【预处理关键步骤】:数据标准化与归一化的全面解析
发布时间: 2024-09-07 17:45:48 阅读量: 148 订阅数: 44 

数据清洗与预处理:构建可靠的分析数据集.md

# 1. 数据预处理概述
在当今以数据驱动决策的IT领域,数据分析与模型训练的核心环节之一就是数据预处理。数据预处理是在数据分析前对原始数据进行清洗、转换和格式化的过程。其目的是为了提高数据质量,从而使得后续的分析和模型训练更加准确和高效。
在这一过程中,数据可能来自不同的渠道,包含不同的特征和数据类型,因此其一致性和可用性可能参差不齐。为了保证模型性能,通常需要经过以下步骤:
1. **数据清洗**:识别并处理数据集中的噪声和异常值。
2. **数据集成**:合并多个数据源中的数据。
3. **数据变换**:通过应用数学函数或算法将数据转换成模型所需的格式。
4. **数据规约**:减少数据的大小,同时保持数据的完整性。
通过这些步骤,数据预处理不仅为数据分析和建模打下坚实基础,而且直接关系到最终模型的性能和准确性。接下来的章节将详细介绍数据预处理的几种关键技术和实践方法。
# 2. 数据标准化的理论与实践
### 2.1 数据标准化的基本概念
数据标准化是数据预处理的重要组成部分,目的是为了消除不同量纲的影响,让数据在统一的尺度上进行比较和分析。这一过程对于许多数据驱动的算法至关重要,尤其是对于那些依赖于距离计算的算法,如聚类分析、主成分分析(PCA)和神经网络等。
#### 2.1.1 标准化的目的与意义
标准化通过转换数据,使得不同特征的数值能够在同一量级上进行比较。这对于基于距离的算法尤其重要,因为如果变量的量级不同,那么它们对距离的贡献也会不同,这可能导致算法结果的偏差。例如,在使用k均值聚类算法时,如果一个变量的范围远大于另一个变量,那么范围较大的变量将主导聚类结果,这显然是不合理的。通过标准化处理,每个变量都对结果有相同的影响力,从而能够得到更为公正和准确的分析结果。
#### 2.1.2 常见的数据标准化方法
数据标准化有几种常见方法,其中最著名的是Z-score标准化和最小-最大标准化。Z-score标准化(也称为标准分标准化)通过减去数据的均值,然后除以标准差,将数据转换为标准正态分布。最小-最大标准化则是将原始数据缩放至指定的范围,通常是0到1之间,通过计算每个数据点与最小值的差,并除以最大值与最小值的差实现。
### 2.2 Z-score标准化方法
#### 2.2.1 Z-score的计算原理
Z-score标准化是通过以下公式实现的:
\[ Z = \frac{(X - \mu)}{\sigma} \]
其中,\( X \)是原始数据点,\( \mu \)是数据集的均值,\( \sigma \)是数据集的标准差。这种方法的目的是将数据分布转换为具有均值为0和标准差为1的分布。在实际应用中,Z-score标准化非常有用,因为它不仅将数据标准化到标准正态分布,还保留了数据中的异常值信息。
#### 2.2.2 Z-score的实践应用案例
例如,假设我们有一个包含学生考试分数的数据集,分数范围在0到100之间。如果我们使用Z-score标准化方法,每个学生的分数将会转换为一个新的值,表示该分数与平均分的距离。如果一个学生得到85分,而平均分数是50分,标准差是10分,那么该学生的Z-score为3.5(\( \frac{(85-50)}{10} \))。这个转换后的值可以被用于进一步的分析,比如区分表现良好的学生和表现差的学生。
### 2.3 最小-最大标准化方法
#### 2.3.1 最小-最大标准化原理
最小-最大标准化是通过以下公式实现的:
\[ X_{\text{norm}} = \frac{(X - X_{\text{min}})}{(X_{\text{max}} - X_{\text{min}})} \]
其中,\( X \)是原始数据点,\( X_{\text{min}} \)和\( X_{\text{max}} \)分别是数据集中的最小值和最大值。这种标准化方法将数据集中的所有值都转换到[0,1]的范围内,使得数据更加统一,便于进行比较和分析。这种方法的一个显著优势是保留了数据中的异常值信息,但是对异常值非常敏感。
#### 2.3.2 最小-最大标准化的应用实例
以一个数据集为例,我们可能拥有一个城市的天气温度记录,温度范围在-20°C到40°C之间。通过最小-最大标准化,我们可以将温度数据转换到一个统一的尺度上。例如,如果我们有今天城市的温度是25°C,而记录中的最低温度是-10°C,最高温度是45°C,那么经过最小-最大标准化后,今天的温度转换为0.56(\( \frac{(25 - (-10))}{(45 - (-10))} \))。这样的转换对于比较不同城市的温度数据十分有用,尤其是在考虑到不同城市的温度范围可能差异很大的情况下。
接下来的章节将继续探讨数据归一化的方法,并通过实践案例分析,进一步理解数据预处理在数据分析和机器学习中的应用。
# 3. 数据归一化的理论与实践
数据归一化是数据预处理的重要环节,其作用是将特征缩放到一个标准的数值范围内,以消除不同量纲带来的影响,并提高算法的学习效率和模型的性能。本章将详细介绍数据归一化的概念、常用方法,并通过案例和实际应用场景,使读者能够深入理解并掌握数据归一化技术。
## 3.1 数据归一化的基本概念
### 3.1.1 归一化的定义和作用
归一化是指将数据按照比例进行缩放,使之落入一个小的特定区间。在机器学习和深度学习中,归一化的作用体现在多个方面:
1. 加速模型训练过程:归一化后的数据可以减少模型训练时的收敛时间。
2. 避免数值计算问题:归一化有助于防止因为数值差异大而导致的计算不稳定。
3. 提升模型性能:对于某些算法(如基于梯度的优化算法),归一化可以提高学习速度和性能。
### 3.1.2 归一化的常用方法
数据归一化的常用方法包括:
- 最小-最大归一化(Min-Max Normalization)
- L1范数归一化
- L2范数归一化
- 小批量归一化(Batch Normalization)
在本章中,我们将详细探讨L1和L2范数归一化以及小批量归一化处理。
## 3.2 L1和L2范数归一化
### 3.2.1 L1和L2范数的概念
L1范数和L2范数是两种常用的向量范数,它们在数据归一化中有着不同的应用场景。
- L1范数是向量元素绝对值的和,适用于特征稀疏化,即保留数据集中的主要特征。
- L2范数是向量元素的平方和的平方根,它使得数据在欧几里得空间中呈现为一个球面,常用于数据点的平滑化处理。
### 3.2.2 L1和L2范数在数据归一化中的应用
#### 代码块展示L1范数归一化
```python
import numpy as np
# 示例数据
X = np.array([[1, 2], [3, 4], [5, 6]])
# L1范数归一化
X_l1 = X / np.sum(np.abs(X), axis=0)
print("L1范数归一化后的数据:")
print(X_l1)
```
在上述代码中,我们首先导入numpy库,然后创建一个简单的二维数组。通过计算数组中每一列元素的绝对值和,再除以该列元素的绝对值和,得到了L1范数归一化后的数据。
#### 代码块展示L2范数归一化
```python
# L2范数归一化
X_l2 = X / np.linalg.norm(X, axis=0)
print("L2范数归一化后的数据:")
print(X_l2)
```
在L2范数归一化中,我们使用numpy的`linalg.norm`函数计算了数组每列的L2范数,然后通过将原数据数组除以范数值,得到了归一化的结果。
### 参数说明与逻辑分析
- `np.sum(np.abs(X), axis=0)`:计算每列的绝对值和。
- `np.linalg.norm(X, axis=0)`:计算每列的L2范数。
- `X / ...`:将原数组`X`与范数归一化,确保归一化后的数值满足特定的范数要求。
通过这些步骤,我们能够将数据集归一化到L1和L2范数指定的范围内,以满足后续模型训练的需求。
## 3.3 小批量归一化处理
### 3.3.1 小批量归一化的理论基础
小批量归一化(Batch Normalization)是一种在深度学习中常用的归一化技术。它通过在每层的输入上应用归一化,使得网络中数据分布更加稳定。小批量归一化通常在训练过程中进行,能够减轻梯度消失或梯度爆炸的问题,并允许使用更高的学习率。
### 3.3.2 实际应用中的小批量归一化策略
小批量归一化可以大大加快模型的收敛速度,以下是小批量归一化在实际应用中的策略:
1. 对于每一个小批量数据,计算其均值和方差。
2. 根据均值和方差调整数据,使其均值为0,方差为1。
3. 应用两个可学习的参数向量对归一化数据进行缩放和平移,以保持表达能力。
4. 在训练中使用小批量数据进行这些计算,并在推理时使用所有训练数据来估计均值和方差。
#### 表格展示小批量归一化流程
| 步骤 | 描述 | 作用 |
| --- | --- | --- |
| 1 | 计算每个特征的小批量均值和方差 | 确定当前小批量数据的统计特性 |
| 2 | 对数据进行归一化处理 | 确保数据在0均值附近,单位方差 |
| 3 | 通过可学习的参数进行

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
台达触摸屏宏编程:入门到精通的21天速成指南

# 摘要
本文系统地介绍了台达触摸屏宏编程的全面知识体系,从基础环境设置到高级应用实践,为触摸屏编程提供了详尽的指导。首先概述了宏编程的概念和触摸屏环境的搭建,然后深入探讨了宏编程语言的基础知识、宏指令和控制逻辑的实现。接下来,文章介绍了宏编程实践中的输入输出操作、数据处理以及与外部设备的交互技巧。进阶应用部分覆盖了高级功能开发、与PLC的通信以及故障诊断与调试。最后,通过项目案例实战,展现了如何将理论知识应用
信号完整性不再难:FET1.1设计实践揭秘如何在QFP48 MTT中实现

# 摘要
本文综合探讨了信号完整性在高速电路设计中的基础理论及应用。首先介绍信号完整性核心概念和关键影响因素,然后着重分析QFP48封装对信号完整性的作用及其在MTT技术中的应用。文中进一步探讨了FET1.1设计方法论及其在QFP48封装设计中的实践和优化策略。通过案例研究,本文展示了FET1.1在实际工程应用中的效果,并总结了相关设计经验。最后,文章展望了FET
【MATLAB M_map地图投影选择】:理论与实践的完美结合
:no_upscale()/cdn.vox-cdn.com/uploads/chorus_asset/file/3470884/1024px-Robinson_projection_SW.0.jpg)
# 摘要
M_map工具包是一种在MATLAB环境下使用的地图投影软件,提供了丰富的地图投影方法与定制选项,用
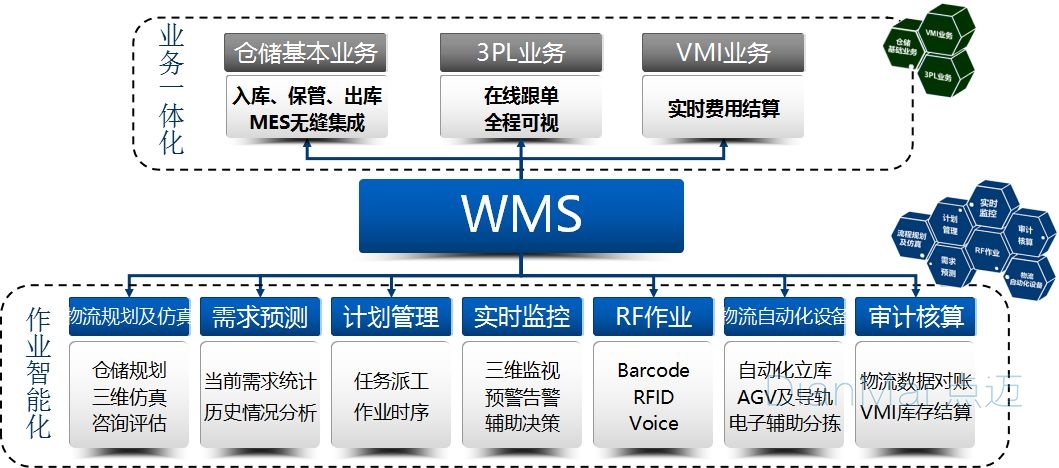
打造数据驱动决策:Proton-WMS报表自定义与分析教程
# 摘要
本文旨在全面介绍Proton-WMS报表系统的设计、自定义、实践操作、深入应用以及优化与系统集成。首先概述了报表系统的基本概念和架构,随后详细探讨了报表自定义的理论基础与实际操作,包括报表的设计理论、结构解析、参数与过滤器的配置。第三章深入到报表的实践操作,包括创建过程中的模板选择、字段格式设置、样式与交互设计,以及数据钻取与切片分析的技术。第四章讨论了报表分析的高级方法,如何进行大数据分析,以及报表的自动化
【DELPHI图像旋转技术深度解析】:从理论到实践的12个关键点

# 摘要
图像旋转是数字图像处理领域的一项关键技术,它在图像分析和编辑中扮演着重要角色。本文详细介绍了图像旋转技术的基本概念、数学原理、算法实现,以及在特定软件环境(如DELPHI)中的应用。通过对二维图像变换、旋转角度和中心以及插值方法的分析
RM69330 vs 竞争对手:深度对比分析与最佳应用场景揭秘

# 摘要
本文全面比较了RM69330与市场上其它竞争产品,深入分析了RM69330的技术规格和功能特性。通过核心性能参数对比、功能特性分析以及兼容性和生态系统支持的探讨,本文揭示了RM69330在多个行业中的应用潜力,包括消费电子、工业自动化和医疗健康设备。行业案例与应用场景分析部分着重探讨了RM69330在实际使用中的表现和效益。文章还对RM69330的市场表现进行了评估,并提供了应
无线信号信噪比(SNR)测试:揭示信号质量的秘密武器!
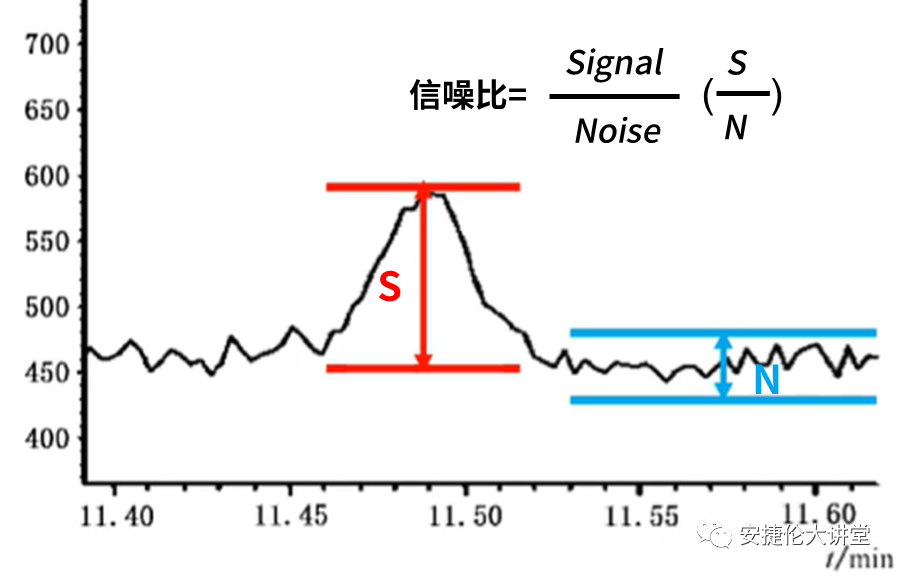
# 摘要
无线信号信噪比(SNR)是衡量无线通信系统性能的关键参数,直接影响信号质量和系统容量。本文系统地介绍了SNR的基础理论、测量技术和测试实践,探讨了SNR与无线通信系统性能的关联,特别是在天线设计和5G技术中的应用。通过分析实际测试案例,本文阐述了信噪比测试在无线网络优化中的重要作用,并对信噪比测试未来的技术发展趋势和挑战进行
【UML图表深度应用】:Rose工具拓展与现代UML工具的兼容性探索
# 摘要
本文系统地介绍了统一建模语言(UML)图表的理论基础及其在软件工程中的重要性,并对经典的Rose工具与现代UML工具进行了深入探讨和比较。文章首先回顾了UML图表的理论基础,强调了其在软件设计中的核心作用。接着,重点分析了Rose工具的安装、配置、操作以及在UML图表设计中的应用。随后,本文转向现代UML工具,阐释其在设计和配置方面的
台达PLC与HMI整合之道:WPLSoft界面设计与数据交互秘笈
# 摘要
本文旨在提供台达PLC与HMI交互的深入指南,涵盖了从基础界面设计到高级功能实现的全面内容。首先介绍了WPLSoft界面设计的基础知识,包括界面元素的创建与布局以及动态数据的绑定和显示。随后深入探讨了WPLSoft的高级界面功能,如人机交互元素的应用、数据库与HMI的数据交互以及脚本与事件驱动编程。第四章重点介绍了PLC与HMI之间的数据交互进阶知识,包括PLC程序设计基础、
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )