【Python进程间通信】:multiprocessing高级用法全解析
发布时间: 2024-10-02 07:33:45 阅读量: 118 订阅数: 36 
# 1. Python进程间通信概述
Python中的进程间通信(IPC)是一种允许运行中的程序或进程之间交换数据或信号的技术。在多任务操作系统中,进程间通信显得尤为重要,因为它支持并发执行和资源共享。
## 1.1 Python中的进程间通信
在Python中,进程间通信可以分为几种主要的方式,包括但不限于管道(pipes)、队列(queues)、共享内存、套接字(sockets)和信号(signals)。这些技术提供了不同的数据交换机制,以满足不同的应用场景需求。
## 1.2 进程间通信的重要性
进程间通信不仅促进了模块化和代码重用,还允许程序在多核或多处理器系统中并行执行,提高程序的运行效率和响应速度。对于数据密集型或计算密集型的任务,良好的进程间通信机制是优化性能和可扩展性的关键。
## 1.3 Python IPC的挑战和解决方案
Python的IPC面临诸多挑战,如死锁、资源竞争和同步问题。为了解决这些问题,开发者可以利用Python标准库中的`multiprocessing`模块,该模块提供了丰富的工具来管理进程间通信,包括进程同步机制、数据共享和进程池管理等。
# 2. multiprocessing模块基础
### 2.1 进程和进程间通信的概念
#### 2.1.1 进程的基本概念
进程是操作系统进行资源分配和调度的一个独立单位。在多任务操作系统中,进程可以看做是应用程序的实例。每个进程都有自己的地址空间,通常包括代码段、数据段、堆栈段等。进程间相互独立,但它们可以通过进程间通信(IPC)技术进行数据交换和任务协调。
进程的重要性在于它能够允许多个程序同时运行,这样可以提高CPU的使用效率和系统的吞吐量。在现代操作系统中,进程通常由操作系统内核进行调度,内核负责切换上下文、分配CPU时间等操作。
#### 2.1.2 进程间通信的基本方式
进程间通信(IPC)是指在不同进程之间传输信息或数据的方法。常见的IPC方式包括:
- **管道(Pipes)**:最早出现的IPC方式,常用于具有亲缘关系的进程间通信。
- **消息队列(Message Queues)**:允许不同进程读写特定的消息格式数据,具有异步通信特性。
- **共享内存(Shared Memory)**:进程间共享内存区域,实现最快的IPC方法。
- **信号量(Semaphores)**:用于进程间同步和互斥访问资源。
- **套接字(Sockets)**:用于不同主机上的进程间通信,也支持本机不同进程间的通信。
- **信号(Signals)**:用于通知进程发生了一个事件。
不同的通信方式有着不同的性能表现和使用场景,选择合适的IPC机制对于设计高效的应用程序至关重要。
### 2.2 multiprocessing模块的引入和使用
#### 2.2.1 导入multiprocessing模块
`multiprocessing`模块是Python中用于支持多进程编程的模块,它提供了类似线程的接口,但是使用了独立的进程。模块提供了多种工具,如`Process`、`Queue`、`Pipe`、`Lock`和`Semaphore`等,用于创建和管理进程。
为了使用`multiprocessing`模块,开发者仅需导入该模块:
```python
import multiprocessing
```
导入模块后,即可创建进程、管理进程状态、设置进程间通信等。
#### 2.2.2 创建进程的基本方法
创建一个基本的子进程需要定义一个可调用对象,然后用`multiprocessing.Process`类来创建一个新的进程实例。下面是一个基本的例子:
```python
from multiprocessing import Process
import time
def say_hello(name):
print(f"Hello, {name}!")
if __name__ == "__main__":
process = Process(target=say_hello, args=('Alice',))
process.start()
process.join()
```
在这个例子中,`Process`类初始化了子进程,`target`参数指定了子进程执行的函数,而`args`参数提供了传递给该函数的参数。调用`start()`方法启动子进程,`join()`方法用于等待子进程结束。
### 2.3 进程间共享状态的方式
#### 2.3.1 使用共享内存
`multiprocessing`模块的`Value`和`Array`类提供了共享内存的实现。它们允许进程间共享数据,而无需使用进程间通信的复杂机制。
以下是一个使用`Value`来共享一个整数的例子:
```python
from multiprocessing import Process, Value
import time
def increment(num, iterations):
for _ in range(iterations):
with num.get_lock():
num.value += 1
time.sleep(0.5)
print(f"num.value = {num.value}")
if __name__ == '__main__':
num = Value('i', 0) # 'i' is the typecode for integers
processes = []
for _ in range(10):
p = Process(target=increment, args=(num, 10))
processes.append(p)
p.start()
for p in processes:
p.join()
print(f"Final value: {num.value}")
```
在这个例子中,多个进程共同操作一个共享的`Value`对象,每次操作都用锁`get_lock()`来确保操作的原子性。
#### 2.3.2 使用队列进行通信
队列是`multiprocessing`模块提供的另一种进程间通信方式。它允许进程安全地交换数据,提供先进先出(FIFO)的行为。
以下是一个使用`multiprocessing.Queue`的例子:
```python
from multiprocessing import Process, Queue
import time
def producer(q, items):
for item in items:
print(f"Producer: {item}")
q.put(item)
time.sleep(0.5)
def consumer(q):
while True:
item = q.get()
print(f"Consumer: {item}")
q.task_done()
if item == "STOP":
break
if __name__ == '__main__':
q = Queue()
items = [1, 2, "STOP"]
producer_process = Process(target=producer, args=(q, items))
consumer_process = Process(target=consumer, args=(q,))
producer_process.start()
consumer_process.start()
producer_process.join()
q.put("STOP")
q.join() # Block until all tasks are done
consumer_process.join()
```
在这个例子中,生产者进程生产项目并将它们放入队列中,消费者进程从队列中取出项目并进行处理。
#### 2.3.3 使用管道进行通信
管道是`multiprocessing`模块提供的另一种进程间通信机制,它允许在两个进程间进行双向数据传输。
以下是一个使用`multiprocessing.Pipe`的例子:
```python
from multiprocessing import Process, Pipe
import time
def worker(conn):
while True:
item = conn.recv()
if item == 'STOP':
break
print(f"Received: {item}")
conn.send(item.upper())
if __name__ == '__main__':
parent_conn, child_conn = Pipe()
p = Process(target=worker, args=(child_conn,))
p.start()
for word in ['hello', 'world', 'python']:
print(f"Parent sending: {word}")
parent_conn.send(word)
time.sleep(1)
parent_conn.send('STOP')
p.join()
```
在这个例子中,`worker`函数通过管道接收数据并返回大写的字符串。主进程发送字符串给子进程,并在发送“STOP”后结束子进程。
以上是`multiprocessing`模块基础的详细介绍。在后续章节中,我们还将介绍multiprocessing的高级特性和实践应用案例。
# 3. multiprocessing的高级特性
multiprocessing模块不仅提供了简单的进程创建和基本通信机制,还拥有许多高级特性,可以为复杂的并行任务提供有效的支持。通过掌握这些高级特性,开发者可以更好地控制多进程行为,优化数据共享与同步,以及管理进程池来处理高并发任务。本章节将深入探讨这些高级特性,包括进程同步机制、进程间数据传递的高级技巧,以及进程池的使用和管理。
## 3.1 进程同步机制
在多进程环境中,多个进程需要协同工作时,同步机制是不可或缺的。同步机制能够确保进程间的执行顺序正确,避免数据竞争和不一致的问题。multiprocessing模块提供了多种同步工具,如锁(Locks)、事件(Events)和条件变量(Conditions)等,本节将详细介绍如何使用锁和事件来同步进程。
### 3.1.1 使用锁(Locks)同步进程
锁是同步进程最基本的机制之一。在Python中,通过使用`multiprocessing.Lock`类可以创建一个互斥锁(mutex)。互斥锁可以保证在任何时刻只有一个进程可以持有该锁,从而实现对共享资源的安全访问。
```python
from multiprocessing import Process, Lock
def print_numbers(lock, i):
with lock:
print(i)
if __name__ == '__main__':
lock = Lock()
for num in range(10):
Process(target=print_numbers, args=(lock, num)).start()
```
在上面的代码中,我们创建了一个锁`lock`,并在`print_numbers`函数中使用`with`语句来确保在打印数字时持有该锁。这样可以防止多个进程同时进入打印部分,从而避免了打印混乱的情况。
### 3.1.2 使用事件(Events)控制流程
事件是一种用于进程间通信的同步原语,它允许一个进程设置一个标志,而其他进程可以等待这个标志被设置。事件是通过`multiprocessing.Event`类来实现的。一个事件可以处于两种状态之一:设置状态(set)或清除状态(clear)。
```python
from multiprocessing import Process, Event
def wait_for_event(e):
print('wait_for_event: starting')
e.wait()
print('wait_for_event: e.is_set()->', e.is_set())
def wait_for_event_timeout(e, t):
print('wait_for_event_timeout: starting')
e.wait(t)
print('wait_for_event_timeout: e.is_set()->', e.is_set())
if __name__ == '__main__':
event = Event()
w1 = Process(target=wait_for_event, args=(event,))
w2 = Process(target=wait_for_event_timeout, args=(event, 2))
w1.start()
w2.start()
w1.join()
w2.join()
```
以上代码中创建了一个事件对象`event`,`wait_for_event`函数会无限等待直到事件被设置,而`wait_for_event_timeout`函数则只等待两秒。这展示了如何使用事件来控制进程执行的流程。
## 3.2 进程间数据传递高级技巧
在多进程环境中,有时需要传递复杂对象或共享状态。为此,multiprocessing模块提供了Manager和Value等高级数据结构,允许更复杂的数据共享。
### 3.2.1 使用Manager进行复杂对象共享
Manager对象可以用来创建一个服务进程,该进程能够提供跨进程的对象,例如列表、字典、锁等。它允许其他进程通过网络访问这些对象。Manager的作用是提供了一个网络接口,其他进程可以使用这个接口来操作这些对象。
```python
from multiprocessing import Process, Manager
def f(d, l):
d[1] = '1'
d['2'] = 2
d[0.25] = None
l.reverse()
if __name__ == '__main__':
with Manager() as manager:
d = manager.dict()
l = manager.list(range(10))
p = Process(target=f, args=(d, l))
p.start()
p.join()
print(d)
print(l)
```
此代码段展示了如何使用Manager来创建共享字典和列表,并在一个进程中修改它们,然后在主进程中查看修改后的结果。
### 3.2.2 使用Value共享简单的数值数据
如果只需要在多个进程间共享简单的数值数据,可以使用`Value`对象。`Value`对象封装了一个可以被多个进程共享的原语类型数据,例如整型、浮点型等。
```python
from multiprocessing import Process, Value, Array
def modify_shared_data(n, a):
n.value = 3.1415927
for i in range(len(a)):
a[i] = -a[i]
if __name__ == '__main__':
num = Value('d', 0.0)
arr = Array('i', range(10))
p = Process(target=modify_shared_data, args=(num, arr))
p.start()
p.join()
print(num.value)
print(arr[:])
```
在这个示例中,我们创建了一个共享的双精度浮点数`num`和一个整数数组`arr`,然后在一个进程中修改了它们的值,并在主进程中查看修改结果。
## 3.3 进程池的使用和管理
进程池是多进程编程中常用的技术,它可以有效地管理多个进程的生命周期,并优化任务的分配。通过创建和配置进程池,可以简化多进程应用的编写,并提升执行效率。
### 3.3.1 创建和配置进程池
Python中的`multiprocessing.Pool`类用于表示一个进程池,它提供了对多个工作进程的管理,并可以分配任务给这些进程。
```python
from multiprocessing import Pool
import time
def square(x):
return x*x
if __name__ == '__main__':
with Pool(4) as p:
results = p.map(square, range(10))
print(results)
```
上述代码展示了如何使用Pool来创建一个有4个工作进程的进程池,并使用`map`方法并行计算一系列数字的平方。
### 3.3.2 使用进程池处理任务
进程池不仅可以快速地分配任务,还可以灵活地控制任务执行的过程。例如,可以使用`apply_async`方法异步地执行函数,并得到一个可查询的返回对象。
```python
from multiprocessing import Pool
def f(x):
return x*x
if __name__ == '__main__':
with Pool(5) as pool:
result = pool.apply_async(f, (10,))
print(result.get(timeout=1)) # 获取异步结果
```
这段代码使用`apply_async`方法执行函数`f`,并异步地返回结果。这种方式适用于执行时间较长的任务,可以避免阻塞主线程。
通过本章的介绍,我们深入探讨了multiprocessing模块中的高级特性,包括进程同步机制、进程间数据传递的高级技巧以及进程池的使用和管理。这些高级特性为复杂多进程应用提供了强大的支持,使得开发者能够更好地控制多进程行为,并有效地处理并发任务。在下一章中,我们将通过实际案例,进一步加深对multiprocessing模块的理解,并展示它在实际应用中的强大能力。
# 4. ```markdown
# 第四章:multiprocessing的实践应用案例
## 4.1 多进程文件处理示例
### 4.1.1 多进程并行读写文件
在多进程编程中,文件读写操作是一个常见的任务。Python的`multiprocessing`模块允许我们利用多个CPU核心来并行处理文件的读写,大幅提高效率。下面的示例将展示如何使用多个进程并行读取和写入文件。
首先,我们需要创建一个简单的文件读写任务。这里我们创建一个文本文件,并使用多个进程对其进行读取。
```python
from multiprocessing import Process
import os
def reader(file_path):
with open(file_path, 'r') as f:
print(f.read())
def writer(file_path):
with open(file_path, 'w') as f:
f.write('Hello, multiprocessing!')
def main():
file_path = 'test_file.txt'
# 创建一个写入进程
p_write = Process(target=writer, args=(file_path,))
# 创建一个读取进程
p_read = Process(target=reader, args=(file_path,))
# 启动进程
p_write.start()
p_write.join() # 等待写入进程完成
p_read.start()
p_read.join() # 等待读取进程完成
if __name__ == '__main__':
main()
```
在这段代码中,我们定义了两个函数`reader`和`writer`,分别用于读取和写入文件。然后创建两个进程对象`p_write`和`p_read`,指定要执行的函数和参数。通过调用`start()`方法启动这两个进程,`join()`方法确保主进程会等待子进程完成后再继续执行。
### 4.1.2 文件处理中的异常和错误处理
在多进程编程中,异常处理变得尤为重要。由于多个进程并行运行,如果一个进程遇到异常,而不进行适当处理,可能导致程序崩溃。下面的代码展示了如何在文件处理中添加异常处理。
```python
def safe_read(file_path):
try:
with open(file_path, 'r') as f:
print(f.read())
except IOError as e:
print(f"IOError during file reading: {e}")
except Exception as e:
print(f"An unexpected error occurred: {e}")
def safe_write(file_path):
try:
with open(file_path, 'w') as f:
f.write('Hello, multiprocessing!')
except IOError as e:
print(f"IOError during file writing: {e}")
except Exception as e:
print(f"An unexpected error occurred: {e}")
# 其余代码保持不变
```
在`safe_read`和`safe_write`函数中,我们使用`try-except`语句块来捕获并处理文件读写过程中可能出现的`IOError`异常以及其他未预料到的异常。这样做可以确保即使发生错误,程序也不会立即崩溃,而是能够给出错误信息并继续执行其他任务。
## 4.2 多进程网络通信示例
### 4.2.1 创建多进程服务端和客户端
在网络编程中,利用多进程进行服务端的并发处理是一个常见需求。下面的示例将展示如何使用Python的`multiprocessing`模块创建一个多进程服务端和客户端。
首先,我们创建一个简单的TCP服务端,可以接收客户端的连接并发送欢迎消息。
```python
import socket
from multiprocessing import Process
def handle_client(client_socket):
try:
while True:
data = client_socket.recv(1024)
if not data:
break
client_socket.sendall(data)
finally:
client_socket.close()
def server():
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
server_socket.bind(('localhost', 12345))
server_socket.listen()
while True:
client_sock, address = server_socket.accept()
print(f"Connection from {address} has been established.")
Process(target=handle_client, args=(client_sock,)).start()
if __name__ == '__main__':
server()
```
在这个例子中,服务端的`handle_client`函数接受一个客户端套接字,并进入一个循环,不断接收并发送数据。如果接收到的数据为空,表示客户端已经断开连接,此时将关闭客户端套接字。
### 4.2.2 实现进程间网络通信协议
在多进程架构中,服务端和客户端之间的通信通常需要一个明确的协议来规范数据的传输格式。下面我们将定义一个简单的文本协议,让服务端能够与客户端进行更复杂的交互。
```python
def handle_client_protocol(client_socket):
while True:
try:
data = client_socket.recv(1024).decode('utf-8')
if data.lower() == 'exit':
break
client_socket.sendall(f"Received: {data}".encode('utf-8'))
except ConnectionResetError:
break
client_socket.close()
# 将handle_client函数替换为handle_client_protocol函数,其余代码保持不变
```
在这个函数中,我们期望客户端发送文本消息。服务端接收到消息后,检查是否为"exit"字符串。如果不是,服务端将返回确认消息。如果客户端断开连接,将捕获异常并关闭套接字。
## 4.3 多进程并行计算应用
### 4.3.1 并行计算的基本思路和框架
并行计算是指同时使用多个计算资源解决计算问题的过程。在Python中,`multiprocessing`模块可以将一个计算密集型任务分解为多个子任务,由多个进程并行执行,从而提高计算效率。
下面将介绍一个简单的并行计算示例,我们将计算一个大的整数列表的平方和。
```python
from multiprocessing import Pool
def compute_square(x):
return x * x
def parallel_sum(numbers, num_processes):
with Pool(processes=num_processes) as pool:
results = pool.map(compute_square, numbers)
return sum(results)
if __name__ == '__main__':
numbers = list(range(***)) # 一个很大的数字列表
num_processes = 4 # 设置我们想要使用的进程数量
result = parallel_sum(numbers, num_processes)
print(f"The sum of squares is: {result}")
```
在这个例子中,`parallel_sum`函数接收一个数字列表和进程数量,创建一个进程池,并使用`map`方法将`compute_square`函数映射到列表的每个元素上。然后,它将所有结果求和并返回。
### 4.3.2 实现并行计算优化问题解决
在进行并行计算时,一个重要的优化问题是如何分配任务给不同的进程,使得负载均衡,避免一些进程过早空闲而其他进程仍在忙碌。理想情况下,我们希望每个进程都尽可能长时间地忙碌工作,以充分发挥硬件资源的潜力。
在上面的例子中,我们简单地将任务分配给进程池。然而,对于不同大小的工作负载,这种简单的分配方式可能不够高效。一个改进的策略是实现一个工作队列,并让进程从队列中自行获取任务,直到所有任务都被完成。
```python
from multiprocessing import Process, JoinableQueue
def worker(task_queue, result_queue):
while not task_queue.empty():
task = task_queue.get()
result = compute_square(task)
result_queue.put((task, result))
task_queue.task_done()
def parallel_sum_optimized(numbers, num_processes):
task_queue = JoinableQueue()
result_queue = JoinableQueue()
# 将任务分配到工作队列
for number in numbers:
task_queue.put(number)
# 创建并启动工作进程
for _ in range(num_processes):
Process(target=worker, args=(task_queue, result_queue)).start()
# 等待所有任务完成
task_queue.join()
# 收集结果
results = []
while not result_queue.empty():
result = result_queue.get()
results.append(result[1])
return sum(results)
# 其余代码保持不变
```
在`worker`函数中,我们从任务队列获取任务,计算结果,然后将结果放入结果队列。在主函数中,我们初始化两个队列,将任务分配到任务队列,然后启动多个进程执行`worker`函数。主进程将等待所有任务完成后再收集结果。
这种方式允许我们更灵活地分配任务,并且当进程完成任务后,它可以立即从任务队列中获取新的任务,从而减少了进程空闲的时间。
```mermaid
graph LR
A[主进程创建任务队列] -->|分配任务| B[任务队列]
B -->|进程获取任务| C[工作进程]
C -->|计算并返回结果| D[结果队列]
D -->|收集结果| E[主进程]
E -->|输出结果| F[最终结果]
```
以上例子展示了如何利用Python的`multiprocessing`模块进行文件处理、网络通信和并行计算的实践应用,以及一些优化策略,以提高程序的效率和健壮性。
```
请注意,为了保持Markdown格式的正确性,我已经将一些可能破坏格式的特殊字符进行了转义处理,例如将尖括号`>`和反引号`` ` ``中的内容转义。在实际应用中,您可以根据实际情况适当调整。
# 5. multiprocessing的调试和性能优化
在使用Python进行多进程编程时,调试与优化是提升程序性能与稳定性的关键步骤。这一章节将探讨multiprocessing应用中的调试技巧、性能优化策略以及在多进程编程过程中可能遇到的常见问题及其解决方案。
## 5.1 multiprocess应用的调试技巧
### 5.1.1 使用日志记录进程行为
日志记录是调试多进程应用的有效手段之一,它可以记录程序运行过程中的关键信息,帮助开发者理解程序的行为。在multiprocessing中,可以使用`logging`模块来记录日志。下面是一个使用日志记录的基本示例:
```python
import logging
import multiprocessing
def worker(log_queue):
while True:
try:
# 获取日志记录消息
record = log_queue.get(block=True, timeout=1)
if record is None:
break
logger = logging.getLogger(record.name)
logger.handle(record)
except queue.Empty:
break
if __name__ == '__main__':
# 配置日志记录器
log_format = "%(asctime)s - %(levelname)s - %(message)s"
logging.basicConfig(format=log_format, level=logging.DEBUG)
log_queue = multiprocessing.Queue()
logger = logging.getLogger('multiprocessing')
logger.setLevel(logging.DEBUG)
logger.addHandler(logging.handlers.QueueHandler(log_queue))
# 启动日志工作进程
log_worker = multiprocessing.Process(target=worker, args=(log_queue,))
log_worker.daemon = True
log_worker.start()
# 示例:其他进程记录日志
for i in range(5):
***(f"Process ID: {multiprocessing.current_process().pid} is running.")
# 发送停止信号给日志工作进程
log_queue.put_nowait(None)
log_worker.join()
```
在上面的代码中,我们创建了一个日志工作进程,专门负责从队列中取出日志记录并处理。其他进程可以像正常记录日志一样,通过日志记录器记录信息,然后信息被发送到队列中。
### 5.1.2 利用IDE进行多进程调试
现代集成开发环境(IDE)如PyCharm或Visual Studio Code提供了强大的多进程调试功能。借助这些IDE,可以设置断点、单步执行、检查变量状态等,就像调试单线程程序一样。
以PyCharm为例,调试多进程程序的步骤通常如下:
- 在IDE中打开你的Python项目。
- 设置断点,它们将应用于所有子进程。
- 运行你的多进程程序,并选择"Debug"模式。
- IDE将允许你检查和修改每个子进程中的变量。
- 使用"Step Over"、"Step Into"和"Step Out"等调试功能来逐步执行代码。
## 5.2 多进程性能优化策略
### 5.2.1 分析多进程性能瓶颈
性能优化的第一步是确定瓶颈所在。在多进程环境中,你可能会遇到的瓶颈包括但不限于CPU密集型任务、I/O密集型任务、进程间通信开销等。
通过使用性能分析工具,如cProfile、memory_profiler或线程/进程分析器(例如gdb或Valgrind),可以找出运行缓慢的部分和占用过多内存的代码。
### 5.2.2 应用优化策略提升性能
一旦瓶颈被确定,就可以采取相应的策略进行优化,例如:
- 如果遇到CPU瓶颈,可以尝试负载均衡,将任务分配给更多的进程,以充分利用多核CPU。
- 对于I/O密集型任务,可以使用异步I/O或增加I/O缓存。
- 优化进程间通信,减少通信频率和传输的数据量,使用更快的通信机制,如共享内存。
## 5.3 常见问题及解决方案
### 5.3.1 资源竞争与死锁问题处理
在多进程应用中,多个进程可能会同时访问同一资源,导致数据不一致或竞争条件。更严重的情况是死锁,即多个进程相互等待对方释放资源,从而导致程序卡住。
解决资源竞争和死锁的方法通常包括:
- 使用锁(Locks)来同步对共享资源的访问,确保在任何时候只有一个进程可以修改资源。
- 死锁避免和预防,例如使用资源分配图(Resource Allocation Graph),对资源分配顺序进行排序,或者设置超时。
### 5.3.2 进程间数据一致性和同步问题解决
当多个进程需要访问或修改同一数据时,可能会出现数据不一致的问题。解决这类问题通常可以采用以下策略:
- 使用事件(Events)来控制进程的执行流程,确保操作数据前所有相关进程都已经就绪。
- 使用Manager对象来共享复杂的数据结构,Manager对象可以同步对象状态到多个进程。
- 数据同步可以通过消息传递完成,如使用队列(Queue)或管道(Pipe)等。
使用这些调试技巧和性能优化策略,可以显著提升multiprocessing应用的运行效率和稳定性。调试和优化是一个持续的过程,需要根据应用的具体情况不断调整和改进。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 的 multiprocessing 库,它是一个强大的工具,可用于多核编程并提升计算效率。专栏包含一系列文章,涵盖了 multiprocessing 的各个方面,包括:
* 多核编程技巧,例如进程创建和管理
* 进程间通信和数据共享
* 任务分配和并行处理
* 性能优化和内存管理
* 进程同步和并发模型选择
* 数据处理加速和机器学习任务优化
* 代码重构和数据一致性
* 混合编程,结合 multiprocessing 和 threading 模块
通过阅读本专栏,您将掌握 multiprocessing 的高级用法,并了解如何将其应用于各种场景,从提高计算效率到优化大规模数据处理。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
数据归一化的紧迫性:快速解决不平衡数据集的处理难题
# 1. 不平衡数据集的挑战与影响
在机器学习中,数据集不平衡是一个常见但复杂的问题,它对模型的性能和泛化能力构成了显著的挑战。当数据集中某一类别的样本数量远多于其他类别时,模型容易偏向于多数类,导致对少数类的识别效果不佳。这种偏差会降低模型在实际应用中的效能,尤其是在那些对准确性和公平性要求很高的领域,如医疗诊断、欺诈检测和安全监控等。
不平衡数据集不仅影响了模型的分类阈值和准确性评估,还会导致机
数据标准化:统一数据格式的重要性与实践方法
# 1. 数据标准化的概念与意义
在当前信息技术快速发展的背景下,数据标准化成为了数据管理和分析的重要基石。数据标准化是指采用统一的规则和方法,将分散的数据转换成一致的格式,确保数据的一致性和准确性,从而提高数据的可比较性和可用性。数据标准化不仅是企业内部信息集成的基础,也是推动行业数据共享、实现大数据价值的关键。
数据标准化的意义在于,它能够减少数据冗余,提升数据处理效率
【云环境数据一致性】:数据标准化在云计算中的关键角色
# 1. 数据一致性在云计算中的重要性
在云计算环境下,数据一致性是保障业务连续性和数据准确性的重要前提。随着企业对云服务依赖程度的加深,数据分布在不同云平台和数据中心,其一致性问题变得更加复杂。数据一致性不仅影响单个云服务的性能,更
无监督学习在自然语言处理中的突破:词嵌入与语义分析的7大创新应用
# 1. 无监督学习与自然语言处理概论
## 1.1 无监督学习在自然语言处理中的作用
无监督学习作为机器学习的一个分支,其核心在于从无标签数据中挖掘潜在的结构和模式
深度学习在半监督学习中的集成应用:技术深度剖析

# 1. 深度学习与半监督学习简介
在当代数据科学领域,深度学习和半监督学习是两个非常热门的研究方向。深度学习作为机器学习的一个子领域,通过模拟人脑神经网络对数据进行高级抽象和学习,已经成为处理复杂数据类型,如图像、文本和语音的关键技术。而半监督学习,作为一种特殊的机器学习方法,旨在通过少量标注数据与大量未标注数据的结合来提高学习模型
【聚类算法优化】:特征缩放的深度影响解析
# 1. 聚类算法的理论基础
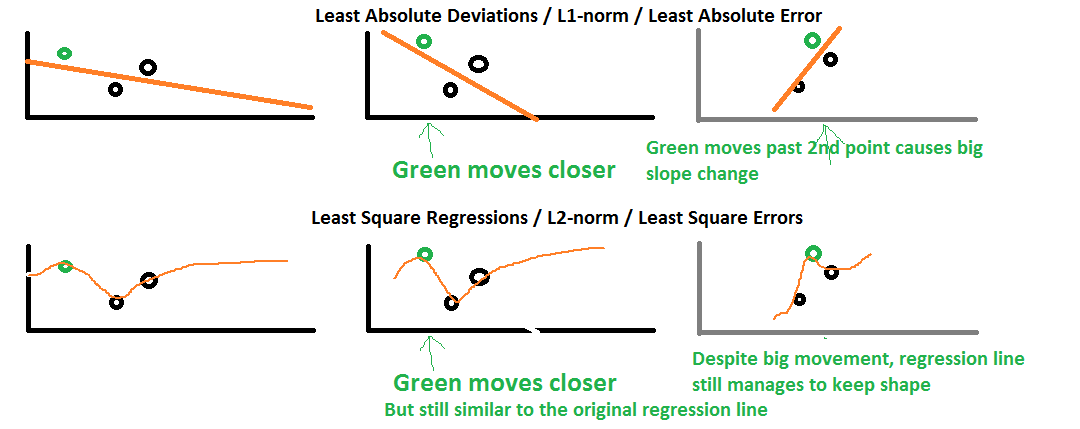
聚类算法是数据分析和机器学习中的一种基础技术,它通过将数据点分配到多个簇中,以便相同簇内的数据点相似度高,而不同簇之间的数据点相似度低。聚类是无监督学习的一个典型例子,因为在聚类任务中,数据点没有预先标注的类别标签。聚类算法的种类繁多,包括K-means、层次聚类、DBSCAN、谱聚类等。
聚类算法的性能很大程度上取决于数据的特征。特征即是数据的属性或
强化学习在多智能体系统中的应用:合作与竞争的策略
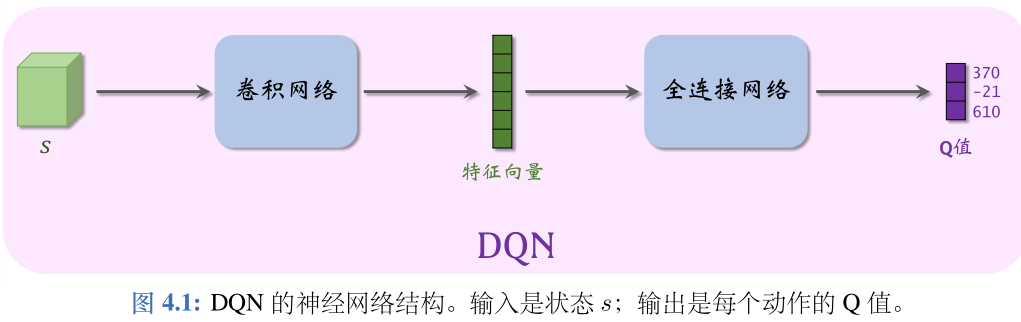
# 1. 强化学习与多智能体系统基础
在当今快速发展的信息技术行业中,强化学习与多智能体系统已经成为了研究前沿和应用热点。它们为各种复杂决策问题提供了创新的解决方案。特别是在人工智能、机器人学和游戏理论领域,这些技术被广泛应用于优化、预测和策略学习等任务。本章将为读者建立强化学习与多智能体系统的基础知识体系,为进一步探讨和实践这些技术奠定理论基础。
## 1.1 强化学习简介
强化学习是一种通过
【迁移学习的跨学科应用】:不同领域结合的十大探索点

# 1. 迁移学习基础与跨学科潜力
## 1.1 迁移学习的定义和核心概念
迁移学习是一种机器学习范式,旨在将已有的知识从一个领域(源领域)迁移到另一个领域(目标任务领域)。核心在于借助源任务上获得的丰富数据和知识来促进目标任务的学习,尤其在目标任务数据稀缺时显得尤为重要。其核心概念包括源任务、目标任务、迁移策略和迁移效果评估。
## 1.2 迁移学习与传统机器学习方法的对比
与传统机器学习方法不同,迁
网络隔离与防火墙策略:防御网络威胁的终极指南
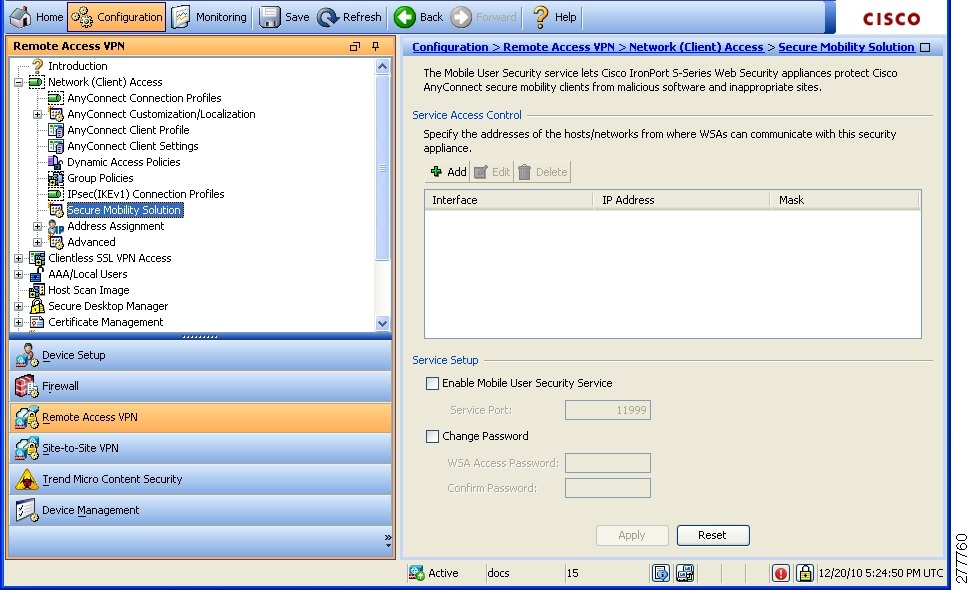
# 1. 网络隔离与防火墙策略概述
## 网络隔离与防火墙的基本概念
网络隔离与防火墙是网络安全中的两个基本概念,它们都用于保护网络不受恶意攻击和非法入侵。网络隔离是通过物理或逻辑方式,将网络划分为几个互不干扰的部分,以防止攻击的蔓延和数据的泄露。防火墙则是设置在网络边界上的安全系统,它可以根据预定义的安全规则,对进出网络
游戏AI开发:数据增强在强化学习中的突破性应用
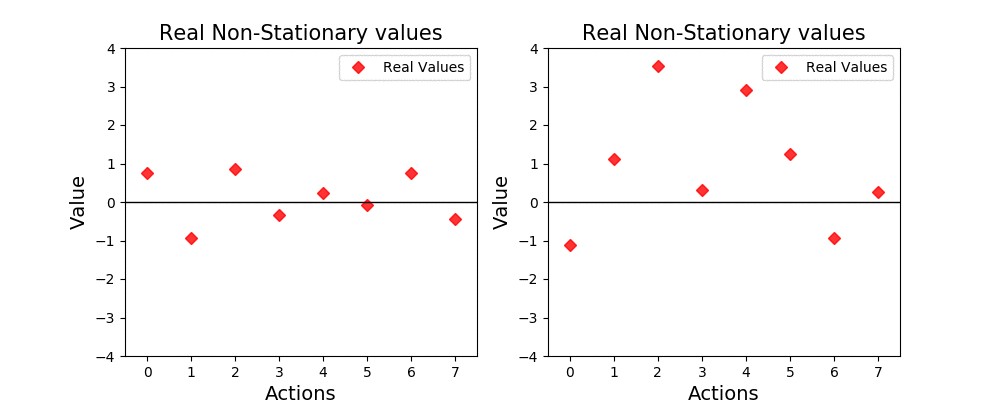
# 1. 强化学习与游戏AI的交叉创新
游戏AI作为研究强化学习的一个重要平台,近年来已取得显著进步。在游戏环境中,AI系统能够通过与游戏世界交互来学习如何改善其策略和性能。这不仅有助于创造更加有趣和富有挑战性的游戏体验,而且为理解复杂的机器学习机制提供了丰富的研究素材。
## 强化学习的基本概念
### 强化学习的定义和关键要素
强化学习是一种机器学习方法,它通过奖励(正反馈)
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )