【速度提升秘诀】:MapReduce数据压缩的关键角色
发布时间: 2024-10-27 08:33:08 阅读量: 24 订阅数: 29 

大数据实验5实验报告:MapReduce 初级编程实践
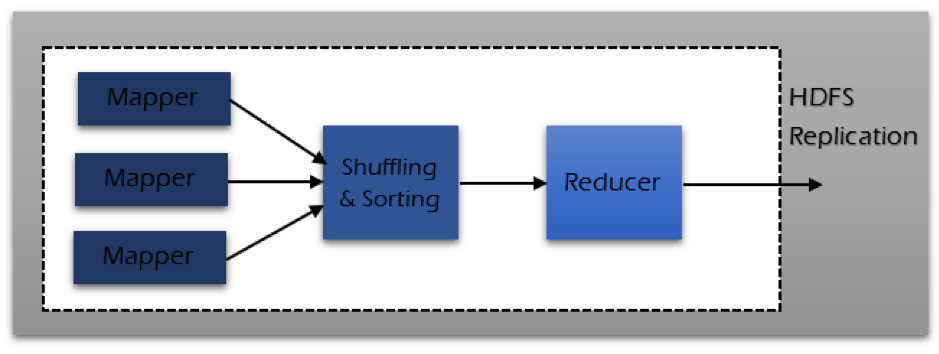
# 1. MapReduce数据处理模型概述
MapReduce是一种编程模型,用于大规模数据集的并行运算,是大数据处理的基石。它将复杂的、分布式的计算过程简化为两个主要操作:Map和Reduce。
## 1.1 MapReduce的基本概念
MapReduce的工作流程包括Map阶段和Reduce阶段。在Map阶段,系统会处理输入数据,生成一系列的中间键值对;Reduce阶段则对这些键值对进行合并操作,输出最终结果。
## 1.2 MapReduce的运行原理
MapReduce模型运行时,首先将输入数据分割为固定大小的块,每个块由一个Map任务处理。Map任务将输入数据处理成键值对,这些键值对再被分配给Reduce任务进行汇总处理。最终,这些数据被归约成最终的输出结果。
## 1.3 MapReduce的应用场景
MapReduce适用于日志文件分析、大规模数据集排序、倒排索引构建等场景。它允许开发者通过抽象的接口处理大量数据,无需关注底层的分布式细节。
```python
# 示例代码:使用Hadoop的MapReduce框架实现单词计数
from mrjob.job import MRJob
class MRWordCount(MRJob):
def mapper(self, key, line):
for word in line.split():
yield (word, 1)
def combiner(self, word, counts):
yield (word, sum(counts))
def reducer(self, word, counts):
yield (word, sum(counts))
if __name__ == '__main__':
MRWordCount.run()
```
这个例子展示了如何使用Python编写的MapReduce程序实现简单的单词计数功能。理解了这一章节的内容,读者将掌握MapReduce的核心概念,并能够理解其在数据处理中的重要性。
# 2. MapReduce数据压缩理论基础
数据压缩在MapReduce数据处理模型中扮演着至关重要的角色。它不仅能够提升数据处理的效率,还能显著降低存储和网络传输过程中的成本。本章将深入探讨数据压缩的基础理论、常见的数据压缩技术,以及压缩对MapReduce性能的影响。
## 2.1 数据压缩的基本概念
### 2.1.1 压缩比和压缩效率
压缩比是指压缩后的数据大小与原始数据大小之间的比例。通常表示为原始数据大小除以压缩后数据大小。一个高压缩比意味着原始数据被有效减小,这有助于节省存储空间和加速数据传输。然而,压缩比并不是唯一衡量压缩技术好坏的标准。压缩效率是另一个重要指标,它反映了压缩和解压缩过程中的时间消耗和系统资源使用情况。一个理想的压缩技术应当提供高压缩比的同时,保持高效率的压缩和解压缩速度。
### 2.1.2 压缩算法分类
数据压缩算法可以分为两大类:无损压缩和有损压缩。无损压缩算法保证了数据压缩和解压缩之后的完全一致性,不丢失任何原始信息。这对于需要确保数据完整性的应用场景非常重要,如文档存储和日志文件处理。有损压缩算法则允许在压缩过程中损失一些原始数据的信息,以换取更高的压缩比,通常用于多媒体数据,比如音频、图像和视频文件。
## 2.2 常见数据压缩技术
### 2.2.1 无损压缩算法原理
无损压缩算法包括Huffman编码、LZ77、LZ78、Deflate以及BWT(Burrows-Wheeler Transform)等。这些算法通过不同的数据结构和编码机制来识别和消除数据中的冗余。例如,Huffman编码基于字符出现频率构建最优二叉树来实现变长编码,而LZ系列算法通过查找重复的字符串模式来减少数据的冗余。Deflate算法结合了Huffman编码和LZ77算法的特点,用于PNG图像和GZIP文件压缩。BWT通过字符排序,为进一步的压缩提供良好的输入。
### 2.2.2 有损压缩算法原理
有损压缩算法的例子包括JPEG、MPEG和MP3等。JPEG压缩算法通过减少图像中颜色数据的精度和采用有损色彩转换算法来达到压缩效果。MPEG压缩视频数据时,利用了时间冗余和空间冗余,并通过减少帧率或分辨率来实现高压缩比。MP3压缩音频数据通过人耳感知的限制,仅保留对听觉重要的频率成分,丢弃对人耳影响不大的频率成分。有损压缩技术在保证基本质量的前提下,大幅提高了数据的压缩效率。
## 2.3 压缩对MapReduce性能的影响
### 2.3.1 压缩前的数据处理流程
在MapReduce中,未压缩的数据从HDFS(Hadoop分布式文件系统)读取,然后通过Map任务进行处理。这个过程中,HDFS需要传输大量的数据到各个节点,这可能会成为性能瓶颈,尤其是在处理大规模数据集时。而且,未压缩的数据对存储空间的需求更大,这会增加存储成本。
### 2.3.2 压缩后的数据处理流程
当数据被压缩后,传输和存储的开销都大幅减少。这意味着MapReduce框架能够在更短的时间内读取所需数据,并将处理结果写入HDFS。然而,压缩技术也会带来额外的CPU消耗,因为压缩和解压缩需要处理计算。因此,合适的压缩算法选择以及参数配置是平衡这些因素的关键。
为了进一步说明,以下是一个示例表格,展示了未压缩与压缩数据处理的性能对比:
| 数据处理阶段 | 未压缩数据处理开销 | 压缩数据处理开销 | 性能差异说明 |
|--------------|---------------------|-------------------|--------------|
| 数据读取 | 高(大I/O吞吐量) | 低(小I/O吞吐量) | 压缩数据减小I/O负担 |
| 数据传输 | 高(网络带宽消耗大) | 低(带宽消耗小) | 减少网络拥堵 |
| 存储空间 | 大(占用更多磁盘) | 小(节省磁盘空间) | 降低存储成本 |
| CPU资源 | 低(压缩任务少) | 高(需要执行压缩解压) | 处理压缩解压任务 |
通过比较可以看出,虽然压缩数据对存储和网络传输十分有益,但同时会增加对计算资源的需求。在实际部署中,必须权衡这些因素,选择适当的压缩技术。
接下来,我们将通过具体的代码块来分析一个简单的无损压缩算法LZ77的实现逻辑:
```python
import io
import zlib
# 示例字符串
text = "Example data to demonstrate the concept of compression."
# 字符串的字节表示
data = text.encode('utf-8')
# 使用zlib进行压缩
compressed_data = ***press(data)
print(f"Original size: {len(data)} bytes")
print(f"Compressed size: {len(compressed_data)} bytes")
# 解压缩
decompressed_data = zlib.decompress(compressed_data)
assert data == decompressed_data
```
该代码块中,我们首先将一个字符串进行字节转换,然后使用zlib库的`compress`方法进行压缩。压缩后的数据大小显示在控制台,接着使用`decompress`方法恢复原始数据,以验证压缩的正确性。压缩算法的效率和压缩比可以通过比较压缩前后的字节大小得出。
```mermaid
flowchart LR
A[开始压缩] --> B[读取数据]
B --> C[压缩算法处理]
C --> D[压缩数据输出]
D --> E[存储压缩数据]
E --> F[读取压缩数据]
F --> G[解压缩算法处理]
G --> H[恢复原始数据]
H --> I[结束]
```
上述流程图展示了数据压缩和解压缩的整个流程。从开始到结束,每个步骤都涉及到不同的处理阶段,每一个阶段都有其特定的性能开销。
通过深入理解数据压缩的理论基础,我们可以更加明智地选择和应用适合特定需求的压缩技术,以此优化MapReduce作业的性能。在下一章节中,我们将探讨如何在MapReduce中应用这些压缩技术,并分享一些实用的实践技巧。
# 3. MapReduce中数据压缩的实践技巧
MapReduce框架在处理大数据集时,数据压缩可以显著减少I/O操作的开销,提升处理速度和效率。本章节将探讨在MapReduce中如何选择和应用数据压缩技术,并深入分析压缩在Map和Reduce阶段的具体应用场景。
## 3.1 MapReduce压缩技术的选择与应用
在MapReduce作业中,选择合适的压缩技术能够优化性能并节约资源。以下是对如何进行压缩技术选择和应用的详细讲解。
### 3.1.1 压缩技术与数据类型匹配
选择适合的数据压缩技术需要考虑数据的特性和压缩后的使用场景。例如:
- 文本数据通常采用Gzip、Bzip2或Snappy等无损压缩算法。
- 多媒体数据(如图像、音频、视频)则可能更适合使用有损压缩算法,如JPEG或MP3。
- 在需要高压缩比的场景下,可以考虑使用列式存储结合压缩技术,例如Parquet或ORC格式。
### 3.1.2 压缩技术对任务性能的影响
不同的压缩技术对计算和内存资源的消耗各不相同,需要根据任务的具体要求和集群的能力进行选择。通常,压缩会引入额外的CPU计算开销,但在网络传输和存储上会节省大量资源。需要根据实际应用场景权衡压缩带来的收益和消耗。
## 3.2 压缩在Map阶段的应用
在Map阶段,输入数据的压缩与解压缩以及Map任务输出数据的压缩策略是提升效率的关键。
### 3.2.1 输入数据的压缩与解压缩

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏《MapReduce数据压缩解析》深入探讨了MapReduce框架中数据压缩的技术和应用。它涵盖了初学者指南、数据压缩黑科技、Hadoop集群优化、压缩算法对比、压缩格式选择、性能优化、数据安全、网络传输优化、大数据瓶颈解决方案、全方位解析、进阶攻略、常见问题解答、教程、资源管理影响、效率与成本权衡、速度提升秘诀以及最新技术趋势。通过深入浅出的讲解和丰富的案例研究,专栏旨在帮助读者全面掌握MapReduce数据压缩,提升大数据处理效率和性能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
揭秘漫画巨头的秘密:快看漫画、腾讯动漫与哔哩哔哩漫画的终极对决

# 摘要
本文探讨了中国漫画市场的崛起及发展,重点分析了快看漫画、腾讯动漫和哔哩哔哩漫画三大平台的战略布局、用户体验创新、商业模式和技术应用。通过对各自平台定位、内容开发、社区文化和用户互动等方面的深入剖析,揭示了它们在竞争激烈的市场环境中如何构建自身优势,并应对挑战。此外,文章还对新兴技术如人工智能、虚拟现实等在漫画行业中的应用进行了展望,同时讨论了行业趋势、版权问题和国际合作所带来的机遇与
通过差分编码技术改善数据同步问题:专家指南与案例分析

# 摘要
差分编码技术是一种在数据同步和传输领域广泛使用的技术,它通过记录数据变化而非全量数据来提高效率。本文首先概述了差分编码技术的发展历程和基本原理,包括其在数据同步中的关键问题解决和核心机制。然后,本文分析了差分编码技术在不同领域的实践应用,如数据库和分布式系统,并探讨了算法实现和性能评估。进一步深入探讨了差分编码的变种、改进方向以及遇到的理论与实践挑战,并提供了应对策略。最后,通过案例研究总结了差分编码
ASAP3协议下的数据压缩技术:减少带宽消耗的有效方法
# 摘要
随着数据量的爆炸式增长,数据压缩技术变得日益重要,尤其是在要求高效数据传输的ASAP3协议中。本文首先概述了ASAP3协议及其数据压缩需求,随后介绍了数据压缩的基础理论和技术,包括无损与有损压缩算法及其性能评估。在ASAP3协议的实际应用中,本文探讨了数据流特性,实施了针对性的数据压缩策略,并优化了算法参数以平衡系统性能与压缩效果。案例研究部分通过实际环境下的测试和集成部署,展示了压缩技术在ASAP3协议中的有效应用,并提
系统需求变更确认书模板V1.1版:变更冲突处理的艺术
# 摘要
本文旨在探讨变更需求确认书在变更管理过程中的理论基础和实际应用。首先概述了变更管理流程及其关键阶段,随后深入分析了变更过程中可能产生的各类冲突,包括技术、组织和项目层面,并讨论了这些冲突对项目进度、成本和质量的影响。文章进一步提出了一系列变更冲突处理策略,包
【机器学习框架实战】:图像识别新境界:使用SVM实现高效识别

# 摘要
随着机器学习技术的快速发展,图像识别领域取得显著进步,其中支持向量机(SVM)作为一种有效的分类器,在图像识别中占据了重要位置。本文首先介绍机器学习与图像识别的基本概念,随后深入探讨SVM的理论基础,包括其核心思想、数学模型、优化问题以及参数选择与性能评估方法。接着,文中阐述了在进行图像识别前的准备工作,如图像数据的预处理和特征提取,并讨论了SVM在图像识别中的
【汇川PLC高级应用秘籍】:解锁H5U&Easy系列高级指令与功能扩展

# 摘要
本论文详细介绍了汇川PLC的基础知识,特别是H5U&Easy系列的特点。通过对高级指令的深入解析和应用案例分析,本文不仅提供了核心指令的结构分类和参数用法,还探讨了实现复杂逻辑控制和高效数据处理的方法。在功能扩展方面,本文阐述了如何利用软硬件模块进行拓展,并指导了自定义指令开发的流程。通过实践案例分析,本文还分享了故障排查的技巧。最后,论文展望了PLC编程的未来趋势,
构建公平薪酬体系的秘诀:IT报酬管理核心要素等级点数公式详解
# 摘要
本文深入探讨了薪酬体系的设计原则、核心要素以及实际应用案例,旨在阐述如何构建一个公平、合理的薪酬结构。首先,概述了薪酬体系的基本概念和公平性原则。接着,详细分析了薪酬管理的三大核心要素——岗位价值评估、员工绩效考核和市场薪酬调研,并探讨了这些要素在实际操作中的应用方法。第三章则围绕等级点数公式的理论基础与设计实践展开,包括其工作原理和在薪酬体系中的应用。第四章通过IT行业的薪酬体系设计案例和优化案例,提供了实际构建薪酬体系的深入分析。最后一章展望了薪酬管理面临的挑战与未来发展趋势,尤其关注了新兴技术的应用和员工福利体系的创新。
# 关键字
薪酬体系;公平性原则;岗位价值评估;绩效考
【广和通4G模块案例研究】:AT指令在远程监控中的应用
# 摘要
本文深入探讨了AT指令在远程监控领域中的应用,从基础指令集概述到高级功能实现,详细论述了AT指令在远程监控设备通信中的角色和实施策略。特别针对广和通4G模块的特性、数据采集、远程控制、固件升级和安全机制等方面进行了案例分析,展现了AT指令在实现复杂远程监控任务中的实践效果和应用潜力。文中不仅分析了当前的应用现状,还展望了物联网
WAVE6000性能监控与调整:系统稳定运行的保障
# 摘要
本文深入探讨了WAVE6000性能监控的理论与实践,从性能监控的理论基础到监控实践操作,再到深入的性能调整策略,全面分析了WAVE6000的性能监控和调整过程。本研究首先介绍了性能监控的重要性,包括系统稳定性的定义、影响因素及性能监控在系统维护中的作用。接着,详细阐述了WAVE6000的关键性能指标解析和性能监控工具的使用。在实践操作章节中,讨论了监控工具的安装配置、实时性能数据
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )