【实践篇】:Python Web开发者的福音!一步到位集成MySQLdb与Flask
发布时间: 2024-10-05 00:37:13 阅读量: 22 订阅数: 30 
# 1. Python Web开发基础与框架概览
Python作为一门高效且易于学习的编程语言,在Web开发领域中占据着重要的地位。在开始深入探讨如何将MySQL数据库与Python Web框架集成之前,我们需要先对Python Web开发的基础和框架有一个全面的概览。
Web开发不仅仅是将数据存入数据库然后展示给用户那么简单。它涉及到前端与后端的配合,用户请求的处理,数据的安全性管理,以及用户体验的优化等多个方面。Python的Web框架如Django和Flask等,为开发者提供了便捷的工具和接口,简化了这些复杂的过程。
在这一章节中,我们将首先介绍Python Web开发的基本概念,包括HTTP协议、Web服务器、MVC架构模式等基础知识。然后,我们会概览Python中几个流行的Web框架,如Flask和Django,了解它们各自的设计理念以及适用场景,为后续章节的深入学习打下坚实的基础。接下来,我们将逐步深入了解各个框架的特点,以便在实际开发中选择最适合项目的那一款。
```python
# 示例代码:一个简单的Flask应用的启动代码
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello, World!'
if __name__ == '__main__':
app.run()
```
在上述代码中,我们创建了一个Flask应用实例,定义了一个路由`/`,并为它绑定了一个视图函数`hello_world`,该函数返回字符串`'Hello, World!'`。当用户访问根地址时,将看到返回的信息。这只是Flask框架的冰山一角,后续章节将详细解释这些概念并展示如何构建更加复杂的Web应用。
# 2. 集成MySQLdb到Python项目
## 2.1 MySQLdb数据库接口介绍
### 2.1.1 MySQLdb的特点和安装
MySQLdb是一个在Python中访问MySQL数据库的库。它实现了Python数据库API规范(PEP-249),使得Python开发者能够利用标准的编程模式来操作MySQL数据库。MySQLdb广泛应用于Web开发中,支持事务处理、游标操作、预编译语句等高级数据库功能。
**安装MySQLdb:**
要安装MySQLdb,最简单的方式是使用pip:
```bash
pip install mysqlclient
```
需要注意的是,mysqlclient可能会依赖于mysql的开发库,所以如果你在安装时遇到了问题,可能需要先安装MySQL的开发库。在Ubuntu系统上,你可以使用以下命令进行安装:
```bash
sudo apt-get install python-dev mysql-server libmysqlclient-dev
```
在macOS上,你可以通过Homebrew安装MySQL的开发包:
```bash
brew install mysql
```
安装完成后,可以使用以下Python代码来测试安装是否成功:
```python
import MySQLdb
```
如果上述导入没有出现错误,那么表示MySQLdb已经成功安装在你的系统上了。
### 2.1.2 连接和关闭MySQL数据库
**连接数据库:**
在Python中使用MySQLdb连接MySQL数据库的基本过程如下:
```python
import MySQLdb
# 连接数据库
db = MySQLdb.connect(host='localhost', user='user', passwd='password', db='dbname')
```
上述代码中,我们使用`MySQLdb.connect()`方法连接到本地MySQL服务器上的`dbname`数据库。`user`和`password`是访问数据库的用户名和密码。
**关闭数据库连接:**
完成数据库操作后,应该关闭数据库连接,释放资源:
```python
db.close()
```
这个操作应该在`finally`块中执行,确保即使在发生异常时,数据库连接也会被正确关闭:
```python
try:
# 执行数据库操作
pass
finally:
db.close()
```
### 2.2 MySQLdb在Python中的数据操作
#### 2.2.1 数据库连接与游标对象的使用
**创建游标对象:**
在执行任何数据库操作之前,通常需要创建一个游标对象:
```python
cursor = db.cursor()
```
游标对象允许我们执行SQL语句,并处理这些语句的执行结果。通过游标对象,我们可以检索查询结果,遍历游标返回的每一行数据。
**使用游标执行SQL语句:**
执行SQL语句通常通过`execute()`方法进行:
```python
cursor.execute("SELECT * FROM users")
```
如果SQL语句是查询类的,可以通过`fetchone()`或`fetchall()`方法获取结果集:
```python
result = cursor.fetchone() # 获取一条数据
results = cursor.fetchall() # 获取所有数据
```
#### 2.2.2 SQL语句的执行和结果的处理
执行插入、更新、删除等非查询SQL语句时,使用`execute()`方法即可。然后可以通过`***mit()`提交事务。
```python
cursor.execute("INSERT INTO users (name, age) VALUES (%s, %s)", ('Alice', 25))
***mit()
```
在处理查询结果时,除了使用`fetchone()`和`fetchall()`方法,还可以使用`for`循环直接遍历游标对象:
```python
for (id, name, age) in cursor.execute("SELECT * FROM users"):
print(id, name, age)
```
对于获取到的每一行数据,可以使用索引访问或通过列名访问:
```python
for row in cursor:
print(row[0], row['name'], row[1])
```
### 2.3 MySQLdb高级特性与优化技巧
#### 2.3.1 事务处理和锁机制
MySQLdb支持多级事务处理。可以通过`with`语句块或调用`db.autocommit()`方法来控制事务的开启和提交。
**使用`with`语句处理事务:**
```python
with db:
cursor.execute("UPDATE users SET age=%s WHERE name=%s", (new_age, name))
```
在这个例子中,如果在`with`语句块中的操作全部成功,那么事务将会自动提交;如果有任何操作失败,整个事务将会回滚。
**锁机制:**
在处理并发操作时,MySQLdb也支持锁机制。通过游标的`execute()`方法执行SQL语句时,可以指定锁类型:
```python
cursor.execute("SELECT * FROM table_name WHERE condition LOCK IN SHARE MODE")
```
上面的SQL语句中,我们指定了`LOCK IN SHARE MODE`,它表示获取共享读锁。
#### 2.3.2 性能调优和常见问题解决
性能调优是数据库操作中不可或缺的一部分。针对MySQLdb,性能调优可以从以下几个方面入手:
- 使用参数化查询(预编译语句),避免SQL注入风险,同时提升执行效率。
- 优化SQL语句,使用`EXPLAIN`关键字分析查询执行计划。
- 对于大数据集的操作,分批处理可以减少内存消耗,提高程序稳定性。
- 适当使用索引,加速查询速度。
对于常见的问题解决,可以:
- 检查MySQL数据库的状态和配置,确保它运行在最佳性能。
- 使用MySQLdb的异常处理机制来捕获并处理可能发生的错误。
- 定期备份数据库,以便在发生问题时可以快速恢复。
## 2.2 MySQLdb在Python中的数据操作
### 2.2.1 数据库连接与游标对象的使用
在开始使用数据库之前,首先需要创建一个数据库连接,然后在此连接的基础上创建游标对象。
**创建游标对象:**
游标对象是数据库编程中的一个核心概念,它允许程序执行SQL语句并处理SQL语句的返回结果。在Python中,可以使用以下代码创建游标对象:
```python
import MySQLdb
# 连接数据库
db = MySQLdb.connect(host='localhost', user='user', passwd='password', db='database')
# 创建游标对象
cursor = db.cursor()
```
在这里,我们首先导入MySQLdb模块,然后使用`MySQLdb.connect()`方法连接到数据库服务器。该方法的参数包括服务器地址、用户名、密码和数据库名称。连接成功后,我们通过调用连接对象`db`的`cursor()`方法创建一个游标对象`cursor`。
**使用游标对象执行SQL语句:**
创建游标对象后,可以使用游标的`execute()`方法来执行SQL语句。例如,执行一个查询操作:
```python
cursor.execute("SELECT * FROM table_name")
```
如果执行的是SELECT查询,可以通过游标对象的`fetchone()`或`fetchall()`方法来获取查询结果。`fetchone()`方法用于获取查询结果的一行数据,返回一个元组;`fetchall()`方法用于获取查询结果的所有行数据,返回一个列表,列表中包含多个元组。
对于INSERT、UPDATE或DELETE等非查询操作,`execute()`方法同样适用。执行完毕后,为了确保更改被永久保存到数据库中,需要调用连接对象的`commit()`方法:
```***
***mit()
```
在对数据库进行更新操作后,如果不调用`commit()`方法,那么这些更改将不会被提交到数据库中,最终将丢失。
**关闭游标和数据库连接:**
完成所有数据库操作后,应该关闭游标对象和数据库连接。关闭游标对象使用`close()`方法:
```python
cursor.close()
```
关闭数据库连接使用连接对象的`close()`方法:
```python
db.close()
```
为了确保在发生异常时资源能够被正确释放,通常会把关闭资源的操作放在`finally`块中执行:
```python
try:
# 执行数据库操作
pass
finally:
cursor.close()
db.close()
```
### 2.2.2 SQL语句的执行和结果的处理
在Python中,使用MySQLdb模块执行SQL语句并处理结果的过程可以分解为几个步骤:准备SQL语句、执行SQL语句、处理查询结果以及提交事务。以下是具体的实现细节。
#### 准备SQL语句
在Python脚本中,SQL语句可以像普通字符串一样编写。为了安全和效率,建议使用参数化查询(也称为预编译语句)。这样可以防止SQL注入攻击,并可能提高性能。下面是一个使用参数化查询的例子:
```python
# 使用参数化查询防止SQL注入
query = "INSERT INTO table_name (column1, column2) VALUES (%s, %s)"
cursor.execute(query, ('value1', 'value2'))
```
在这个例子中,`%s`是参数占位符,`cursor.execute()`方法的第二个参数是一个元组,包含了要插入的数据。
#### 执行SQL语句
对于SELECT类型的查询,`execute()`方法执行SQL语句后,可以通过`fetchone()`或`fetchall()`方法来获取查询结果:
```python
# 执行查询
cursor.execute("SELECT * FROM table_name")
# 获取查询结果
row = cursor.fetchone()
rows = cursor.fetchall()
```
`fetchone()`返回一个元组,代表查询结果的一行数据。如果查询结果为空,则返回`None`。`fetchall()`返回一个列表,列表中的每个元素都是一个元组,代表查询结果中的一行数据。
对于INSERT、UPDATE、DELETE等非查询类型的SQL语句,执行后通常需要调用`***mit()`方法来提交更改到数据库中。
#### 处理查询结果
处理查询结果时,可以通过索引或者列名来访问行数据:
```python
# 通过索引访问
name, age = row[0], row[1]
# 通过列名访问
name, age = row['name'], row['age']
```
当需要获取大量数据时,建议使用`fetchall()`方法配合for循环处理:
```python
for row in cursor.fetchall():
name, age = row['name'], row['age']
# 处理每行数据
```
#### 提交事务
MySQLdb操作数据库默认是在自动提交模式下,也就是说每次执行一个SQL语句,都会立即提交到数据库。如果你在同一个事务中需要执行多个SQL语句,可以通过设置连接对象的`autocommit`属性为`False`,然后在必要时手动调用`commit()`方法提交事务:
```python
# 关闭自动提交
db.autocommit(False)
# 执行一系列操作...
# 提交事务
***mit()
```
关闭自动提交后,直到调用`commit()`之前,所有的更改都将保持在本地缓存中。如果在此期间发生异常,可以通过调用`rollback()`方法回滚到事务开始的状态:
```python
try:
# 执行一系列操作...
***mit()
except:
db.rollback()
```
在实际应用中,正确地处理事务是非常重要的,它有助于保证数据的一致性和完整性。
# 3. Flask框架的入门与应用
#### 3.1 Flask框架的基本概念
Flask是一个轻量级的Web应用框架,是用Python编写的。它被设计来帮助开发者快速搭建项目,而且易于扩展和自定义。本节将深入探讨Flask框架的核心概念,包括路由、视图函数、模板渲染以及静态文件管理。
##### 3.1.1 路由与视图函数
路由是Web应用的基础,它将URL映射到特定的视图函数上。在Flask中,你可以使用`@app.route`装饰器来定义路由规则。以下是一个简单的例子:
```python
from flask import Flask
app = Flask(__name__)
@app.route('/')
def index():
return 'Hello, Flask!'
```
上述代码定义了一个视图函数`index`,它在访问根URL(`/`)时被调用。Flask的路由支持动态路径,可以通过变量规则来实现更加灵活的URL:
```python
@app.route('/user/<username>')
def show_user_profile(username):
return f'User {username}'
```
在这个例子中,`<username>`是一个动态部分,它会匹配任何在`/user/`之后的字符串,并将其作为参数传递给视图函数。
在处理路由时,Flask允许你定义方法类型,即HTTP请求的类型,如GET、POST、PUT等。这可以通过`methods`参数来完成:
```python
@app.route('/login', methods=['GET', 'POST'])
def login():
if request.method == 'POST':
# 处理登录逻辑
pass
else:
# 显示登录表单
pass
```
##### 3.1.2 模板渲染和静态文件管理
Flask使用Jinja2作为模板引擎,这意味着你可以创建动态HTML页面,通过模板标签插入变量或控制结构。以下是一个简单的模板渲染示例:
```python
from flask import Flask, render_template
@app.route('/hello/')
def hello_world():
name = 'World'
return render_template('hello.html', name=name)
```
在`hello.html`模板中,你可以这样使用Jinja2模板语言:
```html
<!DOCTYPE html>
<html>
<head>
<title>Hello</title>
</head>
<body>
<h1>Hello {{ name }}!</h1>
</body>
</html>
```
关于静态文件,如CSS、JavaScript和图片,Flask默认将`static`文件夹视为静态文件目录。你可以这样引用它们:
```html
<link rel="stylesheet" href="{{ url_for('static', filename='style.css') }}">
```
#### 3.2 Flask的数据管理与表单处理
##### 3.2.1 请求、响应对象的使用
Flask的`request`对象包含客户端发送的所有HTTP请求的信息,而`response`对象则用于构造服务器返回给客户端的数据。处理请求时,你可以访问查询参数、表单数据、JSON数据等多种格式的数据:
```python
from flask import request
@app.route('/login', methods=['GET', 'POST'])
def login():
if request.method == 'POST':
username = request.form['username']
password = request.form['password']
# 验证用户名和密码
# ...
elif request.method == 'GET':
return render_template('login.html')
```
在上面的例子中,`request.form`用于获取POST请求中的表单数据。类似地,`request.args`和`request.json`分别用于获取查询参数和JSON格式的请求数据。
#### 3.2 Flask的安全性与扩展
##### 3.3.1 用户认证和授权机制
Flask提供了许多扩展来增强应用的安全性。一个常用的扩展是Flask-Login,它提供了用户会话管理。你需要在你的应用中初始化Flask-Login,并定义一个用户模型和登录管理函数。这会要求你处理用户登录状态、记住登录以及注销功能。
```python
from flask_login import LoginManager, UserMixin, login_user, logout_user, login_required, current_user
login_manager = LoginManager()
login_manager.init_app(app)
class User(UserMixin):
# 用户的属性和方法
pass
@login_manager.user_loader
def load_user(user_id):
# 从数据库加载用户实例
pass
@app.route('/login', methods=['GET', 'POST'])
def login():
# ...(前面的代码保持不变)
user = User.query.filter_by(username=username).first()
if user and user.password == password: # 密码应该加密存储
login_user(user, remember=remember_me)
return redirect(url_for('index'))
# ...
@app.route('/logout')
@login_required
def logout():
logout_user()
return redirect(url_for('index'))
```
在Flask中,用户认证通常与`login_required`装饰器结合使用,以保护需要身份验证的路由。
##### 3.3.2 Flask扩展的使用和自定义扩展开发
Flask生态中有许多现成的扩展,可以帮助你更容易地实现如数据库操作、表单处理、文件上传、缓存管理等功能。你可以通过查找PyPI(Python Package Index)来发现这些扩展。
如果现有的扩展不能满足你的需求,你可以开发自己的Flask扩展。自定义扩展开发要求你对Flask的插件系统有深入的理解,包括如何创建蓝本(blueprints),定义应用工厂等。
```python
from flask import Blueprint
my_extension = Blueprint('my_extension', __name__)
@my_extension.route('/some/path')
def some_function():
return 'This is some path in my extension!'
```
这个简单的例子创建了一个蓝本,可以被注册到主Flask应用中。开发自己的扩展需要遵循Flask的蓝本和应用工厂模式,以确保扩展的灵活性和可重用性。
### 第四章:一步到位集成MySQLdb与Flask
#### 4.1 开发环境的搭建与项目结构设计
##### 4.1.1 Python虚拟环境的建立
Python虚拟环境是隔离不同项目依赖的常用方法,Flask项目也不例外。可以使用`venv`模块来创建和管理Python虚拟环境:
```shell
mkdir myflaskapp
cd myflaskapp
python -m venv venv
```
启用虚拟环境(Windows下使用`venv\Scripts\activate`,Unix或MacOS下使用`source venv/bin/activate`)后,你可以安装Flask和其他依赖到虚拟环境中,而不会影响到系统级的Python环境。
##### 4.1.2 Flask与MySQLdb集成项目结构
一个典型的Flask与MySQLdb集成项目的目录结构可能如下所示:
```
myflaskapp/
|-- myflaskapp/
| |-- __init__.py
| |-- views.py
| |-- models.py
| |-- forms.py
| `-- static/
|-- venv/
`-- requirements.txt
```
在这个结构中,`myflaskapp`文件夹是包含所有Flask应用代码的主要模块。`__init__.py`文件用来初始化Flask应用。`views.py`包含了路由和视图函数,`models.py`包含了数据库模型,而`forms.py`可以用来定义表单类。`static`文件夹用于存放静态文件,如CSS、JavaScript和图片。
#### 4.2 数据库与Web应用的交互实现
##### 4.2.1 ORM对象关系映射的实践
使用Flask-SQLAlchemy,一个集成到Flask的SQLAlchemy ORM扩展,可以简化与MySQL数据库的交互。首先,你需要安装Flask-SQLAlchemy:
```shell
pip install Flask-SQLAlchemy
```
然后,在你的`__init__.py`中初始化它:
```python
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://username:password@localhost/db_name'
db = SQLAlchemy(app)
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(80), unique=True, nullable=False)
email = db.Column(db.String(120), unique=True, nullable=False)
def __repr__(self):
return f'<User {self.username}>'
```
在上述代码中,我们定义了一个简单的`User`模型,它映射到数据库中的一个用户表。使用ORM可以让我们用Python对象的方式与数据库进行交互,而无需编写大量SQL代码。
##### 4.2.2 RESTful API的设计与实现
设计RESTful API是现代Web应用开发的关键部分。Flask可以通过Flask-RESTful扩展来实现这一目标。首先安装Flask-RESTful:
```shell
pip install Flask-RESTful
```
然后在你的项目中创建RESTful资源:
```python
from flask_restful import Api, Resource
api = Api(app)
class UserResource(Resource):
def get(self, user_id):
user = User.query.get(user_id)
if user:
return user.as_dict()
else:
return {'message': 'User not found'}, 404
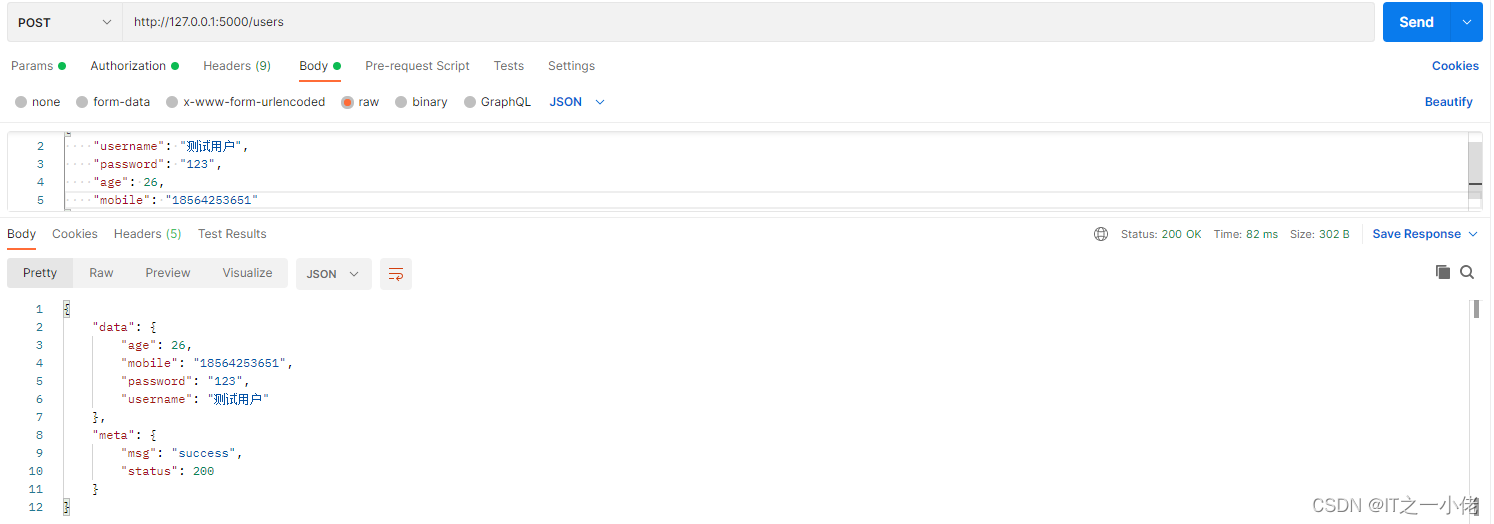
api.add_resource(UserResource, '/users/<int:user_id>')
```
以上代码定义了一个简单的RESTful API资源,它根据用户ID获取用户数据。对于API的其他方法(如POST、PUT、DELETE),你可以以类似的方式实现。
#### 4.3 部署与性能优化
##### 4.3.1 Flask应用的部署策略
部署Flask应用通常有多种选择,包括使用WSGI服务器如Gunicorn或uWSGI,或者直接运行Flask内置的服务器。对于生产环境,推荐使用WSGI服务器,因为它们比Flask内置服务器更加强大和可靠。
以Gunicorn为例,你可以使用以下命令来启动你的应用:
```shell
gunicorn -w 4 -b *.*.*.*:8000 myflaskapp:app
```
在上面的例子中,`-w 4`表示启动四个工作进程,`-b`参数用于绑定Gunicorn到指定的主机和端口。
##### 4.3.2 应用性能监控与调优
性能监控和调优是确保Web应用高性能的关键步骤。使用Flask-Profiler来监控性能是一个很好的起点。它可以记录请求的执行时间和SQL查询等信息。安装Flask-Profiler之后,在你的应用中启用它:
```python
from flask_profiler import Profiler
Profiler(app)
```
通过访问`/profiler` URL,你可以查看详细的性能报告。这些信息可以帮助你识别性能瓶颈,并进行相应优化。
对于数据库层面的优化,你可以使用事务处理、索引优化以及查询优化等技巧。确保你的查询是高效的,并且在可能的情况下使用缓存来减少对数据库的直接访问。此外,对于多用户并发访问的情况,合理使用MySQLdb的锁机制也是必要的。
至此,你已经学习了Flask框架的入门知识、安全机制以及如何将其与MySQLdb数据库集成。在下一章中,我们将探索如何一步到位集成MySQLdb与Flask,创建一个完整的Web应用。
# 4. 一步到位集成MySQLdb与Flask
## 4.1 开发环境的搭建与项目结构设计
### 4.1.1 Python虚拟环境的建立
在构建任何Python Web应用之前,搭建一个隔离的开发环境是非常关键的步骤。这可以通过使用`virtualenv`工具来实现。使用`virtualenv`可以创建一个具有独立Python解释器和库的虚拟环境,这样可以避免不同项目间依赖库版本的冲突。
首先,确保已经安装了Python。可以通过以下命令来安装`virtualenv`:
```bash
pip install virtualenv
```
安装完成后,创建一个新的虚拟环境,这里假设项目名为`myflaskapp`:
```bash
mkdir myflaskapp
cd myflaskapp
virtualenv venv
```
接下来,激活虚拟环境:
- 在Windows上:
```cmd
venv\Scripts\activate
```
- 在Unix或MacOS上:
```bash
source venv/bin/activate
```
激活虚拟环境后,你将看到虚拟环境的名称出现在命令行提示符前,表示现在所有安装的库都会被限制在这个虚拟环境中。
### 4.1.2 Flask与MySQLdb集成项目结构
一旦创建并激活了虚拟环境,下一步是设计项目结构。合理的项目结构对于代码的可维护性和扩展性至关重要。
下面是一个典型Flask项目的基本结构:
```
myflaskapp/
│
├── app/
│ ├── __init__.py
│ ├── models.py
│ ├── routes.py
│ └── static/
│ └── css/
│
├── migrations/
│ └── ...
│
├── venv/
│
├── requirements.txt
│
└── run.py
```
在这个结构中:
- `app/` 文件夹包含Flask应用的代码。
- `__init__.py` 文件使得该文件夹成为一个Python包,并初始化Flask应用。
- `models.py` 文件包含数据库模型定义。
- `routes.py` 文件包含路由和视图函数的定义。
- `static/` 文件夹用于存放静态文件,例如CSS、JavaScript和图片。
- `migrations/` 文件夹用于存放数据库迁移文件。
- `venv/` 是之前创建的虚拟环境文件夹。
- `requirements.txt` 文件用于记录项目的所有依赖。
- `run.py` 是启动Flask应用的脚本。
现在,开始初始化项目,首先在项目根目录下创建`requirements.txt`文件,并添加以下内容:
```
Flask==1.1.2
MySQL-Python==1.2.5
```
通过`pip install -r requirements.txt`安装项目所需依赖。之后,可以在`run.py`中创建一个Flask应用实例,并启动应用:
```python
from app import app
if __name__ == '__main__':
app.run(debug=True)
```
创建`app/__init__.py`并初始化Flask应用:
```python
from flask import Flask
app = Flask(__name__)
from app import routes
```
到此为止,开发环境搭建和项目结构设计已经完成,接下来可以开始数据库与Web应用的交互实现了。
## 4.2 数据库与Web应用的交互实现
### 4.2.1 ORM对象关系映射的实践
对象关系映射(Object Relational Mapping,ORM)技术是通过使用描述对象和数据库之间映射的元数据,将程序中的对象自动持久化到数据库中。Flask与MySQLdb集成时,可以使用SQLAlchemy这一ORM工具,它提供了将Python类映射到数据库表的功能,简化数据库操作。
首先,安装SQLAlchemy:
```bash
pip install SQLAlchemy
```
然后,将`app/models.py`文件修改为使用SQLAlchemy定义数据库模型:
```python
from app import db # 导入app包中预先初始化的db对象
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(80), unique=True, nullable=False)
email = db.Column(db.String(120), unique=True, nullable=False)
def __repr__(self):
return '<User %r>' % self.username
```
在`app/__init__.py`中引入模型,并初始化数据库:
```python
from flask_sqlalchemy import SQLAlchemy
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://username:password@localhost/dbname'
db = SQLAlchemy(app)
```
### 4.2.2 RESTful API的设计与实现
为了使Web应用能够通过HTTP协议与客户端进行通信,通常会实现一个RESTful API。RESTful API让Web服务可以被各种客户端使用,包括Web前端、移动应用以及第三方系统。
使用Flask-RESTful扩展可以方便地创建RESTful API。首先安装Flask-RESTful:
```bash
pip install Flask-RESTful
```
然后,在`app/routes.py`中创建资源类,实现RESTful API:
```python
from flask_restful import Resource, Api
from app import app, db
from app.models import User
api = Api(app)
class UserAPI(Resource):
def get(self, user_id):
user = User.query.get_or_404(user_id)
return {'username': user.username, 'email': user.email}
def post(self):
data = UserAPI.parser.parse_args()
new_user = User(username=data['username'], email=data['email'])
db.session.add(new_user)
***mit()
return new_user, 201
def delete(self, user_id):
user = User.query.get_or_404(user_id)
db.session.delete(user)
***mit()
return '', 204
UserAPI.parser.add_argument('username', type=str, required=True)
UserAPI.parser.add_argument('email', type=str, required=True)
api.add_resource(UserAPI, '/users/<int:user_id>', '/users')
```
通过这样的定义,我们为User实体创建了基本的CRUD(创建、读取、更新、删除)操作的API端点。
接下来,实现应用的部署与性能优化。
## 4.3 部署与性能优化
### 4.3.1 Flask应用的部署策略
部署Flask应用有多种方式,这里讨论如何使用流行的WSGI服务器Gunicorn来部署Flask应用,以及如何利用Nginx作为反向代理来提高应用的性能和安全性。
首先,安装Gunicorn:
```bash
pip install gunicorn
```
然后,使用以下命令来启动Flask应用:
```bash
gunicorn -w 4 -b ***.*.*.*:8000 run:app
```
这里`-w 4`指定了工作进程数为4,`-b`参数指定了绑定地址和端口。
为了在生产环境中部署Flask应用,建议使用Nginx作为反向代理服务器。Nginx不仅可以作为HTTP服务器处理静态内容的请求,还可以提高应用的安全性和性能。安装Nginx之后,配置文件(通常是`/etc/nginx/sites-available/default`)应包含以下内容:
```nginx
server {
listen 80;
server_***;
location / {
proxy_pass ***
*** $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
```
这个配置使得所有到达服务器的HTTP请求都代理到运行Gunicorn的本地地址和端口。确保在更改Nginx配置文件后,重启Nginx服务。
### 4.3.2 应用性能监控与调优
部署应用后,确保应用能够稳定运行并满足性能要求是关键。监控应用的性能并及时调优能够帮助避免潜在的性能瓶颈。可以使用多种工具和方法来监控和调优Flask应用的性能。
例如,可以使用Flask的扩展Flask-Profiling来帮助跟踪性能问题,通过添加以下代码来启用性能分析:
```python
from flask_profiling import Profiling
app.config['FLASK PROFILER'] = {
'enabled': True,
'storage': {
'engine': 'sqlalchemy'
},
'basicAuth': {
'enabled': True,
'username': 'admin',
'password': 'admin'
}
}
Profiling(app)
```
接着,可以通过访问`/profiler`路径来分析应用性能。
另一个重要的优化方面是应用缓存。Flask-Caching扩展可以用来为Flask应用提供缓存支持。安装Flask-Caching:
```bash
pip install Flask-Caching
```
然后在`app/__init__.py`中初始化缓存:
```python
from flask_caching import Cache
cache_config = {
'CACHE_TYPE': 'simple',
'CACHE_DEFAULT_TIMEOUT': 300
}
app.config.from_mapping(cache_config)
cache = Cache(app)
```
通过这种方式,可以对应用的特定部分进行缓存,减少数据库查询次数,提高响应速度。
综上所述,开发环境的搭建与项目结构设计、数据库与Web应用的交互实现,以及部署与性能优化都是集成MySQLdb与Flask过程中不可或缺的环节。每一个环节都至关重要,需要按照具体应用的需求和环境条件来进行细致的配置和优化。
# 5. 案例实践:构建完整的Python Web应用
## 5.1 应用需求分析与设计
### 5.1.1 功能需求概述
在着手构建一个完整的Python Web应用之前,对应用的功能需求进行详尽的分析是至关重要的。这一阶段,我们通常需要确定应用的目标用户群体、主要功能、以及这些功能应该如何组织。例如,如果我们要开发一个在线图书商店,可能包括以下功能需求:
- 用户注册和登录
- 浏览图书列表
- 搜索特定图书
- 查看图书详情
- 添加图书到购物车
- 结算和生成订单
- 查看历史订单记录
这些功能将构成我们项目的基础框架。
### 5.1.2 数据库模型和Web界面设计
需求分析之后,接下来是数据库模型和Web界面的设计。数据库模型需要设计能够高效存储和检索图书信息、用户信息和订单信息的表格。例如,我们可能需要设计以下几张表:
- 用户表(User)
- 图书表(Book)
- 订单表(Order)
- 订单详情表(OrderDetail)
设计Web界面时,我们需要思考用户如何与应用交互。界面设计应该简洁直观,便于用户操作。例如,图书列表页面应该允许用户通过不同条件筛选和排序图书,图书详情页面则需要展示详细的图书信息。
设计完成后,我们可以使用Flask框架中的Flask-Admin扩展快速搭建起后台管理系统,这有助于进行数据维护和初步测试。
## 5.2 应用开发与测试
### 5.2.1 功能模块开发
根据设计,我们将逐步开发每个功能模块。使用Flask框架创建路由来处理不同的HTTP请求,结合Jinja2模板引擎渲染页面,利用SQLAlchemy作为ORM工具操作MySQL数据库。
例如,对于“用户注册”功能,我们可以创建如下路由:
```python
from flask import Flask, request, render_template, redirect, url_for
from flask_sqlalchemy import SQLAlchemy
from werkzeug.security import generate_password_hash
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://username:password@localhost/db_name'
db = SQLAlchemy(app)
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(50), unique=True)
password_hash = db.Column(db.String(100))
@app.route('/register', methods=['GET', 'POST'])
def register():
if request.method == 'POST':
username = request.form['username']
password = request.form['password']
hashed_password = generate_password_hash(password)
new_user = User(username=username, password_hash=hashed_password)
db.session.add(new_user)
***mit()
return redirect(url_for('login'))
return render_template('register.html')
```
在开发过程中,合理利用Git进行版本控制,这样可以方便团队协作与代码的版本管理。
### 5.2.* 单元测试和集成测试
开发完成后,进行单元测试是必不可少的步骤。我们可以使用Python的`unittest`库对每个独立的功能模块进行测试。
例如,测试注册功能的单元测试可能如下:
```python
import unittest
from your_application import app, db, User
class RegisterTestCase(unittest.TestCase):
def setUp(self):
app.config['TESTING'] = True
self.client = app.test_client()
self.app_context = app.app_context()
self.app_context.push()
db.create_all()
def tearDown(self):
db.session.remove()
db.drop_all()
self.app_context.pop()
def test_user_registration(self):
response = self.client.post('/register', data=dict(
username='testuser',
password='test123'
), follow_redirects=True)
self.assertTrue(response.status_code, 200)
self.assertIn(b'Welcome testuser!', response.data)
if __name__ == '__main__':
unittest.main()
```
除了单元测试,集成测试也是确保应用各个组件协同工作正常的重要手段。
## 5.3 应用部署与维护
### 5.3.1 应用的上线部署
开发完成后,我们需要将应用部署到服务器上。有许多云服务平台支持Python应用,例如Heroku、AWS、阿里云等。这里以Gunicorn结合Nginx为例,展示一个简单的部署流程。
首先,安装Gunicorn:
```bash
pip install gunicorn
```
然后,使用Gunicorn运行Flask应用:
```bash
gunicorn -w 4 -b localhost:8000 your_application:app
```
接着,配置Nginx反向代理到Gunicorn:
```nginx
server {
listen 80;
server_***;
location / {
proxy_pass ***
*** $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
```
### 5.3.2 日志记录、监控与维护策略
为了确保应用的稳定性和高效性,合理的日志记录和监控策略是必不可少的。我们可以在Flask应用中集成Flask-Login来记录用户的活动,同时使用第三方服务如Sentry进行错误报告。
此外,定期更新依赖包和操作系统,监控服务器性能,以及设置自动备份机制,都是维护一个健康应用不可或缺的环节。这可以通过编写简单的脚本和设置定时任务来实现。
以上就是构建一个完整Python Web应用的案例实践。在这一过程中,我们不仅实践了理论知识,也学会了如何将理论应用到实际开发中。通过这样的项目实践,可以更深刻地理解Python Web开发的全貌。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 MySQLdb 库学习专栏,一个为 Python 开发者量身打造的数据库交互指南。本专栏涵盖了从入门到高级的广泛主题,包括库快速入门、深度应用、性能调优、最佳实践、源码解析、多线程处理、ORM 集成、自动化测试、并发控制、大数据处理、分布式数据库编程、扩展模块开发以及备份与恢复技巧。无论您是 Python 新手还是经验丰富的开发者,本专栏都将为您提供全面的知识和实践指南,帮助您充分利用 MySQLdb 库,提升数据库交互效率和性能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
揭秘ETA6884移动电源的超速充电:全面解析3A充电特性

# 摘要
本文详细探讨了ETA6884移动电源的技术规格、充电标准以及3A充电技术的理论与应用。通过对充电技术的深入分析,包括其发展历程、电气原理、协议兼容性、安全性理论以及充电实测等,我们提供了针对ETA6884移动电源性能和效率的评估。此外,文章展望了未来充电技术的发展趋势,探讨了智能充电、无线充电以
【编程语言选择秘籍】:项目需求匹配的6种语言选择技巧

# 摘要
本文全面探讨了编程语言选择的策略与考量因素,围绕项目需求分析、性能优化、易用性考量、跨平台开发能力以及未来技术趋势进行深入分析。通过对不同编程语言特性的比较,本文指出在进行编程语言选择时必须综合考虑项目的特定需求、目标平台、开发效率与维护成本。同时,文章强调了对新兴技术趋势的前瞻性考量,如人工智能、量子计算和区块链等,以及编程语言如何适应这些技术的变化。通
【信号与系统习题全攻略】:第三版详细答案解析,一文精通

# 摘要
本文系统地介绍了信号与系统的理论基础及其分析方法。从连续时间信号的基本分析到频域信号的傅里叶和拉普拉斯变换,再到离散时间信号与系统的特性,文章深入阐述了各种数学工具如卷积、
微波集成电路入门至精通:掌握设计、散热与EMI策略

# 摘要
本文系统性地介绍了微波集成电路的基本概念、设计基础、散热技术、电磁干扰(EMI)管理以及设计进阶主题和测试验证过程。首先,概述了微波集成电路的简介和设计基础,包括传输线理论、谐振器与耦合结构,以及高频电路仿真工具的应用。其次,深入探讨了散热技术,从热导性基础到散热设计实践,并分析了散热对电路性能的影响及热管理的集成策略。接着,文章聚焦于EMI管理,涵盖了EMI基础知识、
Shell_exec使用详解:PHP脚本中Linux命令行的实战魔法

# 摘要
本文详细探讨了PHP中的Shell_exec函数的各个方面,包括其基本使用方法、在文件操作与网络通信中的应用、性能优化以及高级应用案例。通过对Shell_exec函数的语法结构和安全性的讨论,本文阐述了如何正确使用Shell_exec函数进行标准输出和错误输出的捕获。文章进一步分析了Shell_exec在文件操作中的读写、属性获取与修改,以及网络通信中的Web服
NetIQ Chariot 5.4高级配置秘籍:专家教你提升网络测试效率

# 摘要
NetIQ Chariot是网络性能测试领域的重要工具,具有强大的配置选项和高级参数设置能力。本文首先对NetIQ Chariot的基础配置进行了概述,然后深入探讨其高级参数设置,包括参数定制化、脚本编写、性能测试优化等关键环节。文章第三章分析了Net
【信号完整性挑战】:Cadence SigXplorer仿真技术的实践与思考
# 摘要
本文全面探讨了信号完整性(SI)的基础知识、挑战以及Cadence SigXplorer仿真技术的应用与实践。首先介绍了信号完整性的重要性及其常见问题类型,随后对Cadence SigXplorer仿真工具的特点及其在SI分析中的角色进行了详细阐述。接着,文章进入实操环节,涵盖了仿真环境搭建、模型导入、仿真参数设置以及故障诊断等关键步骤,并通过案例研究展示了故障诊断流程和解决方案。在高级
【Python面向对象编程深度解读】:深入探讨Python中的类和对象,成为高级程序员!

# 摘要
本文深入探讨了面向对象编程(OOP)的核心概念、高级特性及设计模式在Python中的实现和应用。第一章回顾了面向对象编程的基础知识,第二章详细介绍了Python类和对象的高级特性,包括类的定义、继承、多态、静态方法、类方法以及魔术方法。第三章深入讨论了设计模式的理论与实践,包括创建型、结构型和行为型模式,以及它们在Python中的具体实现。第四
Easylast3D_3.0架构设计全解:从理论到实践的转化
# 摘要
Easylast3D_3.0是一个先进的三维设计软件,其架构概述及其核心组件和理论基础在本文中得到了详细阐述。文中详细介绍了架构组件的解析、设计理念与原则以及性能评估,强调了其模块间高效交互和优化策略的重要性。
【提升器件性能的秘诀】:Sentaurus高级应用实战指南

# 摘要
Sentaurus是一个强大的仿真工具,广泛应用于半导体器件和材料的设计与分析中。本文首先概述了Sentaurus的工具基础和仿真环境配置,随后深入探讨了其仿真流程、结果分析以及高级仿真技
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )