如何选择最佳的MapReduce分区键:自定义分区的策略分析
发布时间: 2024-10-31 10:00:06 阅读量: 4 订阅数: 8 
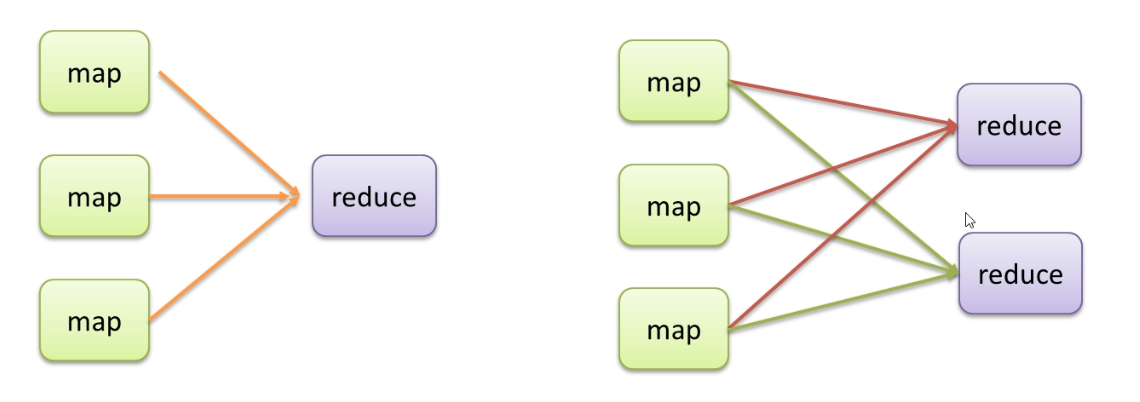
# 1. MapReduce分区键的原理与重要性
在分布式计算框架MapReduce中,分区键(Partition Key)是决定数据如何在不同Reduce任务之间分布的关键因素。理解分区键的原理及其在数据处理过程中的重要性,对于优化MapReduce作业的性能至关重要。分区键确保了数据在Map阶段被分配到相应的Reduce任务,从而影响了作业的并行化程度和执行效率。正确选择分区键可以有效避免数据倾斜现象,改善系统负载均衡,最终提升整体数据处理速度和作业运行效率。在下一章节中,我们将探讨分区键选择的理论基础,深入分析其作用及选择标准。
# 2. MapReduce分区键选择的理论基础
### 2.1 分区键的作用和影响
MapReduce作为一种分布式计算框架,在处理大规模数据集时,分区键(Partition Key)的作用至关重要。它直接影响到数据如何在Map和Reduce阶段进行分组处理。
#### 2.1.1 数据分布的均匀性分析
均匀性是评估分区键好坏的重要指标。理想情况下,分区键应该能够确保数据在整个集群中均匀分布。如果数据分布不均,则可能导致某些Reducer任务处理的数据量过大,而其他Reducer则空闲,这种现象被称为数据倾斜(Data Skew)。数据倾斜不仅会导致计算效率低下,还可能导致某些节点因负载过重而崩溃。分区键设计时应充分考虑如何避免数据倾斜。
例如,假设有一个在线零售数据集,每个记录包含用户ID和购买的商品ID。如果选择商品ID作为分区键,可能会出现部分热门商品被大量用户购买,造成特定分区负载过重,而其他分区则相对空闲。
**代码示例:**
假设使用Hadoop的MapReduce框架,并选择用户ID作为分区键:
```java
// 用户定义的Partitioner
public static class UserPartitioner extends Partitioner<Text, Text> {
public int getPartition(Text key, Text value, int numPartitions) {
// 生成基于用户ID的哈希值
return (key.toString().hashCode() & Integer.MAX_VALUE) % numPartitions;
}
}
```
**参数说明和逻辑分析:**
该代码段定义了一个自定义的Partitioner类`UserPartitioner`,在`getPartition`方法中,使用用户ID字符串生成哈希值,并取其模数作为分区的依据。理想情况下,由于用户ID的分布较为均匀,这种分区方式能够保证数据较为均衡地分到不同的Reducer。
#### 2.1.2 负载均衡的必要性
在设计分区键时,必须考虑到负载均衡的需求。只有数据均匀地分配到各个Reducer,才能避免因某些节点处理能力不足而导致的处理瓶颈。负载均衡还意味着硬件资源的充分利用和计算成本的降低。
为实现负载均衡,我们可以采用以下策略:
- 使用哈希分区确保数据随机分布。
- 在存在明确业务逻辑的情况下,使用分区键的映射规则,如按照用户地域或产品类型分布数据。
### 2.2 分区键选择的标准与考量
选择合适的分区键并不是一项简单的任务,它需要考虑多个因素以确保MapReduce作业的高效运行。
#### 2.2.1 数据规模与数据类型
数据规模和数据类型直接影响分区键的选择。对于大规模数据集,分区键的设计尤为重要,因为数据倾斜问题会更加明显。对于特定类型的数据,如时间序列数据,可能需要根据时间戳来设计分区键。
**数据规模的考量:**
在数据量极大时,可能需要采用复合分区键(例如结合时间戳和用户ID),这样可以更细致地控制数据的分布,避免单个Reducer过载。
**数据类型的考量:**
对于键值对类型的数据,如用户购买记录,可以考虑使用键值作为分区键。对于文本数据,可能需要根据特定字段(如文章ID或日期)进行分区。
#### 2.2.2 MapReduce作业特性
MapReduce作业的特性也对分区键的选择有着重要的影响。不同的作业模式(如排序、过滤、连接等)需要根据作业的具体需求来确定合适的分区键。
**作业模式的考量:**
对于排序作业,可能需要根据排序字段来设计分区键。而对过滤作业,则可能需要根据过滤条件来确定分区键,以便于快速定位到相关数据。
#### 2.2.3 系统性能考量
分区键的选择还应考虑系统的性能。例如,不合理的分区键可能会导致网络传输的数据量增大,增加网络负载。同时,它也会影响到磁盘IO的性能,因为不均匀的数据分布会导致某些节点的磁盘读写频繁。
**性能的考量:**
在分区键设计时,应考虑数据的本地性,尽量减少跨节点的数据传输。此外,分区键还应考虑到减少磁盘IO的压力,例如,在进行数据排序时,可以将相近键值的数据放在同一分区,以减少随机读写。
### 总结
选择合适的MapReduce分区键是确保作业性能和效率的关键步骤。通过分析数据分布的均匀性、负载均衡、数据规模与类型、作业特性和系统性能等因素,可以为特定的应用场景制定出合理的分区策略。在下一章中,我们将详细探讨自定义分区策略的实践方法,通过具体的实现途径和优化实例分析,进一步深入理解分区键选择的实用性和有效

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面解析了 MapReduce 中自定义分区技术的方方面面。从基础概念到高级技巧,专栏深入探讨了如何通过自定义分区来优化数据分布,提升任务效率,避免常见误区。通过一系列标题,如“MapReduce 自定义分区的终极指南”和“MapReduce 分区优化全书”,专栏提供了全面的指导,涵盖了自定义 Partitioner 的步骤详解、数据倾斜解决方案、性能影响分析和最佳分区键选择策略。通过这些深入的见解,读者可以掌握自定义分区的精髓,从而大幅提升 MapReduce 大数据处理的效率和性能。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【大数据精细化管理】:掌握ReduceTask与分区数量的精准调优技巧

# 1. 大数据精细化管理概述
在当今的信息时代,企业与组织面临着数据量激增的挑战,这要求我们对大数据进行精细化管理。大数据精细化管理不仅关系到数据的存储、处理和分析的效率,还直接关联到数据价值的最大化。本章节将概述大数据精细化管理的概念、重要性及其在业务中的应用。
大数据精细化管理涵盖从数据
【数据访问速度优化】:分片大小与数据局部性策略揭秘
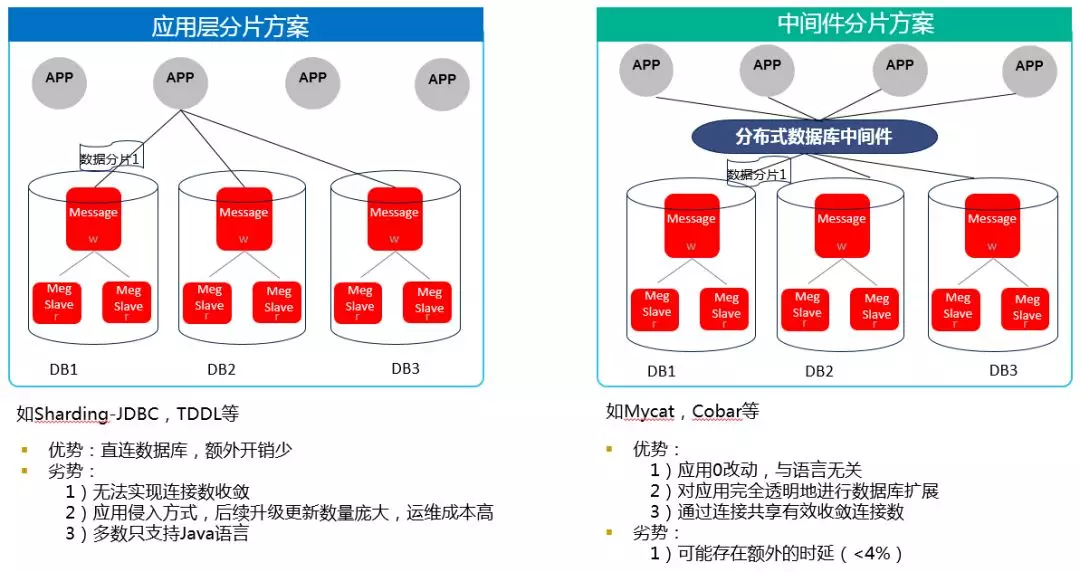
# 1. 数据访问速度优化概论
在当今信息化高速发展的时代,数据访问速度在IT行业中扮演着至关重要的角色。数据访问速度的优化,不仅仅是提升系统性能,它还可以直接影响用户体验和企业的经济效益。本章将带你初步了解数据访问速度优化的重要性,并从宏观角度对优化技术进行概括性介绍。
## 1.1 为什么要优化数据访问速度?
优化数据访问速度是确保高效系统性能的关键因素之一
项目中的Map Join策略选择
# 1. Map Join策略概述
Map Join策略是现代大数据处理和数据仓库设计中经常使用的一种技术,用于提高Join操作的效率。它主要依赖于MapReduce模型,特别是当一个较小的数据集需要与一个较大的数据集进行Join时。本章将介绍Map Join策略的基本概念,以及它在数据处理中的重要性。
Map Join背后的核心思想是预先将小数据集加载到每个Map任
MapReduce小文件处理:数据预处理与批处理的最佳实践

# 1. MapReduce小文件处理概述
## 1.1 MapReduce小文件问题的普遍性
在大规模数据处理领域,MapReduce小文件问题普遍存在,严重影响
【负载均衡】:MapReduce Join操作的动态资源分配策略

# 1. MapReduce Join操作概述
MapReduce是一种编程模型,用于处理大规模数据集的并行运算。其中,Join操作是MapReduce中的一种重要操作,主要用于将多个数据源中的数据进行合并和关联。在大数据处理中,Join操作往往涉及到大量的数据交互和计算,对系统性能的影响尤为显著。
Join操作在MapReduce中的实现方式主要有两种,即Map端Join和Re
【数据仓库Join优化】:构建高效数据处理流程的策略

# 1. 数据仓库Join操作的基础理解
## 数据库中的Join操作简介
在数据仓库中,Join操作是连接不同表之间数据的核心机制。它允许我们根据特定的字段,合并两个或多个表中的数据,为数据分析和决策支持提供整合后的视图。Join的类型决定了数据如何组合,常用的SQL Join类型包括INNER JOIN、LEFT JOIN、RIGHT JOIN、FULL JOIN等。
## SQL Joi
MapReduce自定义分区:规避陷阱与错误的终极指导

# 1. MapReduce自定义分区的理论基础
MapReduce作为一种广泛应用于大数据处理的编程模型,其核心思想在于将计算任务拆分为Map(映射)和Reduce(归约)两个阶段。在MapReduce中,数据通过键值对(Key-Value Pair)的方式被处理,分区器(Partitioner)的角色是决定哪些键值对应该发送到哪一个Reducer。这种机制至关
MapReduce中的Combiner与Reducer选择策略:如何判断何时使用Combiner
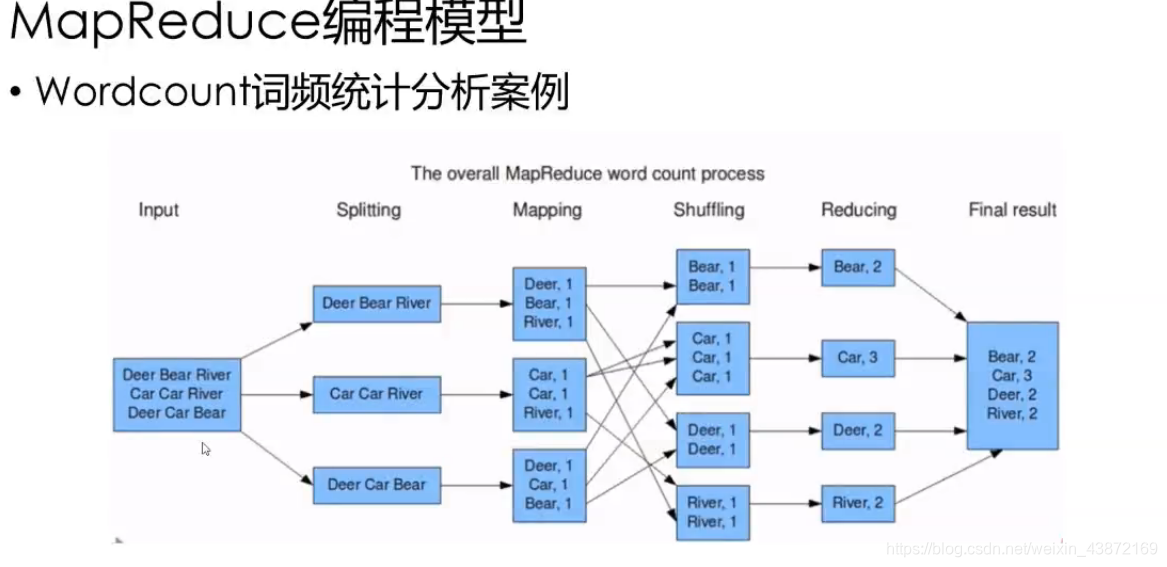
# 1. MapReduce框架基础
MapReduce 是一种编程模型,用于处理大规模数据集
MapReduce与大数据:挑战PB级别数据的处理策略

# 1. MapReduce简介与大数据背景
## 1.1 大数据的定义与特性
大数据(Big Data)是指传统数据处理应用软件难以处
跨集群数据Shuffle:MapReduce Shuffle实现高效数据流动

# 1. MapReduce Shuffle基础概念解析
## 1.1 Shuffle的定义与目的
MapReduce Shuffle是Hadoop框架中的关键过程,用于在Map和Reduce任务之间传递数据。它确保每个Reduce任务可以收到其处理所需的正确数据片段。Shuffle过程主要涉及数据的排序、分组和转移,目的是保证数据的有序性和局部性,以便于后续处理。
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )