【多核CPU并行计算】:multiprocessing实现真正的并行
发布时间: 2024-10-02 08:48:08 阅读量: 43 订阅数: 34 
# 1. 多核CPU并行计算基础
在现代计算领域,随着数据量的指数级增长,如何高效处理这些信息成了技术发展的重要方向。多核CPU并行计算作为一种提高处理速度和计算吞吐量的技术,正在变得越来越重要。本章将探讨并行计算的核心概念,为理解更复杂的多核处理技术打下坚实的基础。
## 1.1 多核计算的重要性
多核CPU处理器通过在同一芯片上集成多个核心,可以同时处理多个任务,极大提升了计算机的处理能力。与单核处理器相比,多核处理器在执行复杂计算任务时,如视频渲染、大数据分析、机器学习等,能够显著缩短执行时间,提高效率。
## 1.2 并行计算与多任务处理
并行计算是一种计算方法,它将一个大型计算任务分割成多个可以同时执行的小任务。与传统的多任务处理不同,后者是在同一时间内交错执行多个任务,而并行计算则允许同时运行多个计算过程,大幅减少总体完成时间。
## 1.3 并行计算的挑战
尽管并行计算带来了性能上的优势,但它也面临诸如线程管理、资源共享和同步问题等挑战。在多核环境下,这些挑战变得更加复杂,要求开发者具备高度的程序设计和优化能力。
在下一章节中,我们将深入探究Python的`multiprocessing`模块,它为多核并行计算提供了强大的支持,并通过各种机制解决了并行计算中遇到的许多常见问题。
# 2. multiprocessing模块概述
### 2.1 Python中的并行计算框架
#### 2.1.1 多线程与多进程的区别
Python中的多线程和多进程是实现并行计算的两种主要方式,它们在执行效率、资源共享和系统资源利用等方面存在本质的区别。多线程是在同一进程下执行多个线程,它们共享进程内存空间,因此通信开销小,但在Python这样的解释型语言中,由于全局解释器锁(GIL)的存在,同一时刻只有一个线程能执行Python字节码,这限制了多线程在CPU密集型任务上的并行效率。
多进程则是创建一个全新的进程,并将任务分配给这些独立的进程去完成。每个进程拥有自己的内存空间,因此需要通过进程间通信(IPC)来共享数据,这会带来较大的开销。然而,由于进程间的独立性,它们不受GIL的限制,可以在多核CPU上实现真正的并行计算。
#### 2.1.2 multiprocessing模块的引入
为了在Python中利用多核处理器的优势,人们开发了`multiprocessing`模块。该模块允许用户创建多个进程,并通过进程间通信机制来交换信息和结果。`multiprocessing`模块克服了线程的GIL限制,是并行计算的理想选择。
它提供了与`threading`模块类似但适用于进程的接口。其中包括用于创建进程的`Process`类、用于在进程间传递数据的`Queue`、`Pipe`类,以及用于同步进程行为的`Lock`、`Semaphore`等。
### 2.2 multiprocessing模块的核心组件
#### 2.2.1 Process类的使用
在`multiprocessing`模块中,`Process`类是创建新进程的工厂。它允许用户定义一个任务,然后通过一个进程实例来执行这个任务。与`threading.Thread`类似,`Process`可以被实例化,并通过调用`start()`方法来启动,最后通过`join()`方法等待进程结束。
```python
from multiprocessing import Process
def f(name):
print('hello', name)
if __name__ == '__main__':
p = Process(target=f, args=('bob',))
p.start()
p.join()
```
上面的例子中,定义了一个简单的任务`f`,它接收一个参数并打印出来。创建了一个`Process`对象`p`并传入目标函数`f`和参数`('bob',)`。调用`p.start()`启动进程,`p.join()`则等待进程结束。
#### 2.2.2 管理进程生命周期的方法
管理进程的生命周期包括启动进程、结束进程以及强制终止进程。`multiprocessing`模块提供了多种方法来控制这些生命周期。
- `start()`: 启动一个进程。
- `join(timeout=None)`: 等待进程结束,如果设置了`timeout`,则等待指定的时间。
- `terminate()`: 强制结束进程。
#### 2.2.3 同步和通信机制
进程间的同步和通信是`multiprocessing`模块的核心部分之一。由于每个进程有自己独立的地址空间,因此需要特定的机制来交换信息。`multiprocessing`模块提供了多种同步原语,如`Lock`、`Semaphore`、`Event`等来避免竞争条件和实现进程间的协调。
进程间通信(IPC)则可以通过`Queue`和`Pipe`来实现。`Queue`是一个线程和进程安全的队列,适合在生产者和消费者模型中使用。`Pipe`则提供了双工通信的管道。
### 2.3 实现并行计算的基本模式
#### 2.3.1 Process Pool的创建与应用
`ProcessPool`是`multiprocessing`模块中管理多个工作进程的高级接口。它允许用户提交任务给进程池,然后进程池会自动处理任务的分配和执行。
使用`ProcessPool`的典型方式是创建一个`ProcessPoolExecutor`实例,并使用它来提交可调用的对象。例如:
```python
from multiprocessing import ProcessPoolExecutor
def some_function(x):
return x*x
if __name__ == '__main__':
with ProcessPoolExecutor(max_workers=4) as executor:
results = [executor.submit(some_function, i) for i in range(5)]
for future in results:
print(future.result())
```
在这个例子中,我们创建了一个最多包含4个工作进程的进程池,并提交了5个任务。`ProcessPoolExecutor`负责分配任务给工作进程,收集任务结果并返回。
#### 2.3.2 线程安全的队列操作
在多进程环境中,`multiprocessing.Queue`是一个线程和进程安全的队列,它使用管道和锁机制来实现安全的数据交换。队列通常用于进程间的通信和任务的缓冲。
```python
from multiprocessing import Process, Queue
def f(q):
q.put([42, None, 'hello'])
if __name__ == '__main__':
q = Queue()
p = Process(target=f, args=(q,))
p.start()
print(q.get()) # prints "[42, None, 'hello']"
p.join()
```
这里演示了如何使用`Queue`在进程间传递数据。函数`f`将一个列表放入队列中,主进程通过`get`方法取出这个列表。
#### 2.3.3 共享状态的管理
在多进程中共享状态需要特别注意,因为直接共享内存是不可行的。`multiprocessing`模块提供了一些机制来实现状态共享,其中`Value`和`Array`是基于共享内存的同步原语,它们允许在多个进程之间共享数据。
```python
from multiprocessing import Value, Process
def modify_shared_value(shared_value):
with shared_value.get_lock():
shared_value.value += 1
if __name__ == '__main__':
num = Value('i', 0) # 'i' is short for c_int
for i in range(10):
Process(target=modify_shared_value, args=(num,)).start()
print(num.value)
```
上面的代码展示了如何使用`Value`来共享一个整数值。每个进程可以安全地修改这个值,因为`Value`对象提供了锁来保护数据。
在本章节中,我们介绍了`multiprocessing`模块的基本组件和使用方法,包括`Process`类的创建和管理、同步和通信机制,以及并行计算的基本模式。下一章将探讨如何将这些知识应用于实际的多核CPU并行计算实践中。
# 3. 多核CPU并行计算实践
## 3.1 计算密集型任务的并行处理
在处理计算密集型任务时,CPU密集型任务通常涉及大量数学计算,这些计算任务可以很好地分布在多核CPU上进行加速。并行计算不仅提高了处理速度,而且改善了用户体验。为了深入理解如何并行处理计算密集型任务,我们将探讨并行计算的启动和调度,以及进程同步和状态保存的处理。
### 3.1.1 并行计算的启动和调度
在Python中,我们可以使用`multiprocessing`模块来启动并行计算。我们创建多个进程,每个进程执行相同的任务或不同的任务。启动并行计算的一个基本模式是使用`Process`类来定义进程,然后通过调用`start()`方法启动每个进程。
```python
import multiprocessing
import time
def worker(n):
"""模拟计算密集型任务"""
for i in range(1000000):
pass
if __name__ == '__main__':
start_time = time.time()
p1 = multiprocessing.Process(target=worker, args=(1,))
p2 = multiprocessing.Process(target=worker, args=(2,))
p1.start()
p2.start()
p1.join()
p2.join()
print(f"Time taken: {time.time() - start_time}")
```
在上述代码中,我们定义了一个计算密集型的`worker`函数,并创建了两个进程`p1`和`p2`,每个进程调用该函数。通过调用`start()`,我们启动了这些进程,然后通过调用`join()`等待进程结束。
在并行计算的调度方面,每个CPU核心都将负责运行一个或

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 的 multiprocessing 库,它是一个强大的工具,可用于多核编程并提升计算效率。专栏包含一系列文章,涵盖了 multiprocessing 的各个方面,包括:
* 多核编程技巧,例如进程创建和管理
* 进程间通信和数据共享
* 任务分配和并行处理
* 性能优化和内存管理
* 进程同步和并发模型选择
* 数据处理加速和机器学习任务优化
* 代码重构和数据一致性
* 混合编程,结合 multiprocessing 和 threading 模块
通过阅读本专栏,您将掌握 multiprocessing 的高级用法,并了解如何将其应用于各种场景,从提高计算效率到优化大规模数据处理。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【MySQL大数据集成:融入大数据生态】
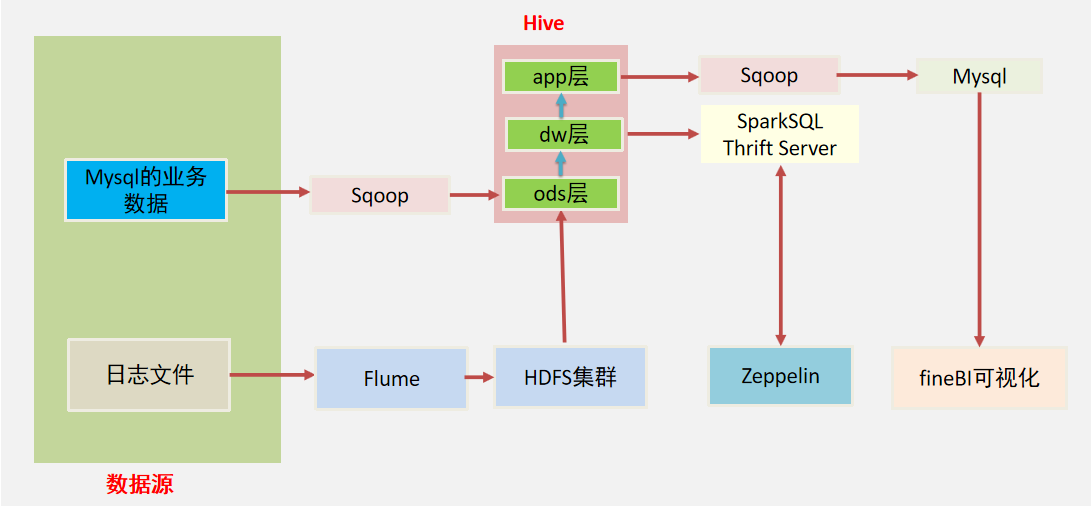
# 1. MySQL在大数据生态系统中的地位
在当今的大数据生态系统中,**MySQL** 作为一个历史悠久且广泛使用的关系型数据库管理系统,扮演着不可或缺的角色。随着数据量的爆炸式增长,MySQL 的地位不仅在于其稳定性和可靠性,更在于其在大数据技术栈中扮演的桥梁作用。它作为数据存储的基石,对于数据的查询、分析和处理起到了至关重要的作用。
## 2.1 数据集成的概念和重要性
数据集成是
移动优先与响应式设计:中南大学课程设计的新时代趋势

# 1. 移动优先与响应式设计的兴起
随着智能手机和平板电脑的普及,移动互联网已成为人们获取信息和沟通的主要方式。移动优先(Mobile First)与响应式设计(Responsive Design)的概念应运而生,迅速成为了现代Web设计的标准。移动优先强调优先考虑移动用户的体验和需求,而响应式设计则注重网站在不同屏幕尺寸和设
【数据库连接池管理】:高级指针技巧,优化数据库操作

# 1. 数据库连接池的概念与优势
数据库连接池是管理数据库连接复用的资源池,通过维护一定数量的数据库连接,以减少数据库连接的创建和销毁带来的性能开销。连接池的引入,不仅提高了数据库访问的效率,还降低了系统的资源消耗,尤其在高并发场景下,连接池的存在使得数据库能够更加稳定和高效地处理大量请求。对于IT行业专业人士来说,理解连接池的工作机制和优势,能够帮助他们设计出更加健壮的应用架构。
# 2. 数据库连
Rhapsody 7.0消息队列管理:确保消息传递的高可靠性

# 1. Rhapsody 7.0消息队列的基本概念
消息队列是应用程序之间异步通信的一种机制,它允许多个进程或系统通过预先定义的消息格式,将数据或者任务加入队列,供其他进程按顺序处理。Rhapsody 7.0作为一个企业级的消息队列解决方案,提供了可靠的消息传递、消息持久化和容错能力。开发者和系统管理员依赖于Rhapsody 7.0的消息队
【数据清洗与质量保证】:确保YOLO抽烟数据集纯净无瑕的策略

# 1. 数据清洗与质量保证的基本概念
数据清洗与质量保证是数据科学和机器学习项目中至关重要的环节。在处理现实世界的数据时,不可避免地会遇到数据缺失、错误和不一致性等问题。清洗数据的目的在于解决这些问题,以确保数据的质量,提高数据的可用性和准确性。本章节将深入浅出地介绍数据清洗和质量保证的基础知识,旨在为读者提供一个全面的概览和理解。
## 1.1 数据清洗的定义
提高计算机系统稳定性:可靠性与容错的深度探讨
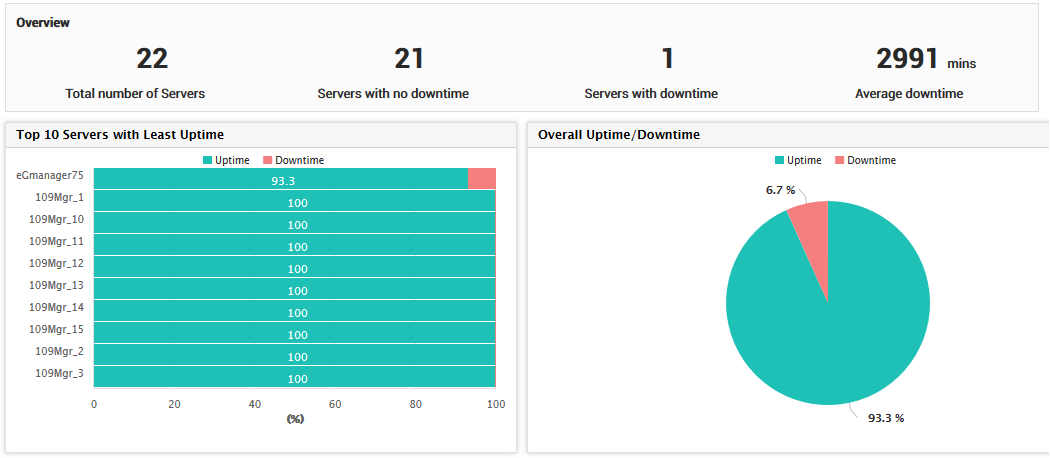
# 1. 计算机系统稳定性的基本概念
计算机系统稳定性是衡量一个系统能够持续无故障运行时间的指标,它直接关系到用户的体验和业务的连续性。在本章中,我们将介绍稳定性的一些基本概念,比如系统故障、可靠性和可用性。我们将定义这些术语并解释它们在系统设计中的重要性。
系统稳定性通常由几个关键指标来衡量,包括:
- **故障率(MTB
Java中JsonPath与Jackson的混合使用技巧:无缝数据转换与处理

# 1. JSON数据处理概述
JSON(JavaScript Object Notation)数据格式因其轻量级、易于阅读和编写、跨平台特性等优点,成为了现代网络通信中数据交换的首选格式。作为开发者,理解和掌握JSON数
微信小程序登录后端日志分析与监控:Python管理指南
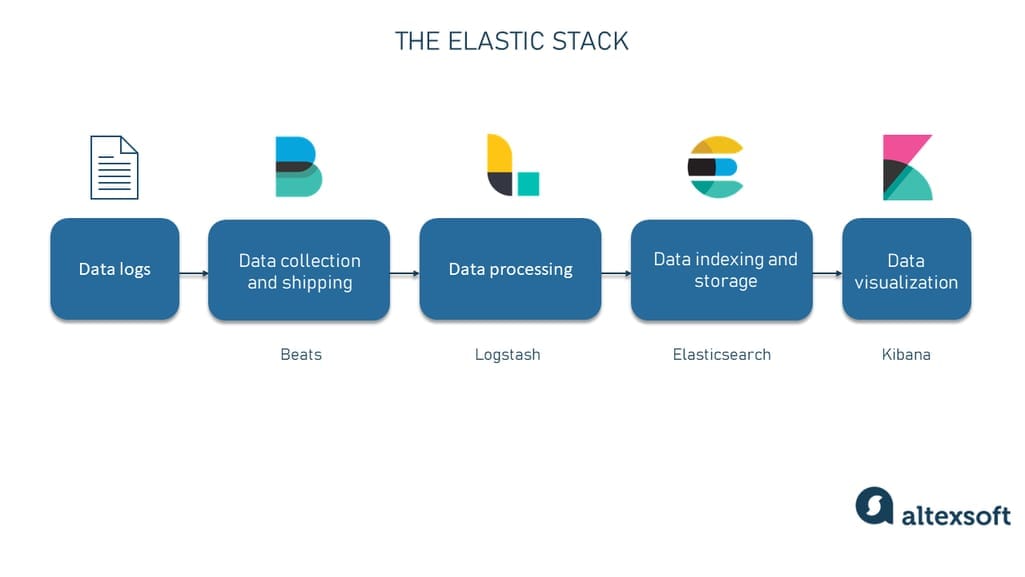
# 1. 微信小程序后端日志管理基础
## 1.1 日志管理的重要性
日志记录是软件开发和系统维护不可或缺的部分,它能帮助开发者了解软件运行状态,快速定位问题,优化性能,同时对于安全问题的追踪也至关重要。微信小程序后端的日志管理,虽然在功能和规模上可能不如大型企业应用复杂,但它在保障小程序稳定运行和用户体验方面发挥着基石作用。
## 1.2 微
【数据分片技术】:实现在线音乐系统数据库的负载均衡
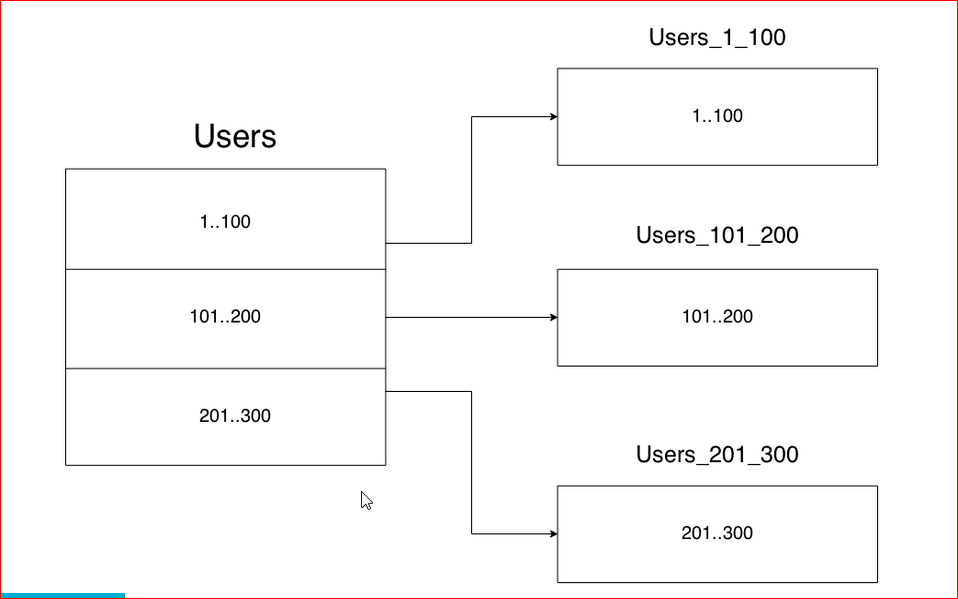
# 1. 数据分片技术概述
## 1.1 数据分片技术的作用
数据分片技术在现代IT架构中扮演着至关重要的角色。它将大型数据库或数据集切分为更小、更易于管理和访问的部分,这些部分被称为“分片”。分片可以优化性能,提高系统的可扩展性和稳定性,同时也是实现负载均衡和高可用性的关键手段。
## 1.2 数据分片的多样性与适用场景
数据分片的策略多种多样,常见的包括垂直分片和水平分片。垂直分片将数据
Java中间件服务治理实践:Dubbo在大规模服务治理中的应用与技巧
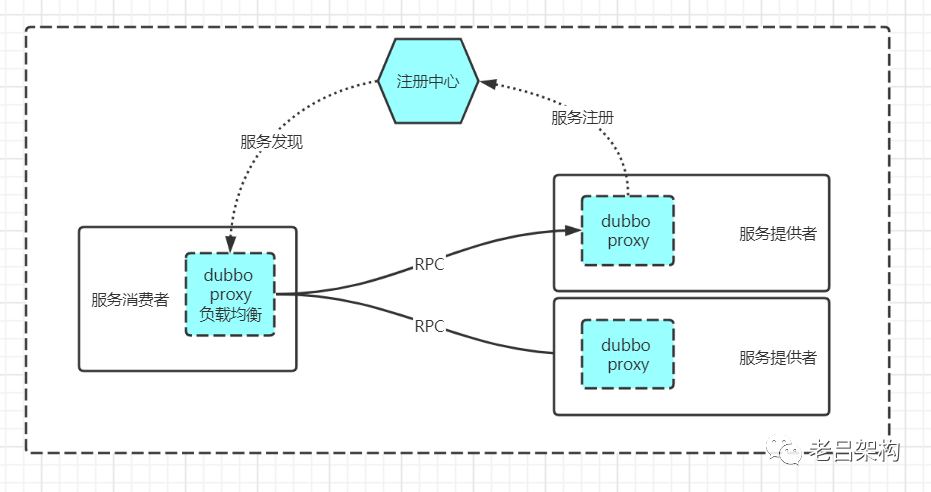
# 1. Dubbo框架概述及服务治理基础
## Dubbo框架的前世今生
Apache Dubbo 是一个高性能的Java RPC框架,起源于阿里巴巴的内部项目Dubbo。在2011年被捐赠给Apache,随后成为了Apache的顶级项目。它的设计目标是高性能、轻量级、基于Java语言开发的SOA服务框架,使得应用可以在不同服务间实现远程方法调用。随着微服务架构
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )