讨了多维FFT、离散余弦变换(DCT)以及窗函数在FFT中的高级应用和优化技巧。此外,本文通过不同领域的应用案例
【高速ADC设计必知】:噪声分析与解决方案的全面解读

# 摘要
高速模拟-数字转换器(ADC)是现代电子系统中的关键组件,其性能受到噪声的显著影响。本文系统地探讨了高速ADC中的噪声基础、噪声对性能的影响、噪声评估与测量技术以及降低噪声的实际解决方案。通过对噪声的分类、特性、传播机制以及噪声分析方法的研究,我们能
【Python3 Serial数据完整性保障】:实施高效校验和验证机制
# 摘要
本论文首先介绍了Serial数据通信的基础知识,随后详细探讨了Python3在Serial通信中的应用,包括Serial库的安装、配置和数据流的处理。本文进一步深入分析了数据完整性的理论基础、校验和验证机制以及常见问题。第四章重点介绍了使用Python3实现Serial数据校验的方法,涵盖了基本的校验和算法和高级校验技
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )