【Python爬虫数据可视化实战指南】:从数据提取到可视化呈现
发布时间: 2024-07-20 16:38:53 阅读量: 42 订阅数: 22 

python爬虫数据可视化分析大作业.zip

# 1. Python爬虫基础**
Python爬虫是一种用于从网页中提取数据的自动化工具。它通过模拟浏览器行为,发送HTTP请求并解析响应内容来工作。
Python爬虫库包括Requests、BeautifulSoup和Selenium。Requests用于发送HTTP请求,BeautifulSoup用于解析HTML,Selenium用于模拟浏览器行为。
爬虫过程通常包括以下步骤:
- 发送HTTP请求获取网页内容
- 解析HTML提取所需数据
- 存储或处理提取的数据
# 2. Python爬虫数据提取技巧
### 2.1 网页结构分析
网页结构分析是爬虫数据提取的基础。通过分析网页结构,可以了解网页中不同元素的分布和组织方式,从而制定有效的爬取策略。
常见的网页结构分析工具包括:
* **浏览器开发者工具:**大多数浏览器都提供开发者工具,可以查看网页的HTML结构和CSS样式。
* **第三方库:**如BeautifulSoup、lxml等库可以帮助解析HTML和XML文档。
### 2.2 HTML解析库的使用
HTML解析库是用来解析HTML文档的工具。它们可以将HTML文档转换为结构化的数据,方便爬虫提取所需信息。
常用的HTML解析库包括:
* **BeautifulSoup:**一个流行的HTML解析库,提供了丰富的解析和选择器功能。
* **lxml:**一个基于libxml2的HTML解析库,性能优异,支持多种解析器。
#### 代码示例
```python
from bs4 import BeautifulSoup
# 解析HTML文档
soup = BeautifulSoup(html_content, "html.parser")
# 查找所有class为"article"的元素
articles = soup.find_all("article", class_="article")
# 提取每个元素的标题和内容
for article in articles:
title = article.find("h1").text
content = article.find("div", class_="content").text
```
### 2.3 动态网页爬取
动态网页是通过JavaScript动态加载内容的网页。对于爬虫来说,直接请求动态网页可能会导致数据缺失。
处理动态网页爬取的方法包括:
* **使用无头浏览器:**如Selenium、Puppeteer等工具可以模拟浏览器行为,动态加载内容后进行爬取。
* **分析AJAX请求:**动态网页通常通过AJAX请求加载数据,可以通过抓包工具分析请求并直接请求数据。
#### 代码示例
```python
from selenium import webdriver
# 使用Selenium模拟浏览器行为
driver = webdriver.Chrome()
driver.get("https://example.com")
# 等待页面加载完成
driver.implicitly_wait(10)
# 查找所有class为"article"的元素
articles = driver.find_elements_by_class_name("article")
# 提取每个元素的标题和内容
for article in articles:
title = article.find_element_by_tag_name("h1").text
content = article.find_element_by_class_name("content").text
```
### 2.4 反爬虫机制的应对
网站为了防止爬虫抓取数据,可能会采用反爬虫机制,如:
* **验证码:**要求用户输入验证码以验证身份。
* **IP封禁:**检测和封禁频繁访问的IP地址。
* **UA伪装:**检测和封禁非浏览器UA。
应对反爬虫机制的方法包括:
* **使用代理IP:**通过代理服务器隐藏真实IP地址。
* **伪装UA:**使用随机或模拟浏览器的UA。
* **破解验证码:**使用OCR或机器学习技术破解验证码。
#### 代码示例
```python
import requests
# 使用代理IP
proxies = {
"http": "http://127.0.0.1:8080",
"https": "https://127.0.0.1:8080",
}
# 伪装UA
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
# 发送请求
response = requests.get("https://example.com", proxies=proxies, headers=headers)
```
# 3. Python数据可视化基础
### 3.1 数据可视化的概念和类型
**概念:**
数据可视化是一种将数据转换为视觉表示形式的技术,旨在帮助人们更轻松、更有效地理解和分析数据。
**类型:**
数据可视化的类型多种多样,包括:
- **静态图表:**一次性生成的图表,例如折线图、柱状图、饼图和散点图。
- **交互式图表:**允许用户与图表进行交互,例如放大、缩小、过滤和排序。
- **地图可视化:**将数据映射到地理位置,例如热力图和符号地图。
- **仪表盘:**将多个图表和指标组合在一起,提供对数据的高级视图。
### 3.2 Python数据可视化库简介
Python提供了丰富的库来支持数据可视化,包括:
- **Matplotlib:**用于创建静态图表。
- **Seaborn:**基于Matplotlib构建,提供高级绘图功能。
- **Plotly:**用于创建交互式图表。
- **Bokeh:**用于创建交互式图表和仪表盘。
- **Geopandas:**用于创建地图可视化。
### 3.3 数据清洗和预处理
在进行数据可视化之前,通常需要对数据进行清洗和预处理,以确保数据准确、一致且适合可视化。
**数据清洗:**
- **删除缺失值:**使用`dropna()`或`fillna()`等方法删除包含缺失值的记录或列。
- **处理异常值:**使用`clip()`或`replace()`等方法处理异常值,例如将异常值替换为中位数或平均值。
- **标准化数据:**使用`scale()`或`normalize()`等方法将数据缩放或归一化到特定范围。
**数据预处理:**
- **创建衍生变量:**使用`transform()`或`apply()`等方法创建新变量或转换现有变量。
- **分组和聚合:**使用`groupby()`和`agg()`等方法对数据进行分组并聚合,例如计算平均值或求和。
- **排序和过滤:**使用`sort_values()`和`query()`等方法对数据进行排序或过滤,以突出显示特定模式或趋势。
### 代码示例:
```python
import pandas as pd
import matplotlib.pyplot as plt
# 读取数据
df = pd.read_csv('data.csv')
# 数据清洗
df = df.dropna()
df['age'] = df['age'].clip(18, 100)
# 数据预处理
df['age_group'] = pd.cut(df['age'], bins=[18, 25, 35, 45, 55, 65, 100], labels=['18-24', '25-34', '35-44', '45-54', '55-64', '65+'])
df = df.groupby('age_group').agg({'salary': 'mean'})
# 数据可视化
plt.bar(df.index, df['salary'])
plt.xlabel('Age Group')
plt.ylabel('Salary')
plt.title('Average Salary by Age Group')
plt.show()
```
**逻辑分析:**
这段代码使用Pandas和Matplotlib进行数据可视化。它首先读取数据并进行清洗和预处理,包括删除缺失值、处理异常值、创建衍生变量和分组聚合。然后,它使用Matplotlib绘制一个条形图,显示每个年龄组的平均工资。
# 4. Python数据可视化实践**
### 4.1 静态图表绘制
静态图表是数据可视化的基本形式,它将数据以固定格式呈现,通常用于展示数据分布、趋势和比较。
#### 4.1.1 折线图和柱状图
折线图和柱状图是两种最常见的静态图表类型。折线图用于展示数据的变化趋势,而柱状图用于比较不同类别的数据。
```python
import matplotlib.pyplot as plt
# 折线图
plt.plot([1, 2, 3, 4], [5, 6, 7, 8])
plt.xlabel("X")
plt.ylabel("Y")
plt.title("折线图")
plt.show()
# 柱状图
plt.bar([1, 2, 3, 4], [5, 6, 7, 8])
plt.xlabel("X")
plt.ylabel("Y")
plt.title("柱状图")
plt.show()
```
**代码逻辑分析:**
* `plt.plot()`函数绘制折线图,其中第一个参数为x轴数据,第二个参数为y轴数据。
* `plt.bar()`函数绘制柱状图,其中第一个参数为x轴数据,第二个参数为y轴数据。
* `plt.xlabel()`、`plt.ylabel()`和`plt.title()`函数分别设置x轴标签、y轴标签和图表标题。
* `plt.show()`函数显示图表。
#### 4.1.2 饼图和散点图
饼图用于展示数据在不同类别中的分布,而散点图用于展示两个变量之间的关系。
```python
# 饼图
labels = ['A', 'B', 'C', 'D']
sizes = [10, 20, 30, 40]
plt.pie(sizes, labels=labels, autopct='%1.1f%%')
plt.title("饼图")
plt.show()
# 散点图
plt.scatter([1, 2, 3, 4], [5, 6, 7, 8])
plt.xlabel("X")
plt.ylabel("Y")
plt.title("散点图")
plt.show()
```
**代码逻辑分析:**
* `plt.pie()`函数绘制饼图,其中第一个参数为数据大小,第二个参数为数据标签,第三个参数为数据百分比格式。
* `plt.scatter()`函数绘制散点图,其中第一个参数为x轴数据,第二个参数为y轴数据。
### 4.2 交互式图表绘制
交互式图表允许用户与图表进行交互,从而获得更深入的数据见解。
#### 4.2.1 地图可视化
地图可视化可以将数据映射到地理位置,从而展示数据在空间上的分布。
```python
import folium
# 创建地图
map = folium.Map(location=[39.9042, 116.4074], zoom_start=12)
# 添加标记
folium.Marker([39.9042, 116.4074], popup='北京').add_to(map)
# 保存地图
map.save('map.html')
```
**代码逻辑分析:**
* `folium.Map()`函数创建地图,其中第一个参数为地图中心坐标,第二个参数为初始缩放级别。
* `folium.Marker()`函数添加标记,其中第一个参数为标记坐标,第二个参数为标记弹出信息。
* `map.save()`函数保存地图为HTML文件。
#### 4.2.2 仪表盘设计
仪表盘是一种交互式图表,它将多个图表和组件组合在一起,提供实时数据监控和分析。
```python
import dash
import dash_core_components as dcc
import dash_html_components as html
import plotly.graph_objs as go
# 创建仪表盘应用程序
app = dash.Dash(__name__)
# 仪表盘布局
app.layout = html.Div([
dcc.Graph(id='line-chart', figure=go.Figure(
data=[go.Scatter(x=[1, 2, 3, 4], y=[5, 6, 7, 8])],
layout=go.Layout(title='折线图')
)),
dcc.Graph(id='pie-chart', figure=go.Figure(
data=[go.Pie(labels=['A', 'B', 'C', 'D'], values=[10, 20, 30, 40])],
layout=go.Layout(title='饼图')
))
])
# 运行仪表盘应用程序
if __name__ == '__main__':
app.run_server(debug=True)
```
**代码逻辑分析:**
* `dash.Dash()`函数创建仪表盘应用程序。
* `html.Div()`函数定义仪表盘布局,其中包含两个图表组件。
* `dcc.Graph()`函数创建图表,其中第一个参数为图表ID,第二个参数为图表数据和布局。
* `go.Scatter()`函数创建折线图,其中第一个参数为x轴数据,第二个参数为y轴数据。
* `go.Pie()`函数创建饼图,其中第一个参数为数据标签,第二个参数为数据大小。
* `app.run_server()`函数运行仪表盘应用程序。
# 5. Python数据可视化实战案例
### 5.1 社交媒体数据分析
社交媒体平台产生了大量的数据,这些数据可以用来分析用户行为、市场趋势和客户情绪。Python提供了一系列库,如Pandas、NumPy和Matplotlib,可以有效地处理和可视化这些数据。
**案例:分析Twitter数据**
**步骤:**
1. **数据收集:**使用Tweepy库从Twitter API收集推文数据。
2. **数据清洗:**使用Pandas清理数据,删除无效数据和重复数据。
3. **数据分析:**使用NumPy进行数据统计分析,计算推文数量、热门话题和用户参与度。
4. **数据可视化:**使用Matplotlib创建图表,可视化推文数量随时间的变化、热门话题分布和用户参与度。
```python
import tweepy
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 设置Twitter API凭证
consumer_key = 'YOUR_CONSUMER_KEY'
consumer_secret = 'YOUR_CONSUMER_SECRET'
access_token = 'YOUR_ACCESS_TOKEN'
access_token_secret = 'YOUR_ACCESS_TOKEN_SECRET'
# 创建Tweepy API对象
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
# 设置搜索查询
query = 'python'
# 从Twitter API收集推文
tweets = api.search_tweets(q=query, count=100)
# 将推文数据转换为DataFrame
df = pd.DataFrame([tweet.text for tweet in tweets], columns=['text'])
# 清洗数据
df = df[df['text'].notna()]
df = df.drop_duplicates()
# 分析数据
num_tweets = df.shape[0]
top_hashtags = df['text'].str.extractall(r'#(\w+)').groupby(0).size().sort_values(ascending=False).head(10)
top_users = df['text'].str.extractall(r'@(\w+)').groupby(0).size().sort_values(ascending=False).head(10)
# 可视化数据
plt.figure(figsize=(10, 6))
plt.plot(df['created_at'], df['text'].str.len())
plt.xlabel('Date')
plt.ylabel('Tweet Length')
plt.title('Tweet Length Over Time')
plt.show()
plt.figure(figsize=(10, 6))
plt.bar(top_hashtags.index, top_hashtags.values)
plt.xlabel('Hashtag')
plt.ylabel('Frequency')
plt.title('Top Hashtags')
plt.show()
plt.figure(figsize=(10, 6))
plt.bar(top_users.index, top_users.values)
plt.xlabel('User')
plt.ylabel('Frequency')
plt.title('Top Users')
plt.show()
```
### 5.2 金融数据可视化
金融数据可视化对于理解市场趋势、识别投资机会和管理风险至关重要。Python提供了Plotly、Bokeh和Seaborn等库,可以创建交互式和信息丰富的金融图表。
**案例:可视化股票价格数据**
**步骤:**
1. **数据获取:**使用Yahoo Finance API或其他数据源获取股票价格数据。
2. **数据预处理:**使用Pandas转换数据格式,并计算移动平均线和技术指标。
3. **数据可视化:**使用Plotly创建交互式图表,显示股票价格、移动平均线和技术指标。
```python
import pandas as pd
import plotly.graph_objs as go
# 获取股票价格数据
data = pd.read_csv('stock_prices.csv')
# 计算移动平均线
data['MA50'] = data['Close'].rolling(50).mean()
data['MA200'] = data['Close'].rolling(200).mean()
# 创建交互式图表
fig = go.Figure()
fig.add_trace(go.Scatter(x=data['Date'], y=data['Close'], name='Close Price'))
fig.add_trace(go.Scatter(x=data['Date'], y=data['MA50'], name='50-Day Moving Average'))
fig.add_trace(go.Scatter(x=data['Date'], y=data['MA200'], name='200-Day Moving Average'))
fig.update_layout(
title='Stock Price Visualization',
xaxis_title='Date',
yaxis_title='Price',
hovermode='closest'
)
fig.show()
```
### 5.3 地理信息系统(GIS)应用
GIS是一种用于管理和分析地理空间数据的系统。Python提供了GeoPandas和PyQGIS等库,可以处理和可视化GIS数据。
**案例:可视化人口密度数据**
**步骤:**
1. **数据获取:**从美国人口普查局或其他数据源获取人口密度数据。
2. **数据预处理:**使用GeoPandas将数据加载到GeoDataFrame中,并进行空间操作,如缓冲区分析。
3. **数据可视化:**使用PyQGIS创建地图,可视化人口密度分布。
```python
import geopandas as gpd
import pyqgis
# 加载人口密度数据
data = gpd.read_file('population_density.shp')
# 创建缓冲区
buffer_distance = 1000 # 以米为单位
data['buffer'] = data.geometry.buffer(buffer_distance)
# 创建地图
m = pyqgis.MapCanvas()
layer = pyqgis.Layer('population_density.shp')
m.addLayer(layer)
# 设置样式
layer.setStyle(pyqgis.style.GraduatedSymbolRenderer(
'population_density',
pyqgis.style.ClassificationMethod.EqualInterval,
5,
pyqgis.style.Symbol.Marker.Circle,
'size',
'color'
# 缩放地图
m.zoomToSelected()
# 显示地图
m.show()
```
# 6. Python数据可视化进阶
### 6.1 3D可视化
3D可视化技术可以将数据以三维的形式呈现,增强数据展示的沉浸感和交互性。Python中常用的3D可视化库包括:
- **Mayavi:**一个面向科学和工程应用的3D可视化库,支持交互式可视化和数据探索。
- **Plotly:**一个基于Web的交互式3D可视化库,提供丰富的图表类型和自定义选项。
- **VisPy:**一个高性能的3D可视化库,支持实时渲染和交互。
**代码示例:**
```python
import mayavi.mlab as mlab
# 创建一个3D散点图
data = np.random.rand(100, 3)
mlab.points3d(data[:, 0], data[:, 1], data[:, 2], colormap="jet")
mlab.show()
```
### 6.2 大数据可视化
大数据可视化技术旨在处理和展示海量数据,以发现模式和洞察。Python中常用的大数据可视化库包括:
- **D3.js:**一个基于JavaScript的交互式数据可视化库,支持处理和展示大量数据。
- **Bokeh:**一个基于Python的交互式数据可视化库,支持大数据可视化和实时更新。
- **Apache Zeppelin:**一个基于Web的交互式数据分析和可视化平台,支持大数据处理和展示。
**代码示例:**
```python
import bokeh.plotting as bp
import pandas as pd
# 加载大数据文件
df = pd.read_csv("large_data.csv")
# 创建一个交互式散点图
p = bp.figure(title="Large Data Scatter Plot")
p.scatter("x", "y", source=df)
p.show(browser=True)
```
### 6.3 数据可视化最佳实践
遵循数据可视化最佳实践可以创建清晰有效的数据可视化。一些关键的最佳实践包括:
- **选择合适的图表类型:**根据数据的类型和目的选择最合适的图表类型。
- **使用一致的配色方案:**保持图表中的配色方案一致,以增强可读性和美观性。
- **添加标签和注释:**清晰地标记图表中的轴、标签和注释,以帮助观众理解数据。
- **考虑交互性:**根据需要添加交互性元素,例如缩放、平移和筛选,以增强用户体验。
- **优化性能:**对于大数据可视化,优化代码以提高性能并确保流畅的交互。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 爬虫数据可视化的方方面面。从揭示数据背后的洞察到提升分析能力,再到实战案例剖析和性能优化技巧,专栏提供了全面的指南,帮助读者掌握数据可视化的艺术。此外,专栏还涵盖了数据清洗、图表选择、移动端可视化、大数据可视化等主题,以及数据可视化在机器学习、数据挖掘、商业智能、数据新闻和金融科技中的应用。通过深入浅出的讲解和丰富的案例分析,本专栏旨在帮助读者充分利用 Python 爬虫数据可视化,从数据中提取有价值的见解并做出明智的决策。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【电子打印小票的前端实现】:用Electron和Vue实现无缝打印

# 摘要
电子打印小票作为商业交易中不可或缺的一部分,其需求分析和实现对于提升用户体验和商业效率具有重要意义。本文首先介绍了电子打印小票的概念,接着深入探讨了Electron和Vue.js两种前端技术的基础知识及其优势,阐述了如何将这两者结合,以实现高效、响应
【EPLAN Fluid精通秘籍】:基础到高级技巧全覆盖,助你成为行业专家
# 摘要
EPLAN Fluid是针对工程设计的专业软件,旨在提高管道和仪表图(P&ID)的设计效率与质量。本文首先介绍了EPLAN Fluid的基本概念、安装流程以及用户界面的熟悉方法。随后,详细阐述了软件的基本操作,包括绘图工具的使用、项目结构管理以及自动化功能的应用。进一步地,本文通过实例分析,探讨了在复杂项目中如何进行规划实施、设计技巧的运用和数据的高效管理。此外,文章还涉及了高级优化技巧,包括性能调优和高级项目管理策略。最后,本文展望了EPLAN Fluid的未来版本特性及在智能制造中的应用趋势,为工业设计人员提供了全面的技术指南和未来发展方向。
# 关键字
EPLAN Fluid
小红书企业号认证优势大公开:为何认证是品牌成功的关键一步
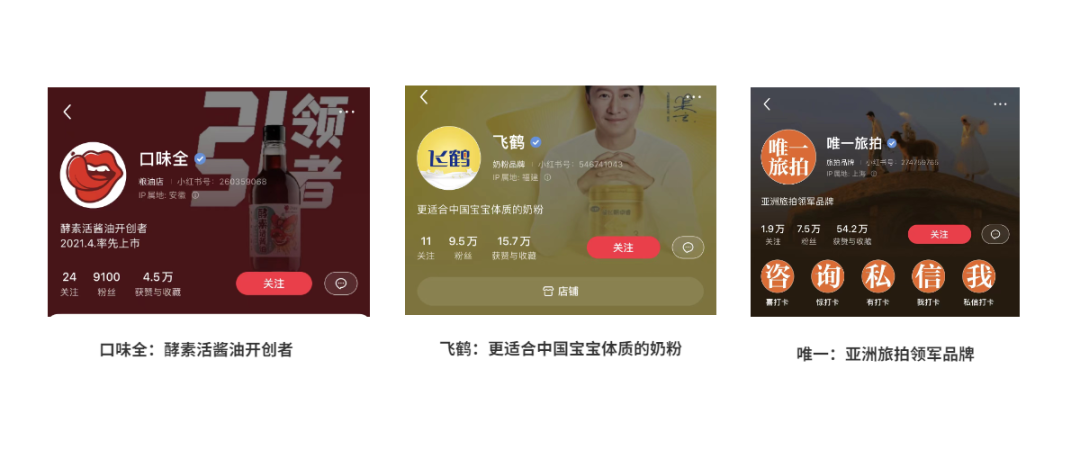
# 摘要
小红书企业号认证是品牌在小红书平台上的官方标识,代表了企业的权威性和可信度。本文概述了小红书企业号的市场地位和用户画像,分析了企业号与个人账号的区别及其市场意义,并详细解读了认证过程与要求。文章进一步探讨了企业号认证带来的优势,包括提升品牌权威性、拓展功能权限以及商业合作的机会。接着,文章提出了企业号认证后的运营策略,如内容营销、用户互动和数据分析优化。通过对成功认证案例的研究,评估
【用例图与图书馆管理系统的用户交互】:打造直观界面的关键策略
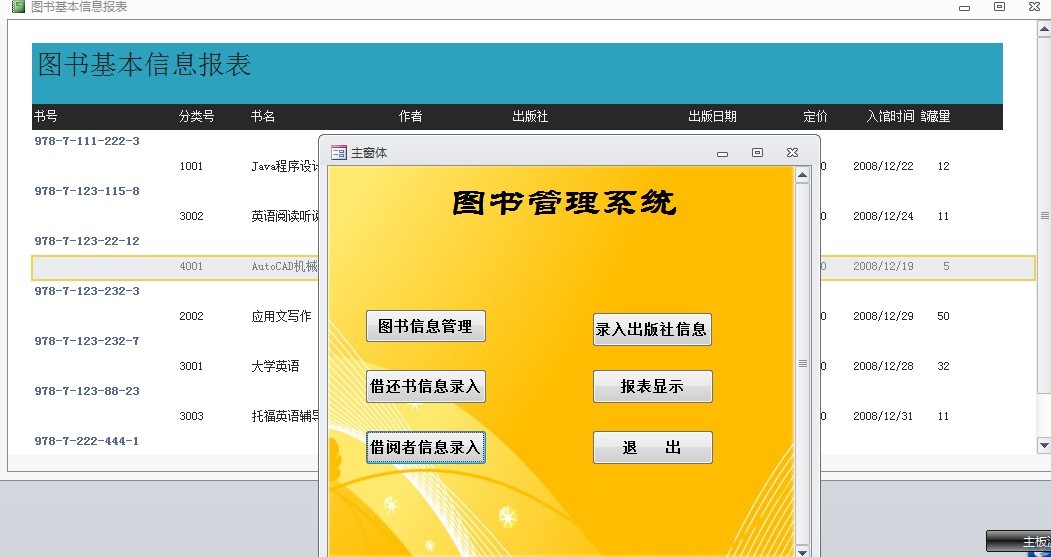
# 摘要
本文旨在探讨用例图在图书馆管理系统设计中的应用,从基础理论到实际应用进行了全面分析。第一章概述了用例图与图书馆管理系统的相关性。第二章详细介绍了用例图的理论基础、绘制方法及优化过程,强调了其在系统分析和设计中的作用。第三章则集中于用户交互设计原则和实现,包括用户界面布局、交互流程设计以及反馈机制。第四章具体阐述了用例图在功能模块划分、用户体验设计以及系统测试中的应用。
FANUC面板按键深度解析:揭秘操作效率提升的关键操作
# 摘要
FANUC面板按键作为工业控制中常见的输入设备,其功能的概述与设计原理对于提高操作效率、确保系统可靠性及用户体验至关重要。本文系统地介绍了FANUC面板按键的设计原理,包括按键布局的人机工程学应用、触觉反馈机制以及电气与机械结构设计。同时,本文也探讨了按键操作技巧、自定义功能设置以及错误处理和维护策略。在应用层面,文章分析了面板按键在教育培训、自动化集成和特殊行业中的优化策略。最后,本文展望了按键未来发展趋势,如人工智能、机器学习、可穿戴技术及远程操作的整合,以及通过案例研究和实战演练来提升实际操作效率和性能调优。
# 关键字
FANUC面板按键;人机工程学;触觉反馈;电气机械结构
华为SUN2000-(33KTL, 40KTL) MODBUS接口安全性分析与防护

# 摘要
本文深入探讨了MODBUS协议在现代工业通信中的基础及应用背景,重点关注SUN2000-(33KTL, 40KTL)设备的MODBUS接口及其安全性。文章首先介绍了MODBUS协议的基础知识和安全性理论,包括安全机制、常见安全威胁、攻击类型、加密技术和认证方法。接着,文章转入实践,分析了部署在SUN2
【高速数据传输】:PRBS的优势与5个应对策略

# 摘要
本文旨在探讨高速数据传输的背景、理论基础、常见问题及其实践策略。首先介绍了高速数据传输的基本概念和背景,然后详细分析了伪随机二进制序列(PRBS)的理论基础及其在数据传输中的优势。文中还探讨了在高速数据传输过程中可能遇到的问题,例如信号衰减、干扰、传输延迟、带宽限制和同步问题,并提供了相应的解决方案。接着,文章提出了一系列实际应用策略,包括PRBS测试、信号处理技术和高效编码技术。最后,通过案例分析,本文展示了PRBS在
【GC4663传感器应用:提升系统性能的秘诀】:案例分析与实战技巧
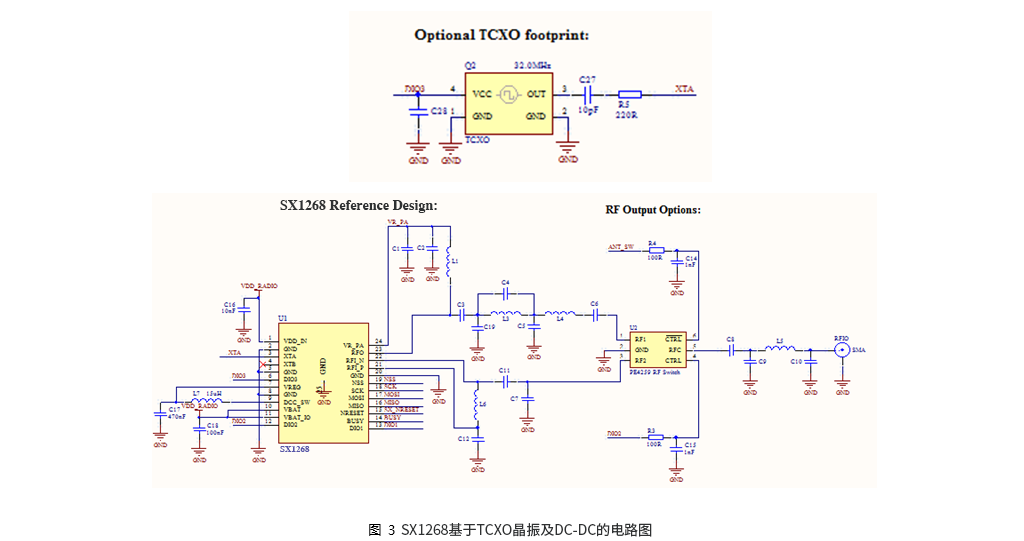
# 摘要
GC4663传感器是一种先进的检测设备,广泛应用于工业自动化和科研实验领域。本文首先概述了GC4663传感器的基本情况,随后详细介绍了其理论基础,包括工作原理、技术参数、数据采集机制、性能指标如精度、分辨率、响应时间和稳定性。接着,本文分析了GC4663传感器在系统性能优化中的关键作用,包括性能监控、数据处理、系统调优策略。此外,本文还探讨了GC4663传感器在硬件集成、软件接口编程、维护和故障排除方面的
NUMECA并行计算工程应用案例:揭秘性能优化的幕后英雄
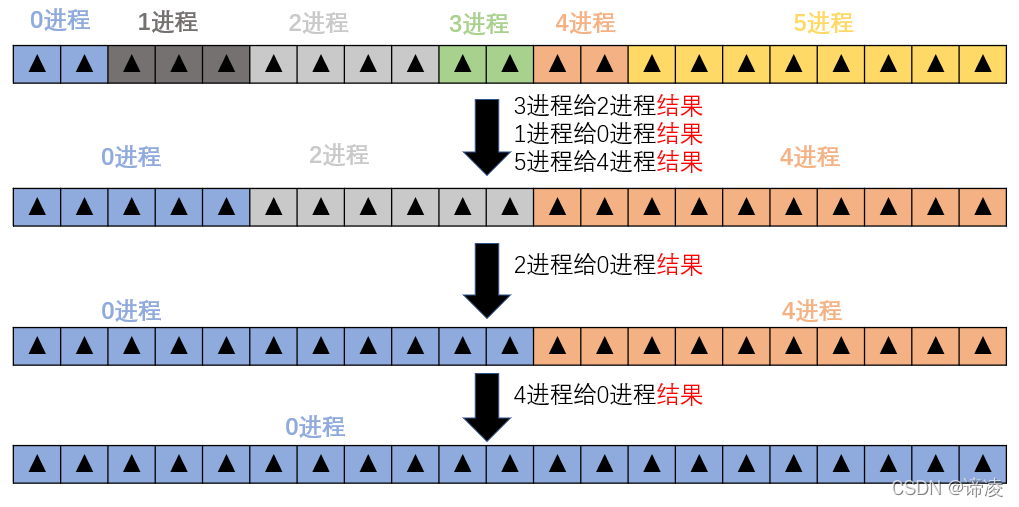
# 摘要
本文全面介绍NUMECA软件在并行计算领域的应用与实践,涵盖并行计算基础理论、软件架构、性能优化理论基础、实践操作、案例工程应用分析,以及并行计算在行业中的应用前景和知识拓展。通过探
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )