LSTM超参数调整黄金法则:提升模型性能的实战经验
发布时间: 2024-11-20 19:48:07 阅读量: 160 订阅数: 49 

pso-gru-lstm:PSO优化GRU-LSTM超参数

# 1. LSTM基础与超参数的重要性
在人工智能领域,长短期记忆网络(LSTM)是一种特别设计的循环神经网络(RNN)架构,它能学习长期依赖信息。LSTM已经成为处理序列数据的关键技术,尤其在自然语言处理、语音识别和时间序列预测等领域中有着广泛应用。不同于传统的RNN,LSTM引入了门控机制,有效解决了长序列训练时的梯度消失问题。
深度学习模型的性能很大程度上依赖于超参数的设定,这些超参数包括但不限于学习率、隐藏层神经元数量、批量大小等。这些参数影响着模型的收敛速度、泛化能力和最终性能。在这一章中,我们将从LSTM的基础架构开始,深入理解超参数的重要性,并探讨如何通过优化超参数来提高模型的表现。接下来的章节将具体介绍每个超参数的作用,并分享实战技巧和实践指南。
# 2. ```
# 第二章:理解LSTM超参数的作用
## 2.1 LSTM网络的基本结构
### 2.1.1 LSTM单元的工作原理
长短期记忆网络(LSTM)是循环神经网络(RNN)的一种变体,其特殊之处在于它能够学习长期依赖信息。LSTM的核心是其包含的三种门:输入门、遗忘门和输出门。这些门的设计使得LSTM能够控制信息在单元状态中的流动。输入门决定了哪些新信息会被添加到单元状态中,遗忘门决定哪些旧信息会被丢弃,而输出门则控制着下一个隐藏状态的输出。这种结构有效避免了传统RNN的梯度消失问题,使得LSTM在处理长期依赖问题上表现出色。
### 2.1.2 输入门、遗忘门、输出门详解
- **输入门(Input Gate)**: 负责决定新输入的信息中有多少是应该被存储的。它通常由一个sigmoid神经网络层实现,输出结果在0到1之间,0表示完全不考虑输入信息,1表示完全考虑。
- **遗忘门(Forget Gate)**: 负责决定上一时刻的单元状态中有多少信息需要被遗忘。这同样由一个sigmoid神经网络层实现,为每一条信息提供一个遗忘分数,分数越高表示保留的可能性越大。
- **输出门(Output Gate)**: 负责决定在计算完当前状态后,下一个隐藏状态的输出。通常会先对当前状态进行一个tanh处理,将状态值规范化到-1到1之间,然后通过输出门的sigmoid层来确定哪些信息需要输出。
LSTM单元的这些门机制,允许网络在序列中传递信息时有所选择,有效地捕捉长期依赖性。
## 2.2 关键超参数的作用与选择
### 2.2.1 学习率的调整策略
学习率是神经网络训练过程中最重要的超参数之一。它决定了在梯度下降过程中参数更新的幅度。如果学习率设置得太高,模型可能会无法收敛;相反,如果设置得太低,训练过程可能会非常缓慢甚至陷入局部最小值。
- **学习率调整策略**:
- **固定学习率**: 在训练初期快速学习,但可能在接近最优解时震荡。
- **衰减学习率**: 初始阶段使用较高学习率,随着训练进度逐渐减小。
- **周期性学习率调整**: 根据训练周期调整学习率,可在不同阶段探索更优的权重更新。
实际选择时,通常会使用一些启发式规则和经验性调整,或者借助先进的学习率调度策略如学习率衰减的优化器(如Adam优化器自带的学习率衰减)。
### 2.2.2 隐藏层神经元的数量
在构建LSTM网络时,我们需要决定隐藏层神经元的数目。这个超参数直接影响模型的学习能力和泛化性能。
- **选择隐藏层神经元数量的原则**:
- **太少**: 模型可能无法学习到数据中的复杂特征。
- **太多**: 模型可能会过拟合,且训练成本显著增加。
一种简单的方法是基于输入和输出的大小来选择隐藏层神经元数量。更通用的方法是使用如交叉验证等技术来确定最佳数目。
### 2.2.3 批量大小对模型性能的影响
批量大小(Batch Size)是指在训练过程中每次传递给模型的数据样本数量。批量大小对模型的训练速度、稳定性以及泛化能力都有显著影响。
- **批量大小的影响**:
- **小批量**: 能提供较为稳定的梯度估计,但需要更多的迭代次数,训练过程可能较慢。
- **大批量**: 可以更有效地使用硬件加速,但可能导致训练过程中的梯度估计不够稳定,增加过拟合的风险。
根据具体问题和硬件资源,可以通过尝试不同批量大小并监控验证集上的性能来确定最佳选择。
```mermaid
graph LR
A[开始训练] --> B[选择初始批量大小]
B --> C[监控性能]
C -->|性能提升| D[尝试更大批量大小]
C -->|性能下降| E[尝试更小批量大小]
D --> C
E --> C
```
在实际操作中,可以设置一个初始批量大小,然后根据模型在验证集上的性能反馈逐渐调整。
```python
# 示例代码:如何使用PyTorch调整批量大小
import torch
from torch.utils.data import DataLoader
# 假设我们有一个数据集和模型
train_dataset = ... # 数据集
model = ... # LSTM模型
# 初始批量大小设定
batch_size = 32
# 创建DataLoader实例
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# 训练循环
for epoch in range(num_epochs):
for data in train_loader:
# 前向传播、计算损失、反向传播和优化
...
```
在上述代码中,批量大小的设定是通过`DataLoader`的`batch_size`参数实现的。通过实验和验证集的反馈,我们可以找到适合当前模型和数据集的批量大小。
通过本章节的介绍,我们已经对LSTM超参数有了初步的理解,下一章节我们将深入探讨实战中的超参数调整技巧。
```
# 3. 实战中的超参数调整技巧
## 3.1 遗忘门超参数的优化
### 3.1.1 遗忘门的作用与调整方法
遗忘门是LSTM网络中用于控制信息保留的关键组件。它通过一个Sigmoid层决定哪些信息需要被保留,哪些信息应该从单元状态中被遗忘。这种机制允许网络长时间记住或忽略过去的信息,这对于处理序列数据至关重要。
调整遗忘门超参数通常涉及以下几个方面:
- **权重初始化**: 对于遗忘门的权重矩阵进行合理初始化,确保其在训练初期不会过度遗忘或记住信息。
- **正则化**: 使用L2或Dropout正则化技术减少过拟合,保持遗忘门的稳定性。
- **学习率**: 遗忘门的更新速度对模型的收敛性和最终性能有直接影响。通常通过调整学习率来控制这一速度。
### 3.1.2 实际案例分析
假设我们正在处理一个时间序列预测问题,我们需要通过调整遗忘门的超参数来提高模型的预测准确性。以下是调整遗忘门超参数的步骤和实例:
1. **初始化遗忘门权重**: 假设我们的输入特征是5维,隐藏层单元是100个。首先,我们初始化遗忘门的权重矩阵为一个5x100的矩阵,使用例如He初始化策略。
2. **正则化策略**: 在遗忘门中引入Dropout,我们设置Dropout比例为0.5,这样每个训练批次中,有50%的机会随机“关闭”一些遗忘门的权重,以减少过拟合。
3. **调整学习率**: 使用梯度下降优化器时,学习率通常需要精细调整。初始学习率设定为0.01,然后根据模型在验证集上的表现进行调整。
```python
from keras.layers import LSTM, Dropout
from keras.models import Sequential
from keras.regularizers import l2
from keras.optimizers import Adam
model = Sequential()
model.add(LSTM(100, input_shape=(5, 100), return_sequences=True,
kernel_regularizer=l2(0.01), recurrent_dropout=0.5))
model.compile(loss='mean_squared_error', optimizer=Adam(lr=0.01))
```
在代码示例中,我们设置LSTM层的`recurrent_dropout`为0.5,这意味着在训练过程中,有50%的几率会随机丢弃时间步长中的连接,以防止过拟合。同时,通过`l2(0.01)`设置L2正则化参数。
## 3.2 学习率衰减的策略
### 3.2.1 学习率衰减的方法
在神经网络训练中,学习率是一个关键的超参数。学习率过高可能导致模型在最小值附近震荡,而学习率过低则会导致训练进度缓慢。因此,学习率衰减策略成为了一个常用的技巧,它在训练开始时使用较大的学习率,随着训练的进行逐渐减小学习率,以帮助模型更好地收敛。
学习率衰减的常见方法包括:
- **按周期衰减**: 每隔几个周期,将学习率乘以一个衰减因子(如0.1)。
- **按步数衰减**: 每完成一定数量的更新后,学习率按固定步长衰减。
- **基于性能的衰减**: 当验证集上的性能不再提升时,减小学习率。
### 3.2.2 如何选择合适的衰减率
选择一个合适的衰减率通常需要通过实验来确定。下面是一些选择衰减率时可以考虑的因素:
- **训练的稳定性**: 如果模型在训练过程中波动很大,可能需要更快的学习率衰减。
- **数据集的大小**: 较大的数据集可能需要更慢的衰减。
- **模型的复杂性**: 对于复杂模型,开始使用较高的学习率,然后缓慢衰减可能是较好的策略。
以Keras框架为例,下面的代码演示了如何设置学习率的按周期衰减策略:
```python
from keras.callbacks import LearningRateScheduler
def scheduler(epoch, lr):
if e
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
长短期记忆网络(LSTM)专栏深入探索了 LSTM 的原理、与 RNN 的对比、实战模型构建、NLP 中的应用、性能优化、正则化、网络结构、股票预测、多层网络、并行计算、图像识别、企业级解决方案、超参数调整、模型压缩和语音识别中的应用。通过一系列文章,专栏提供了全面的 LSTM 知识,从基础概念到高级应用,帮助读者掌握时间序列数据处理的艺术,并利用 LSTM 的强大功能解决各种机器学习问题。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【大华门禁系统搭建教程】:安全网络从零开始的秘诀

# 摘要
门禁系统是现代安全管理中不可或缺的组成部分,本文从基础介绍入手,全面阐述了门禁系统的关键技术和应用。首先介绍了门禁系统的基本组成,详细探讨了硬件的各个模块以及硬件选型的重要性。随后,文章深入门禁系统的软件设计和开发环节,涵盖了软件架构、功能模块设计,以及开发过程中的环境搭建、
【FPGA中的Aurora集成艺术】:测试与优化的最佳实践分享
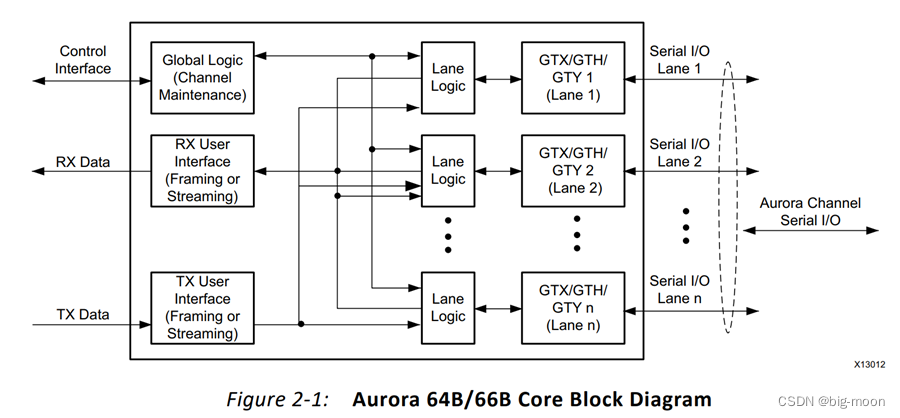
# 摘要
本文全面介绍了FPGA(现场可编程门阵列)和Aurora协议的基础知识、实施步骤、测试方法、性能优化策略以及未来展望。Aurora协议作为一种高速串行通信协议,其在FPGA上的实现对于高性能计算和数据传输具有重要意义。文章首先概述了Aurora协议的技术原理、关键特性和优势,并详细描述了在FPGA平台上实现Aurora的步骤,包括硬件配置、软件集成及系统时钟管理。接着,本文深入探讨了Aurora
【微服务与电商】:揭秘Spring Boot在电商领域的高效实践
# 摘要
微服务架构已成为现代电商系统设计的关键技术,本文首先概述了微服务架构与电商系统的关系,接着深入探讨了Spring Boot框架的基础知识、组件管理和应用构建。随后,针对电商系统开发实践,文章详细介绍了商品管理、订单处理和用户支付模块的开发与集成。文章还探讨了如何通过优化数据库连接、实施安全策略和性能监控来提升Spr
浏览器缓存性能影响剖析:揭秘加速秘诀与优化技巧

# 摘要
浏览器缓存作为提升Web访问速度和效率的重要技术,其性能直接影响用户浏览体验和网站性能。本文详细概述了浏览器缓存的机制,探讨了缓存类型、作用以及控制策略,并分析了缓存一致性模型。接着,文章深入分析了缓存性能的多种影响因素,如缓存容量、存储介质、网络环境、服务器配置以及浏览器策略和用户行为的交互作用。进一步,提出了缓存性能的优化实
深入理解逐步回归:Matlab如何革新你的数据分析流程

# 摘要
逐步回归法是一种常用的统计分析方法,用于确定一组变量中哪些对预测响应变量最为重要。本文首先介绍了逐步回归法的理论基础,随后重点阐述了
【掌握cdk_cloudfront_plus-0.3.116权限管理】:保障企业CDN的安全与稳定

# 摘要
本文深入探讨了cdk_cloudfront_plus-0.3.116在权限管理方面的概念、基础理论、实践应用、高级应用,以及未来展望。首先概述了权限管理的重要性及其对CDN安全性的贡献,其次详细介绍了权限管理的基本概念和理论框架,包括认证与授权的区别、常见
【ibapDAV6中文版:性能优化秘籍】

# 摘要
ibapDAV6中文版作为一款技术产品,其性能分析和调优对于确保软件应用的高效运行至关重要。本文第一章概述了ibapDAV6中文版的性能概况,随后在第二章深入探讨性能测试理论,包括性能测试的基础、方法论和实战案例。第三章聚焦于性能调优技术,涵盖服务器配置、代码级优化和数据库性能管理。第四章提出了性能管理实践,包括监控预警系统、持续性能优化流程及案例分析。第五章则着重于分布式性能调优
Swan海浪模式快速入门:从零开始构建微服务架构
# 摘要
本文介绍了微服务架构与Swan海浪模式的基础知识及其在实践中的应用。首先概述了微服务架构的核心原则和设计模式,然后详细阐述了Swan海浪模式的组件功能、基础环境构建及监控维护。接着,文章深入探讨了在Swan海浪模式下微服务的注册与发现、负载均衡与容错以及安全策略的实现。最后,通过对分布式跟踪系统和微服务自动化治理的高级应用的分析,结合实际案例,总结了Swan海浪模式的经验和教训。本文旨在为读者提供
RTL8370N芯片固件升级最佳实践:安全与效能兼顾

# 摘要
本文详细探讨了RTL8370N芯片的固件升级过程及其重要性,涵盖了从理论基础到实践应用的各个方面。固件升级不仅能显著提升芯片性能,还能通过安全加固确保系统的稳定运行。文章首先介绍了固件升级的概念、作用及其对芯片性能的影响,随后阐述了升级的流程、步骤以及安全性考量。在实践篇中,重点讨论了升级环境的搭建、自动化脚本编写以及异常处理策略。性能优化与安全加固章节进一
Hyper-V安全秘籍:如何安全地禁用 Credential Guard与Device Guard
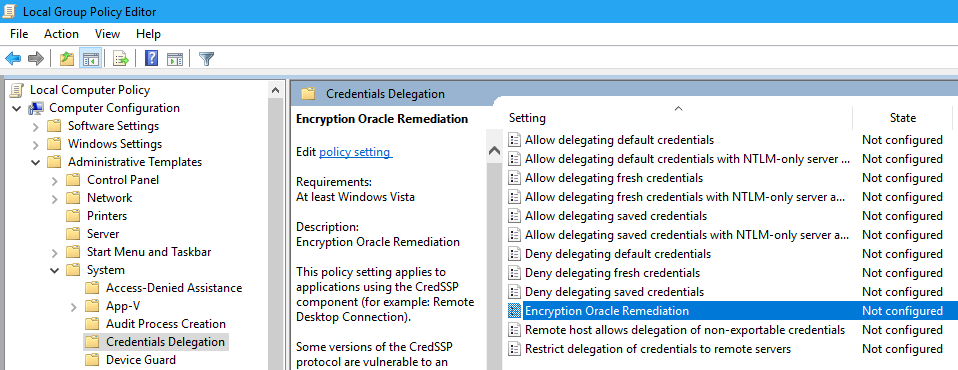
# 摘要
本文对Hyper-V虚拟化平台中的安全机制进行了综述,深入探讨了 Credential Guard 和 Device Guard 的工作原理与实施策略,并分析了在特定条件下禁用这些安全特性可能带来的必要性及风险。文章详细阐述了禁用 Credential Guard 和 Devi
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )