无人机目标检测模型评估指南:5个关键指标与实用方法
发布时间: 2024-12-15 19:47:31 阅读量: 2 订阅数: 3 

参考资源链接:[无人机目标检测与跟踪:UAVDT数据集详解](https://wenku.csdn.net/doc/5v0ohz7igv?spm=1055.2635.3001.10343)
# 1. 无人机目标检测模型概览
无人机目标检测是计算机视觉技术在空中监测领域的应用之一。模型需要能够准确地识别和定位无人机在图像中的目标,这通常涉及到对象检测技术的发展。目标检测技术经历了从传统图像处理方法到深度学习技术的转变。深度学习模型如YOLO、SSD、Faster R-CNN等已广泛应用于无人机目标检测领域,它们利用卷积神经网络(CNN)提取图像特征,实现实时和准确的目标识别。
接下来,让我们深入了解无人机目标检测模型评估指标的理论基础,这对于理解模型性能至关重要。
# 2. 评估指标的理论基础
在评估无人机目标检测模型的性能时,评估指标起到至关重要的作用。它们不仅帮助研究人员衡量模型的有效性,也为模型优化提供了指导。本章将深入探讨检测精度与误差分析、速度与资源消耗评估、可靠性与泛化能力这三个关键评估指标的理论基础。
### 2.1 检测精度与误差分析
#### 2.1.1 真正例、假正例、真负例、假负例
在目标检测中,我们通常会遇到四种基本类型的错误分类情况:真正例(True Positive, TP)、假正例(False Positive, FP)、真负例(True Negative, TN)、假负例(False Negative, FN)。这些概念来源于混淆矩阵,如下所示:
| 预测\真实 | 正例 | 反例 |
|-----------|------|------|
| 正例 | TP | FP |
| 反例 | FN | TN |
- **真正例(TP)**:模型正确识别出的目标。
- **假正例(FP)**:模型错误地将非目标判定为目标。
- **真负例(TN)**:模型正确识别出的非目标。
- **假负例(FN)**:模型错误地将目标判定为非目标。
精确地识别这些情况对于评估模型的检测性能至关重要。
#### 2.1.2 精确度、召回率和F1分数
在理解了上述概念之后,我们可以进一步探讨用于衡量检测性能的三个关键指标:精确度(Precision)、召回率(Recall)和F1分数(F1 Score)。
- **精确度(Precision)**:表示模型识别出的正例中真正的正例所占的比例。
\[ Precision = \frac{TP}{TP + FP} \]
- **召回率(Recall)**:表示所有实际为正例的样本中,模型正确识别出来的比例。
\[ Recall = \frac{TP}{TP + FN} \]
- **F1分数(F1 Score)**:是精确度和召回率的调和平均值,用于平衡二者。
\[ F1 Score = 2 \times \frac{Precision \times Recall}{Precision + Recall} \]
在实际应用中,通常需要在精确度和召回率之间进行权衡。高精确度意味着模型很少误报,而高召回率则意味着模型很少漏报。
### 2.2 速度与资源消耗评估
#### 2.2.1 每秒帧数(FPS)和推理时间
在实时应用,如无人机目标检测中,模型的响应速度非常关键。我们通常通过每秒帧数(Frames Per Second, FPS)来衡量模型的实时性能。FPS越高,模型处理图像的速度就越快,实时性能越好。此外,推理时间(Inference Time)是衡量模型处理单个图像所需时间的指标。计算公式如下:
\[ FPS = \frac{1}{Inference Time} \]
其中,Inference Time通常以秒为单位。
#### 2.2.2 模型大小和硬件要求
模型的大小(以兆字节MB或千兆字节GB计算)和硬件要求也是衡量目标检测模型的重要指标。较小的模型可以减少存储和带宽需求,而对硬件要求较低的模型可以在不具备高端GPU的设备上运行。对于资源受限的无人机系统,这尤为重要。
### 2.3 可靠性与泛化能力
#### 2.3.1 不同环境下的性能对比
无人机通常在多种环境下运行,包括不同的天气条件、光照情况等。因此,评估模型在不同环境下的性能至关重要。可靠性测试包括但不限于:
- **多天气测试**:在雨、雪、雾等不同天气条件下测试模型的性能。
- **昼夜测试**:评估模型在不同光照条件下的检测能力。
#### 2.3.2 模型对抗攻击的鲁棒性
对抗样本是一种特殊类型的输入,它被故意设计来欺骗目标检测模型,导致错误的检测。研究模型对抗攻击的鲁棒性有助于确保模型在恶意攻击下的可靠性。常用的对抗攻击方法包括添加小幅度的干扰(如噪声)、修改图像的像素值等。
通过以上评估指标的理论基础,我们可以更深入地理解无人机目标检测模型的性能评估。接下来的章节将探讨评估方法与实践操作,以及如何应用这些理论知识进行模型评估与优化。
# 3. 评估方法与实践操作
在本章节中,我们将深入探讨评估方法和实践操作。具体来说,本章内容将涵盖如何准备和标注数据集、设计实验以及执行基准测试,并最终完成结果分析和评估报告的撰写。为了确保内容的深入性和实用性,我们将重点关注实际操作的步骤,提供代码示例、工具使用说明和数据分析方法。
## 3.1 数据集的准备与标注
评估目标检测模型的首要步骤是准备和标注一个高质量的数据集。数据集的选择和标注质量直接影响模型训练的效果和评估的准确性。
### 3.1.1 数据集的选择标准
在选择数据集时,需要考虑以下几个关键标准:
- **代表性**:数据集应包含足够多的样本,能够代表实际应用中可能遇到的各种场景和条件。
- **多样性**:包括不同光照条件、天气状况、目标大小和角度等。
- **标注质量**:高质量的标注包括准确的目标边界框和类别标签,对于提升模型性能至关重要。
- **规模**:根据模型复杂性和评估目的的不同,所需数据集的规模也会有所不同。
### 3.1.2 标注工具与流程
在标注数据集时,选择合适的工具可以提高工作效率。目前流行的标注工具有LabelImg、CVAT等。以下是使用LabelImg进行数据集标注的基本流程:
1. **下载并安装LabelImg**:
可以从[GitHub](https://github.com/tzutalin/labelImg)下载LabelImg,支持Windows、Linux和MacOS平台。
2. **加载数据集**:
打开LabelImg,选择数据集目录,载入待标注的图片。
3. **进行标注**:
使用LabelImg工具进行对象的边界框标注,选择相应的类别,并保存标注结果。
4. **转换标注格式**:
通常目标检测模型需要特定格式的标注文件,如VOC、YOLO或COCO格式。LabelImg支持导出为Pascal VOC格式。
5. **验证标注结果**:
为了确保标注质量,需要对标注结果进行审核,确保标注的准确性和一致性。
示例代码展示如何使用LabelImg进行标注:
```python
# 以下为使用LabelImg的标注流程伪代码
import labelImg
# 启动LabelImg应用程序
app = labelImg.app()
# 载入数据集
app.load_dataset('path/to/dataset')
# 标注图片
app.start_labeling()
# 转换标注格式并保存
app.convert_voc_to_coco()
```
使用LabelImg进行标注不仅可以提高效率,还可以通过工具提供的界面和快捷键操作来提高标注的准确性。
## 3.2 实验设计与基准测试
在准备好的数据集上,我们设计实验并进行基准测试,以全面评估模型性能。
### 3.2.1 实验参数设置与控制变量法
实验参数的设置对于评估结果的准确性和可信度至关重要。必须遵循以下原则:
- **明确变量**:实验设计中应明确哪些参数是变量,哪些是固定值。
- **控制变量法**:确保在比较不同模型或模型的不同配置时,其他条件保持不变。
使用控制变量法可以有效地隔离和评估单一变量对结果的影响。例如,在比较不同学习率对模型性能的影响时,其他训练参数(如批次大小、优化器等)应保持不变。
### 3.2.2 模型性能的交叉验证
交叉验证是评估模型泛化能力的重要技术。它通过将数据集分割成多个小块,并使用其中一块作为验证集,其余作为训练集进行训练和验证,从而减少过拟合的风险。
在目标检测任务中,通常使用k折交叉验证,其中k取值为5或10较为常见。
伪代码示例:
```python
from sklearn.model_selection import KFold
# 假设x为特征数据集,y为目标标签
kf = KFo
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
揭秘音频数据的神秘面纱:Sonic Visualiser深度应用与高级技巧
参考资源链接:[Sonic Visualiser新手指南:详尽功能解析与实用技巧](https://wenku.csdn.net/doc/r1addgbr7h?spm=1055.2635.3001.10343)
# 1. 音频数据解析与Sonic Visualiser简介
音频数据解析是数字信号处理领域的一个重要分支,涉
ST-Link V2 原理图解读:从入门到精通的6大技巧
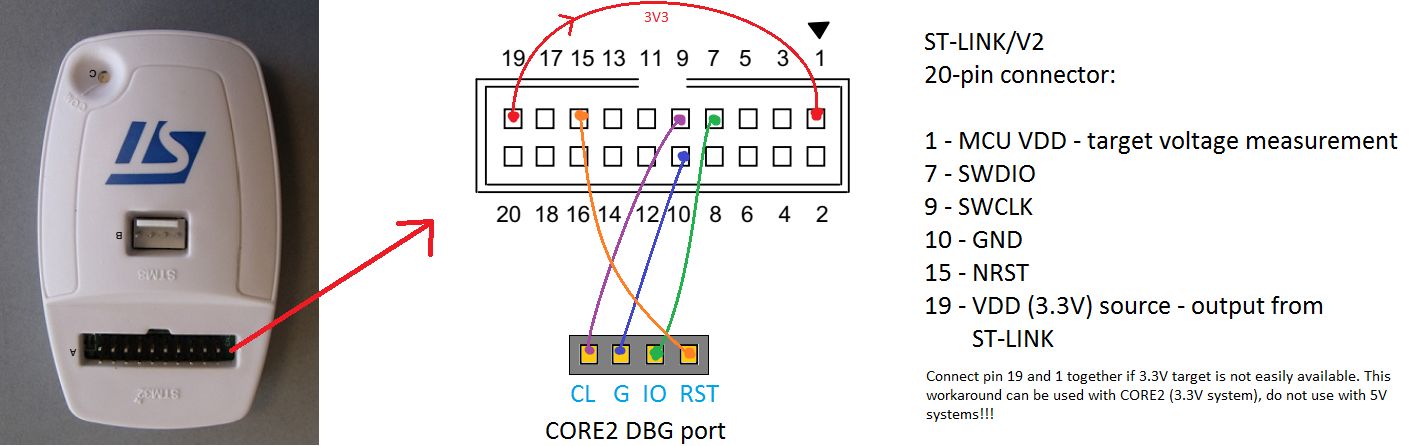
参考资源链接:[STLink V2原理图详解:构建STM32调试下载器](https://wenku.csdn.net/doc/646c5fd5d12cbe7ec3e52906?spm=1055.2635.3001.10343)
# 1. ST-Link V2简介与基础应用
ST-Link V2是一种广泛使用的调试器/编
Cognex VisionPro 标定流程优化攻略:8个秘诀帮你提升效率与准确性
参考资源链接:[Cognex VisionPro视觉标定流程详解:从九点标定到旋转中心计算](https://wenku.csdn.net/doc/6401abe0cce7214c316e9d24?spm=1055.2635.3001.10343)
# 1. Cognex VisionPro 标定流程概述
在现代工业自动化和计算机视觉领域中,准确的标定是至关重要的,它确保了系统可以正确理
【IEC62055-41数据交换全解】:智能电表通信的STS单程通信分析

参考资源链接:[IEC62055-41标准传输规范(STS).单程令牌载波系统的应用层协议.doc](https://wenku.csdn.net/doc/6401ad0ecce7214c316ee1f8?spm=1055.2635.3001.10343)
# 1. IEC62055-41标准概述
## 1.1 IEC62055-41标准
【WPF摄像头应用性能优化】:MediaKit实践中的8个关键提升点
参考资源链接:[WPF使用MediaKit调用摄像头](https://wenku.csdn.net/doc/647d456b543f84448829bbfc?spm=1055.2635.3001.10343)
# 1. WPF摄像头应用性能优化概述
在当今数字时代,视频捕获和处理是许多软件应用的核心部分,尤其是对于WPF(Windows Presentation Foun
逼真3D效果的秘密:Geomagic Studio高级渲染技术
参考资源链接:[GeomagicStudio全方位操作教程:逆向工程与建模宝典](https://wenku.csdn.net/doc/6z60butf22?spm=1055.2635.3001.10343)
# 1. Geomagic Studio渲染技术概述
Geomagic Studio是一款被广泛使用的3D扫描和建模软件,其强大的渲
深度学习革新:NVIDIA Ampere架构的AI训练优化攻略

参考资源链接:[NVIDIA Ampere架构白皮书:A100 Tensor Core GPU详解与优势](https://wenku.csdn
用友U8备份策略灵活性:如何制定可扩展的备份计划
参考资源链接:[用友U8自动备份失效解决方案全攻略](https://wenku.csdn.net/doc/2h5qv6x3e0?spm=1055.2635.3001.10343)
# 1. 用友U8备份策略概述
在当今信息化时代,企业数据的完整性和安全性已经成为企业竞争力的重要组成部分。用友U8作为一款广泛应用于企业资源规划(ERP)的软件,其数据备份工作显得尤为重要。本章将从整体上对用友U
提升燃料电池仿真精度:ANSYS Fluent参数调整与案例分析
参考资源链接:[ANSYS_Fluent_15.0_燃料电池模块手册(en).pdf](https://wenku.csdn.net/doc/64619ad4543f844488937562?spm=1055.2635.3001.10343)
# 1. 燃料电池仿真概述
燃料电池作为清洁能源技术的核心设备之一,其性能与效率的提升对环境可持续
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )