【进阶】Flask中的表单处理
发布时间: 2024-06-26 04:16:51 阅读量: 62 订阅数: 110 

处理表单详解

# 1. Flask表单处理概述**
Flask表单处理是一个强大的功能,它允许用户在Web应用程序中创建、验证和处理表单。表单是用户与Web应用程序交互的重要方式,它们用于收集用户输入、验证数据并执行各种操作。Flask提供了全面的表单处理支持,包括表单创建、验证、数据处理和自定义验证规则。通过使用Flask的表单处理功能,开发人员可以轻松创建交互式且用户友好的Web应用程序。
# 2. Flask表单处理基础
### 2.1 表单的创建和验证
#### 2.1.1 表单的创建
在Flask中,可以使用`Flask-WTF`库来创建表单。`Flask-WTF`是一个基于WTForms库的Flask扩展,它提供了创建、验证和处理表单所需的所有工具。
创建一个表单,需要继承`FlaskForm`类并定义表单字段。每个表单字段都对应一个HTML表单元素,如文本输入框、下拉列表或复选框。
```python
from flask_wtf import FlaskForm
from wtforms import StringField, IntegerField, SubmitField
class MyForm(FlaskForm):
name = StringField('姓名')
age = IntegerField('年龄')
submit = SubmitField('提交')
```
#### 2.1.2 表单的验证
表单验证是确保提交的数据有效和安全的关键步骤。`Flask-WTF`提供了多种内置验证器,如`Required`(必填)、`Email`(电子邮件)、`Length`(长度)等。
```python
from flask_wtf.validators import Required, Email, Length
class MyForm(FlaskForm):
name = StringField('姓名', validators=[Required()])
age = IntegerField('年龄', validators=[Required()])
email = StringField('邮箱', validators=[Required(), Email()])
submit = SubmitField('提交')
```
### 2.2 表单数据的处理
#### 2.2.1 表单数据的获取
当表单被提交时,可以使用`request.form`获取表单数据。`request.form`是一个字典,其中键是表单字段的名称,值是提交的数据。
```python
@app.route('/form', methods=['POST'])
def form():
form = MyForm(request.form)
if form.validate_on_submit():
name = request.form['name']
age = request.form['age']
email = request.form['email']
# 处理表单数据
```
#### 2.2.2 表单数据的处理和存储
获取表单数据后,就可以对其进行处理和存储。常见的处理方式包括:
* **数据验证:**再次验证表单数据,确保其有效和安全。
* **数据转换:**将表单数据转换为适当的类型,如整数、浮点数或布尔值。
* **数据存储:**将表单数据存储到数据库或其他持久化存储中。
```python
if form.validate_on_submit():
name = request.form['name']
age = int(request.form['age'])
email = request.form['email']
# 将数据存储到数据库
user = User(name=name, age=age, email=email)
db.session.add(user)
db.session.commit()
```
# 3. Flask表单处理进阶
### 3.1 自定义验证规则
在Flask表单处理中,内置的验证规则可能无法满足所有需求。因此,Flask允许用户自定义验证规则,以满足特定的业务需求。
#### 3.1.1 验证规则的定义
自定义验证规则需要定义一个验证器类,该类必须继承自`wtforms.validators.Validator`类。验证器类需要实现`__call__`方法,该方法接收一个表单字段和验证数据作为参数,并返回一个布尔值,表示验证是否通过。
例如,定义一个验证用户名是否包含数字的验证器:
```python
from wtforms.validators import ValidationError
class UsernameContainsNumberValidator(Validator):
def __call__(self, form, field):
if not any(char.isdigit() for char in field.data):
raise ValidationError('Username must contain at least one digit.')
```
#### 3.1.2 验证规则的应用
自定义验证规则可以通过`validators`参数应用到表单字段上。例如,将上面定义的验证器应用到用户名字段:
```python
from flask_wtf import FlaskForm
from wtforms import StringField, SubmitField
from wtforms.validators import DataRequired, Length, UsernameContainsNumberValidator
class RegistrationForm(FlaskForm):
username = StringField('Username', validators=[DataRequired(), Length(min=6, max=20), UsernameContainsNumberValidator()])
submit = SubmitField('Register')
```
### 3.2 表单的提交方式
Flask表单支持多种提交方式,包括GET和POS

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏汇集了全面的 Python 网络编程教程,涵盖从基础概念到高级实践的各个方面。
专栏从网络编程基础开始,介绍 TCP/IP 协议、socket 库和 HTTP 协议。然后深入探讨多线程、多进程和 I/O 多路复用等高级技术。还介绍了 asyncio 和 websockets 库,用于异步网络编程。
此外,专栏还提供了丰富的实战演练,指导读者构建聊天室、文件传输应用和 RESTful API 等实际项目。还涵盖了网络安全实践、加密通信和常见的网络攻击防御措施。
无论你是初学者还是经验丰富的开发者,本专栏都提供了全面的资源,帮助你掌握 Python 网络编程的各个方面。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
VL53L1X实战教程:硬件连接、配置要点及故障排除

# 摘要
本文详细介绍了VL53L1X激光传感器的各个方面,包括其概述、硬件连接指南、配置要点、故障排除技巧以及在不同应用场景下的高级应用拓展。通过对硬件接口、电源连接、物理安装的深入解析,本文提供了详细的硬件使用指导。同时,针对配置要点和故障排除提供了实用的技术细节,包括初始化、距离测量模式、中断与GPIO配置,以及通信
ICGC数据库架构揭秘:生物信息学高效工作流构建指南

# 摘要
生物信息学是利用计算和分析方法来解读生物数据的领域,而国际癌症基因组协作组(ICGC)数据库为研究者提供了一个宝贵的数据资源。本文旨在介绍生物信息学的基础以及ICGC数据库的架构和应用,讨论了如何构建和维护生物信息学工作流。通过解析ICGC数据库的组成、数据模型、性能优化,以及工作流设计、自动化、监控和数据集成的实践,本文详细阐述了基因组数据分析、项目管理、个
Pajek数据处理手册:网络数据的清理、准备与分析

# 摘要
Pajek软件作为一种强大的网络分析工具,在处理、分析和可视化大规模网络数据方面发挥着重要作用。本文首先概述了Pajek软件及其在数据处理中的重要性,随后详细探讨了网络数据的预处理和清理过程,包括缺失数据处理、异常值修正、数据格式转换,以及实战案例分析。此外,本文还涉及了网络数据的标准化、类型和结构分析,以及数据准备的高级技术。在数据分析技术方面,本文着重介绍了网络中心性和重要性度量,动态分
【计算机科学基石】:揭秘计算理论导引,深入剖析关键概念(理论与实践的完美融合)

# 摘要
本文综述了计算理论的基础知识及其历史发展,详细探讨了算法与数据结构的基本原理,包括时间复杂度和空间复杂度的分析方法,以及经典算法设计策略。通过分析图灵机模型和可计算性理论,本文揭示了计算模型的多样性与局限性。进一步,本文探索了编程范式理论,阐述了面向对象编程、函数式编程、声明式和逻辑编程的核心概念和应用。此外,本文研究了并发与并行理论,讨论了并发机制、编程模型以及并行计算的挑战与机
硬件工程师必备:8279芯片与数码管高效连接技巧

# 摘要
本文对8279芯片及其与数码管的应用进行了全面介绍和分析。首先,概述了8279芯片的基础知识和数码管的基本概念。随后,深入探讨了8279芯片的工作原理、内部结构及工作模式,以
铁路售票系统用例图的20个实战技巧:需求分析到实现的转换
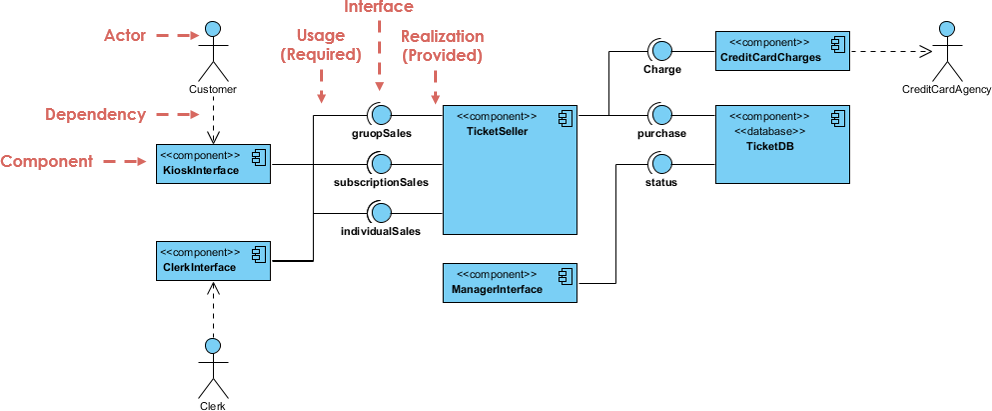
# 摘要
本文系统地探讨了铁路售票系统的用例图设计与应用,涵盖需求分析、理论基础、实战技巧以及用例图到实现的转换。文章首先概述了铁路售票系统用例图的基本概念,随后深入分析了用例图的绘制原则、步骤和技巧,并结合实际案例详细讨论了用例图在需求分析和系统设计中的应用。本文还特别强调了用例图在实战中的20个关键技巧,这些技巧有
华为IPMS技术架构深度揭秘:如何为企业营销注入科技动力
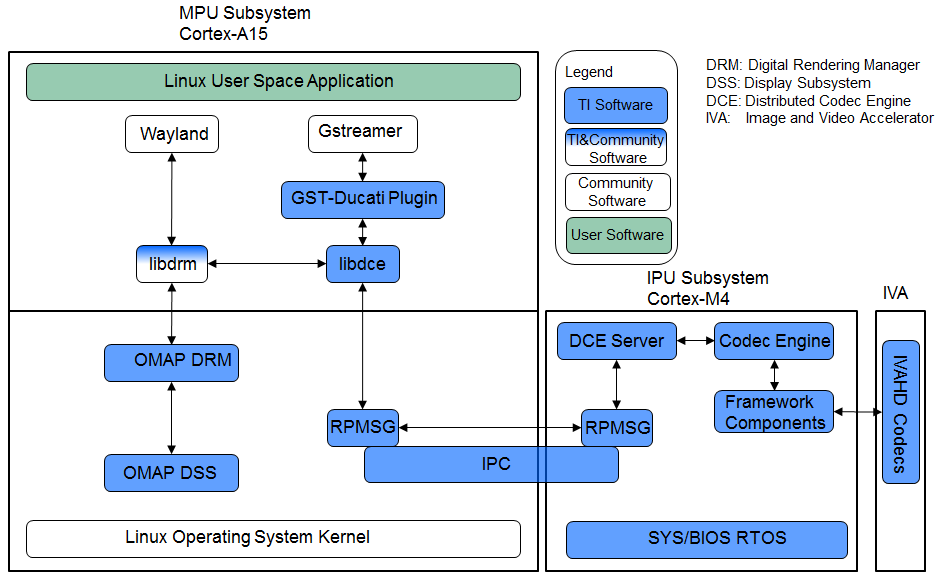
# 摘要
本文深入探讨了IPMS(Integrated Performance Management System)技术在现代企业营销中的应用及其架构理论基础。文章首先阐述了IPMS技术的重要性,并对其核心概念与关键技术和组件进行了详细介绍。随后,本文分析了IPMS架构的三个主要组成部分——数据采集层、数据处理层和数据应用
AD9200 vs 竞品:【选型全解析】与性能对比深度分析
# 摘要
本文旨在全面分析AD9200数据转换器的架构、性能和市场定位。首先,介绍了AD9200的内部架构及其工作原理。接着,通过与其它竞品的对比,详细阐述了AD9200的技术规格、信号完整性和电源效率等方面的特点。文中还详细描述了性能测试方法,包括实验环境配置、性能评估指标及优化策略。此外,文章提供了多个应用案例分析,以展示AD9200在不同领域的实际应用效果及性能反馈。最后,探讨了AD9200的市场定位、竞品动态和未来技术发展趋势,以及基于用户反馈的改进建议。
# 关键字
AD9200;数据转换器;信号完整性;噪声性能;性能测试;市场定位
参考资源链接:[AD9200:20MS/s高速
SLAM-GO-POST-PRO-V2.0深度解读:数据同步与时间戳校准的艺术
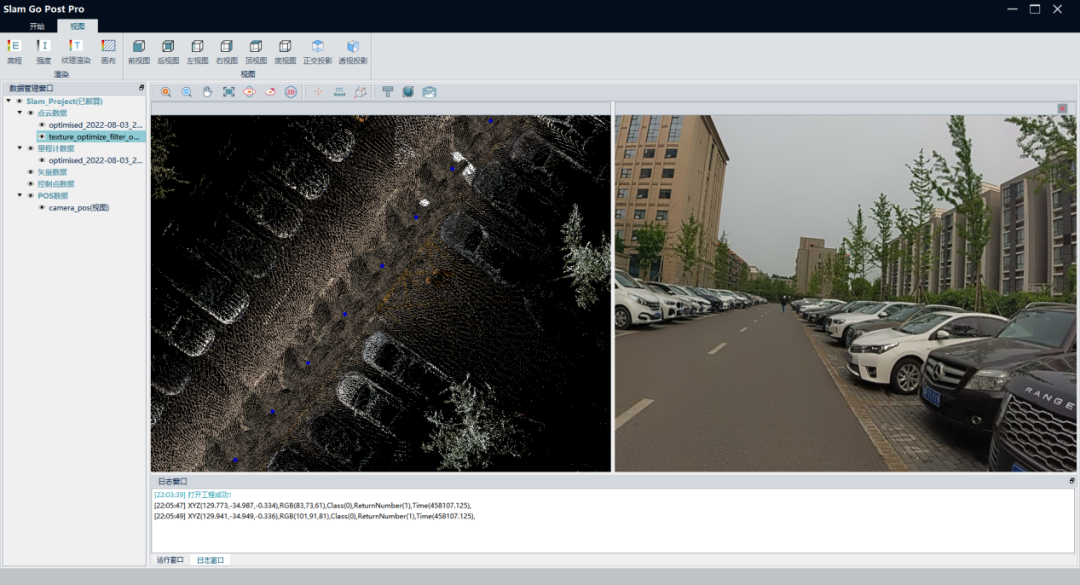
# 摘要
本论文全面探讨了SLAM(即时定位与地图构建)技术与数据同步,重点分析了时间戳校准在其中的核心作用及其重要性。文章首先介绍了时间戳的基本概念及其在SLAM中的关键角色,然后对比分析了不同时间同步机制和理论模型,包括硬件与软件同步方法和常见同步协议。在实践技巧章节,文中提供了多种数据同步工具的选择与应用方法、时间戳校准的实验设计,以及案例分析。进一步的,本文探讨了时间戳校准算法的优化、多
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )