【Hadoop集群中XML文件的安全性问题】:全面分析与防范策略
发布时间: 2024-10-26 21:18:05 阅读量: 23 订阅数: 24 

果壳处理器研究小组(Topic基于RISCV64果核处理器的卷积神经网络加速器研究)详细文档+全部资料+优秀项目+源码.zip
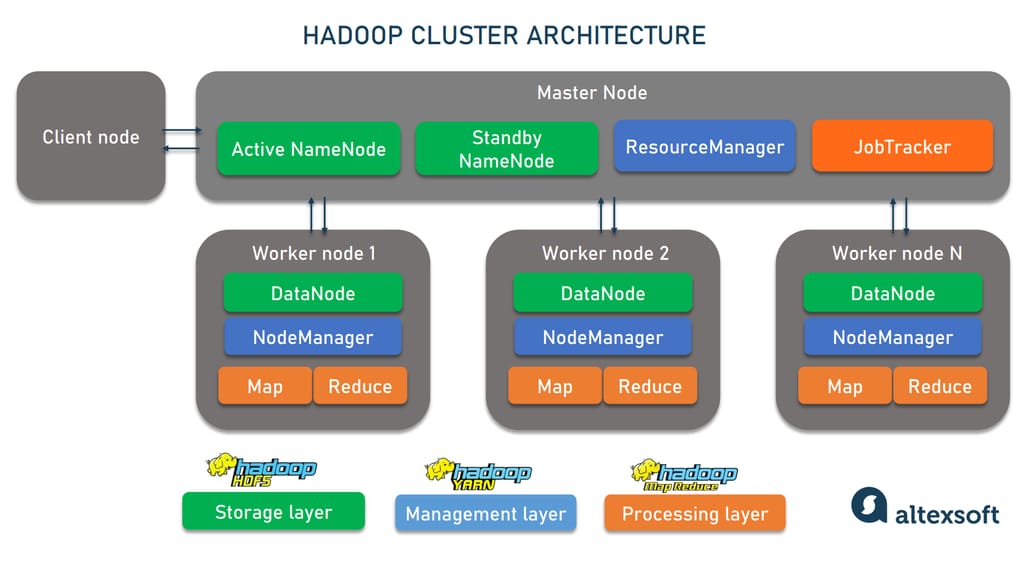
# 1. XML文件在Hadoop集群中的作用与基础
## 1.1 XML文件的定义与功能
可扩展标记语言(Extensible Markup Language, XML)是一种用于存储和传输数据的标记语言和字符编码标准。在Hadoop集群中,XML文件主要用于配置管理,允许系统管理员存储和传递各种配置信息。
## 1.2 XML文件在Hadoop中的应用
在Hadoop生态系统中,XML文件常用于配置各种服务(如HDFS和YARN)的参数。此外,XML作为数据交换格式,在处理不同数据源之间的数据迁移和存储时,扮演着重要的角色。
## 1.3 XML文件结构剖析
理解XML文件的基础结构对于正确管理和解析数据至关重要。XML文件由元素(elements)、属性(attributes)和实体(entities)组成。元素构成了文件的骨架,属性提供了额外的信息,而实体则允许定义文档中的替代文本。
```
<?xml version="1.0"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://namenode:8020</value>
</property>
<!-- 更多配置 -->
</configuration>
```
以上XML结构示例中,`<configuration>`元素包含了Hadoop集群的配置信息,`<property>`定义了具体的配置项,而`<name>`和`<value>`则提供了配置项的名称和值。
# 2. XML文件安全性问题的理论基础
## 2.1 XML文件的结构与组成
### 2.1.1 XML元素、属性和实体的定义
XML(Extensible Markup Language)作为一种标记语言,被广泛用于存储、传输和交换数据。其基本单位包括元素(Elements)、属性(Attributes)和实体(Entities)。
**元素**是XML文档的核心,它由开始标签(start tag)、结束标签(end tag)以及标签之间的数据组成,形如`<element>data</element>`。元素可以包含其他元素,形成层次化的结构。
**属性**是定义在元素开始标签内部的名称/值对,提供关于元素的附加信息。例如,在`<person gender="female">`中,`gender="female"`是属性。
**实体**用于定义XML中引用的通用和重复内容。实体可以是一个文本片段或对其他文件的引用。在XML中定义实体,可以使用`<!ENTITY entity_name "replacement text">`。
### 2.1.2 XML文档类型定义(DTD)与模式(Schema)
DTD(Document Type Definition)和Schema是定义XML文档结构、元素和属性的正式规范。
**DTD**声明了文档结构、元素类型和属性列表,以及它们之间的关系。它使用一组预定义的语法规则。例如,DTD片段`<!DOCTYPE root SYSTEM "my.dtd">`声明了文档类型并链接到一个外部的DTD文件。
**Schema**提供了比DTD更丰富的数据建模能力。它支持数据类型的定义、元素和属性的出现次数限制、元素的继承等。一个简单的Schema示例可能看起来像这样:
```xml
<xs:schema xmlns:xs="***">
<xs:element name="book" type="BookType"/>
<xs:complexType name="BookType">
<xs:sequence>
<xs:element name="title" type="xs:string"/>
<xs:element name="author" type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:schema>
```
Schema的使用越来越普遍,因为它们是XML Schema语言编写的,相比DTD提供更强的数据类型支持。
## 2.2 XML安全性问题的类型
### 2.2.1 XML注入攻击
XML注入攻击类似于常见的SQL注入,攻击者通过注入恶意的XML代码来操纵XML解析器。如果应用程序没有正确地处理用户输入,就可能受到这种攻击。
举个例子,若应用程序将用户输入拼接成XML文档,未进行适当的处理或验证,恶意用户可能会构造如`</tag1><tag2>Malicious</tag2>`这样的输入,这可能会导致解析错误或执行未授权的操作。
### 2.2.2 XML外部实体攻击(XXE)
XML外部实体(XXE)攻击利用了XML解析器处理外部实体的方式。攻击者可以引入外部实体来读取本地文件系统的内容,或者对内部系统发起请求。
例如,如果一个XML文档定义了一个外部实体,如`<!DOCTYPE root [<!ENTITY xxe SYSTEM "***">]>`,解析器就会尝试读取并包含`/etc/passwd`文件的内容,导致敏感信息泄露。
### 2.2.3 XML签名与加密问题
XML签名和加密用于保证消息的完整性和机密性。但存在一些实现不当的情况,比如使用了弱加密算法,或者在签名过程中存在验证漏洞,可能会被利用来破解加密或伪造签名。
例如,在使用XML签名时,如果签名不包括重要的上下文信息,或者签名算法不足够强健,那么就有可能出现签名被绕过的情况。
## 2.3 安全性问题的影响
### 2.3.1 数据泄露与隐私风险
由于XML文件广泛用于存储和交换敏感数据,安全性问题可能导致数据泄露,进而引起隐私风险。一旦敏感信息落入未经授权的第三方手中,将对个人隐私和企业安全造成严重威胁。
### 2.3.2 服务拒绝与资源消耗
XML注入和XXE攻击等安全性问题可能引起服务拒绝(DoS)或分布式服务拒绝攻击(DDoS)。攻击者可能通过大量请求消耗服务器资源,导致合法用户的服务不可用。
## 2.3.3 相关代码示例
下面是一个简单的PHP代码示例,展示了如何将用户输入直接插入到XML文件中,这是典型的不安全实践:
```php
<?php
$userInput = $_GET['input'];
$xml = new DOMDocument();
$xml->loadXML("<data>$userInput</data>");
echo $xml->saveXML();
?>
```
如果用户输入是`</data><evil>Malicious</evil>`,则最终生成的XML将包含攻击者定义的恶意内容,可能导致严重的安全漏洞。
### 2.3.4 代码逻辑分析与扩展性说明
在上述PHP代码示例中,`$_GET['input']`直接取自用户输入,没有经过任何清洗或验证,这将直接暴露XML注入的风险。应使用如下代码逻辑替代:
```php
$userInput
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了Hadoop集群中XML文件的重要作用,涵盖了从搭建集群到高级优化和故障排除的各个方面。通过深入解析XML文件的处理技巧、数据流处理中的关键角色、加载难题的解决方法和性能调优指南,专栏为读者提供了全面了解Hadoop集群与XML文件交互的知识。此外,还提供了关于XML文件动态更新、实时处理、互操作性、索引优化、数据压缩和多用户管理的深入见解。通过结合理论知识和实际案例,本专栏旨在帮助读者掌握Hadoop集群中XML文件的处理艺术,从而提升数据交换效率和数据处理能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Ansys高级功能深入指南】:揭秘压电参数设置的秘诀
# 摘要
随着现代工程技术的不断发展,压电材料和器件的应用越来越广泛。本文系统地介绍了Ansys软件在压电分析中的基础应用与高级技巧,探讨了压电效应的基本原理、材料参数设定、非线性分析、网格划分、边界条件设定以及多物理场耦合等问题。通过对典型压电传感器与执行器的仿真案例分析,本文展示了如何利用Ansys进行有效的压电仿真,并对仿真结果的验证与优化策略进行了详细阐述。文章还展望了新型压电材料的开发、高性能计算与Ansys融合的未来趋势,并讨论了当前面临的技术挑战与未来发展方向,为压电领域的研究与应用提供了有价值的参考。
# 关键字
Ansys;压电分析;压电效应;材料参数;仿真优化;多物理场耦
微波毫米波集成电路散热解决方案:降低功耗与提升性能

# 摘要
微波毫米波集成电路在高性能电子系统中扮演着关键角色,其散热问题直接影响到集成电路的性能与可靠性。本文综述了微波毫米波集成电路的热问题、热管理的重要性以及创新散热技术。重点分析了传统与创新散热技术的原理及应用,并通过案例分析展示实际应用中的散热优化与性能提升。文章还展望了未来微波毫米波集成电路散热技术的
【模拟与数字信号处理】:第三版习题详解,理论实践双丰收

# 摘要
本文系统阐述了模拟与数字信号处理的基础知识,重点介绍了信号的时域与频域分析方法,以及数字信号处理的实现技术。文中详细分析了时域信号处理的基本概念,包括卷积和相关理论,以及频域信号处理中的傅里叶变换原理和频域滤波器设计。进一步,本文探讨了离散时间信号处理技术、FIR与IIR滤波器设计方法,以及数字信号处理快速算法,如快速傅里叶变换(FFT)。在数字信号处理中的模拟接
【编程语言演化图谱】

# 摘要
本文综合分析了编程语言的历史演变、编程范式的理论基础、编程语言设计原则,以及编程语言的未来趋势。首先,回顾了编程语言的发展历程,探讨了不同编程范式的核心思想及其语言特性。其次,深入探讨了编程语言的设计原则,包括语言的简洁性、类型系统、并发模型及其对性能优化的影响。本文还展望了新兴编程语言特性、跨平台能力的发展,以及与人工智能技术的融合
企业网络性能分析:NetIQ Chariot 5.4报告解读实战
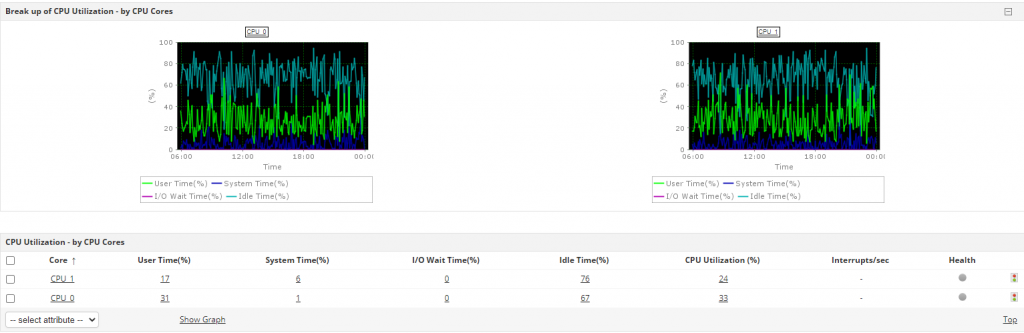
# 摘要
NetIQ Chariot 5.4是一个强大的网络性能测试工具,本文提供了对该工具的全面概览,包括其安装、配置及如何使用它进行实战演练。文章首先介绍了网络性能分析的基础理论,包括关键性能指标(如吞吐量、延迟和包丢失率)和不同性能分析方法(如基线测试、压力测试和持续监控)。随后,重点讨
【PCM数据恢复秘籍】:应对意外断电与数据丢失的有效方法

# 摘要
相变存储器(PCM)是一种新兴的非易失性存储技术,以其高速读写能力受到关注。然而,由于各种原因,PCM数据丢失的情况时常发生,对数据安全构成威胁。本文全面概述了PCM数据恢复的相关知识,从PCM和数据丢失原理出发,阐述了数据丢失的原因和数据恢复的理论基础。通过实战操作的介绍,详细讲解了数据恢复工具的选择、数据备份的重要性,以及实践中的恢复步骤和故障排除技巧。进一步,文章探讨了高级PCM数据恢复技术,包括数据存储机制、
调谐系统:优化收音机调谐机制与调整技巧

# 摘要
本文全面探讨了收音机调谐原理与机制,涵盖了调谐系统的基础理论、关键组件、性能指标以及调整技巧。通过对调谐工作原理的详尽分析,本研究揭示了电磁波、变容二极管、线圈、振荡器和混频器在调谐系统中的关键作用。同时,本文还介绍了调谐频率微调、接收能力增强及音质改善的实践应用技巧。在此基础上,探讨了数字化调谐技术、软件优化和未
EPC C1G2协议深度剖析:揭秘标签与读写器沟通的奥秘

# 摘要
EPC C1G2协议作为物联网领域的重要技术标准,广泛应用于物品识别和信息交互。本文旨在全面概述EPC C1G2协议的基本架构、通信原理、实践应用以及优化策略和挑战。通过对协议栈结构、核心组件和功能、调制与解调技术、防碰撞机制及数据加密与安全的深入解析,阐述了标签与读写器之间的高效通信过程。进一步地,本文探讨了标签编程、读写器配
【热分析高级技巧】:活化能数据解读的专家指南
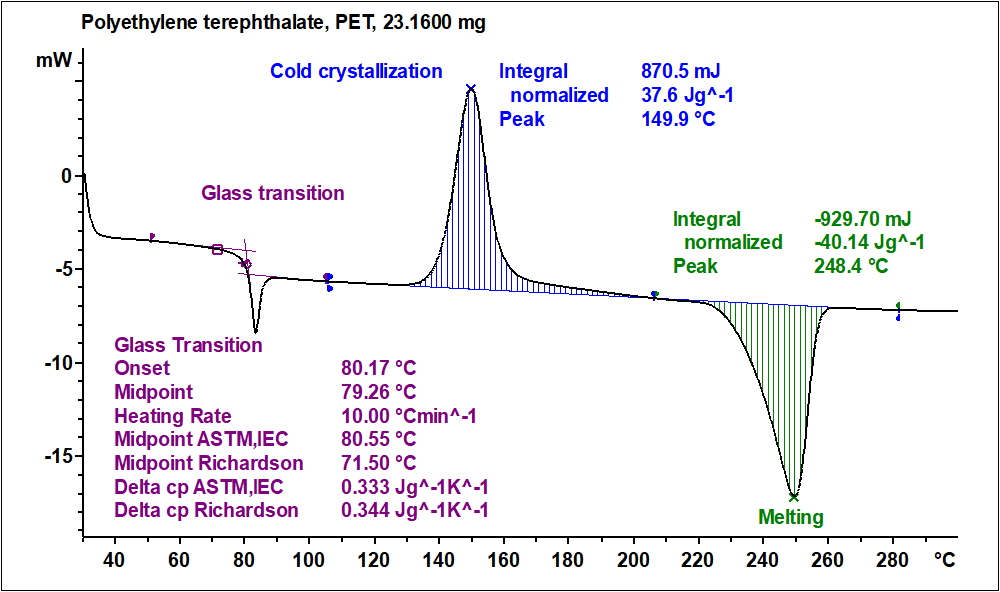
# 摘要
热分析技术作为物质特性研究的重要方法,涉及到对材料在温度变化下的物理和化学行为进行监测。本论文全面概述了热分析技术的基础知识,重点阐述了活化能理论,探讨了活化能的定义、重要性以及其与化学反应速率的关系。文章详细介绍了活化能的多种计算方法,包括阿伦尼乌斯方程及其他模型,并讨论了活化能数据分析技术,如热动力学分析法和微分扫描量热法(DSC)。同时,本文还提供了活化能实验操作技巧,包括实验设计、样品准备、仪器使用
ETA6884移动电源市场分析:揭示其在竞争中的优势地位

# 摘要
本文首先概述了当前移动电源市场的现状与趋势,随后深入分析了ETA6884移动电源的产品特点、市场定位以及核心竞争力。通过对ETA6884的设计构造、技术规格、市场定位策略以及用户反馈进行详细探讨,揭示了该产品在移动电源市场中的优势和市场表现。接着,本文探讨了ETA6884的技术优势,包括先进的电池技术、智能化管理系统的兼容性以及环
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )