elasticsearch增删改查【删除数据】删除条件数据
发布时间: 2024-03-19 21:22:42 阅读量: 47 订阅数: 36 
# 1. 理解Elasticsearch
Elasticsearch是一个开源的分布式搜索和分析引擎,是基于Lucene库构建的。它提供了一个分布式多用户能力的全文搜索引擎,通过RESTful Web接口实现。Elasticsearch是一个实时的分布式搜索分析引擎,每一条数据都是实时索引的。它的特点包括高可靠性、高性能、水平扩展、多数据源、多种查询方式等。
#### 1.1 什么是Elasticsearch
Elasticsearch是一个开源搜索引擎,建立在一个全文搜索引擎库Apache Lucene基础之上。它提供了一个分布式多用户能力的实时搜索和分析功能,支持多种方式的搜索请求。
#### 1.2 Elasticsearch的特点和优势
- 高可靠性:数据自动分片、冗余存储,保证数据不丢失。
- 高性能:基于倒排索引,快速检索数据。
- 水平扩展:支持水平扩展,轻松扩展集群规模。
- 多数据源:支持结构化和非结构化数据索引。
- 多种查询方式:支持全文搜索、精确查询、分析查询等。
#### 1.3 Elasticsearch的基本概念
- Document(文档):数据的最小单位,以JSON格式表示。
- Index(索引):一组相关文档的集合,类似于关系数据库中的数据库。
- Type(类型):索引中的逻辑分类,可以用来过滤文档。
- Shard(分片):将大的索引划分成小的部分,分布到不同节点上。
- Replica(副本):每个分片的复制品,提高数据的可靠性和查询性能。
在接下来的章节中,我们将深入探讨Elasticsearch的数据操作基础、删除数据操作详解、删除条件数据技巧等内容。
# 2. Elasticsearch数据操作基础
- **2.1 数据的增加(Index)操作**
- 代码示例(Python):
```python
from elasticsearch import Elasticsearch
es = Elasticsearch()
doc = {
"name": "John Doe",
"age": 25,
"email": "johndoe@example.com"
}
res = es.index(index='my_index', id=1, body=doc)
```
- 注释:以上代码是向名为'my_index'的索引中插入文档的示例。
- 代码总结:使用`es.index()`方法向Elasticsearch中索引添加文档。
- 结果说明:成功向索引中添加了id为1的文档。
- **2.2 数据的删除(Delete)操作**
- 代码示例(Java):
```java
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.client.*;
RestClient restClient = RestClient.builder(
new HttpHost("localhost", 9200, "http")).build();
DeleteRequest request = new DeleteRequest("my_index", "1");
DeleteResponse deleteResponse = restClient.delete(request);
```
- 注释:以上代码演示了通过REST客户端使用Java删除Elasticsearch中的文档。
- 代码总结:通过构建`DeleteRequest`对象并调用`restClient.delete(request)`方法来删除文档。
- 结果说明:成功删除了id为1的文档。
- **2.3 数据的更新(Update)操作**
- 代码示例(Go):
```go
package main
import (
"context"
"github.com/olivere/elastic/v7"
)
func main() {
client, err := elastic.NewClient(elastic.SetURL("http://localhost:9200"))
if err != nil {
// 处理错误
panic(err)
}
updateDoc := map[string]interface{}{"age": 26}
_, err = client.Update().Index("my_index").Id("1").Doc(updateDoc).Do(context.Background())
if err != nil {
// 处理更新错误
panic(err)
}
}
```
- 注释:以上代码展示了使用Go语言更新Elasticsearch中文档的操作。
- 代码总结:利用`client.Update()`方法传入更新

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以"elasticsearch增删改查"为主题,深入探讨了与Elasticsearch相关的基础概念、插入数据、删除数据、修改数据以及查询数据等多个方面。文章包括了RESTful API的介绍、索引和文档的基础概念、Mapping和Settings配置的详解,以及使用PUT方法插入数据、bulk批量操作、不同方式删除数据、PUT覆盖式修改和简单查询等内容。此外,还探讨了Kibana图形化展示的方法、存储结构与性能优化的重要性,以及shard分布要求的意义。专栏还介绍了实践工具与资源,包括Kibana图形化界面等。通过本专栏,读者可以全面了解Elasticsearch的增删改查操作以及相关实践工具的使用,为实际项目应用提供重要参考。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
机器学习性能评估:时间复杂度在模型训练与预测中的重要性
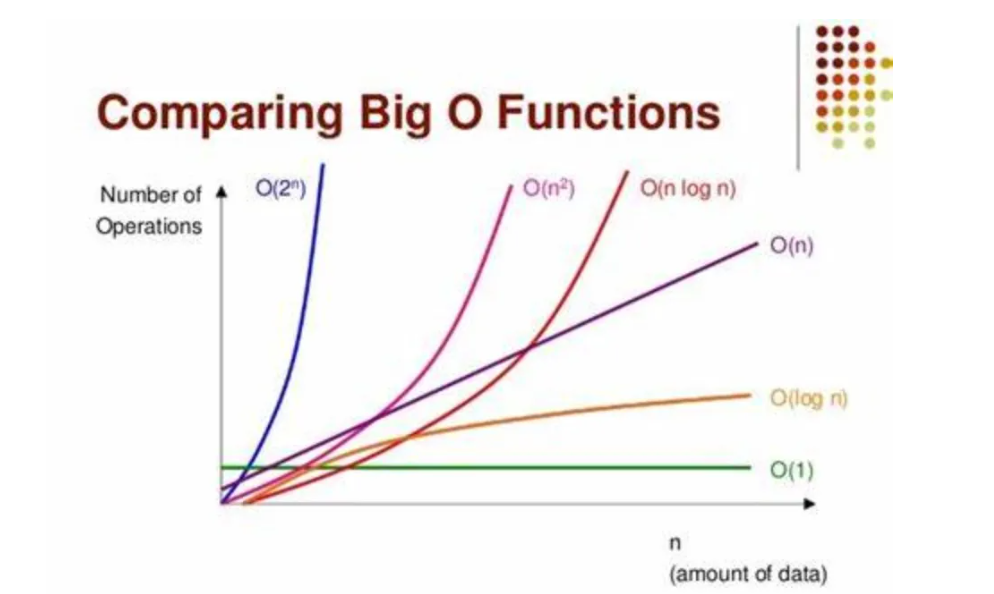
# 1. 机器学习性能评估概述
## 1.1 机器学习的性能评估重要性
机器学习的性能评估是验证模型效果的关键步骤。它不仅帮助我们了解模型在未知数据上的表现,而且对于模型的优化和改进也至关重要。准确的评估可以确保模型的泛化能力,避免过拟合或欠拟合的问题。
## 1.2 性能评估指标的选择
选择正确的性能评估指标对于不同类型的机器学习任务至关重要。例如,在分类任务中常用的指标有
贝叶斯优化:智能搜索技术让超参数调优不再是难题
# 1. 贝叶斯优化简介
贝叶斯优化是一种用于黑盒函数优化的高效方法,近年来在机器学习领域得到广泛应用。不同于传统的网格搜索或随机搜索,贝叶斯优化采用概率模型来预测最优超参数,然后选择最有可能改进模型性能的参数进行测试。这种方法特别适用于优化那些计算成本高、评估函数复杂或不透明的情况。在机器学习中,贝叶斯优化能够有效地辅助模型调优,加快算法收敛速度,提升最终性能。
接下来,我们将深入探讨贝叶斯优化的理论基础,包括它的工作原理以及如何在实际应用中进行操作。我们将首先介绍超参数调优的相关概念,并探讨传统方法的局限性。然后,我们将深入分析贝叶斯优化的数学原理,以及如何在实践中应用这些原理。通过对
时间序列分析的置信度应用:预测未来的秘密武器
# 1. 时间序列分析的理论基础
在数据科学和统计学中,时间序列分析是研究按照时间顺序排列的数据点集合的过程。通过对时间序列数据的分析,我们可以提取出有价值的信息,揭示数据随时间变化的规律,从而为预测未来趋势和做出决策提供依据。
## 时间序列的定义
时间序列(Time Series)是一个按照时间顺序排列的观测值序列。这些观测值通常是一个变量在连续时间点的测量结果,可以是每秒的温度记录,每日的股票价
探索与利用平衡:强化学习在超参数优化中的应用
# 1. 强化学习与超参数优化的交叉领域
## 引言
随着人工智能的快速发展,强化学习作为机器学习的一个重要分支,在处理决策过程中的复杂问题上显示出了巨大的潜力。与此同时,超参数优化在提高机器学习模型性能方面扮演着关键角色。将强化学习应用于超参数优化,不仅可实现自动化,还能够通过智能策略提升优化效率,对当前AI领域的发展产生了深远影响。
## 强化学习与超参数优化的关系
强化学习能够通过与环境的交互来学
【目标变量优化】:机器学习中因变量调整的高级技巧
# 1. 目标变量优化概述
在数据科学和机器学习领域,目标变量优化是提升模型预测性能的核心步骤之一。目标变量,又称作因变量,是预测模型中希望预测或解释的变量。通过优化目标变量,可以显著提高模型的精确度和泛化能力,进而对业务决策产生重大影响。
## 目标变量的重要性
目标变量的选择与优化直接关系到模型性能的好坏。正确的目标变量可以帮助模
【Python预测模型构建全记录】:最佳实践与技巧详解
# 1. Python预测模型基础
Python作为一门多功能的编程语言,在数据科学和机器学习领域表现得尤为出色。预测模型是机器学习的核心应用之一,它通过分析历史数据来预测未来的趋势或事件。本章将简要介绍预测模型的概念,并强调Python在这一领域中的作用。
## 1.1 预测模型概念
预测模型是一种统计模型,它利用历史数据来预测未来事件的可能性。这些模型在金融、市场营销、医疗保健和其
模型参数泛化能力:交叉验证与测试集分析实战指南

# 1. 交叉验证与测试集的基础概念
在机器学习和统计学中,交叉验证(Cross-Validation)和测试集(Test Set)是衡量模型性能和泛化能力的关键技术。本章将探讨这两个概念的基本定义及其在数据分析中的重要性。
## 1.1 交叉验证与测试集的定义
交叉验证是一种统计方法,通过将原始数据集划分成若干小的子集,然后将模型在这些子集上进行训练和验证,以
【算法复杂度入门】:5步法掌握大O表示法的奥秘
# 1. 算法复杂度简介与重要性
## 1.1 什么是算法复杂度
算法复杂度是衡量算法性能的标准,它量化了算法所需的计算资源(如时间、空间等)。在编程和系统设计中,理解算法复杂度对优化性能至关重要,尤其是在处理大量数据时。
## 1.2 算法复杂度的重要性
掌握复杂度分析对于IT专业人员来说至关重要,因为它直接关系到程序的运行效率。通过复杂度分析,开发者能够预
极端事件预测:如何构建有效的预测区间
# 1. 极端事件预测概述
极端事件预测是风险管理、城市规划、保险业、金融市场等领域不可或缺的技术。这些事件通常具有突发性和破坏性,例如自然灾害、金融市场崩盘或恐怖袭击等。准确预测这类事件不仅可挽救生命、保护财产,而且对于制定应对策略和减少损失至关重要。因此,研究人员和专业人士持
【实时系统空间效率】:确保即时响应的内存管理技巧

# 1. 实时系统的内存管理概念
在现代的计算技术中,实时系统凭借其对时间敏感性的要求和对确定性的追求,成为了不可或缺的一部分。实时系统在各个领域中发挥着巨大作用,比如航空航天、医疗设备、工业自动化等。实时系统要求事件的处理能够在确定的时间内完成,这就对系统的设计、实现和资源管理提出了独特的挑战,其中最为核心的是内存管理。
内存管理是操作系统的一个基本组成部
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )