Python高级技巧:探索token模块的持久化存储与pickle关系
发布时间: 2024-10-11 03:02:47 阅读量: 90 订阅数: 40 

JS提示:Uncaught SyntaxError:Unexpected token ) 错误的解决方法

# 1. Python token模块简介
在现代软件系统中,令牌(token)是实现安全访问控制和身份验证的重要机制。Python作为一门功能强大的编程语言,在其标准库中提供了token处理的相关模块,这些模块极大地简化了开发人员对于安全认证系统的构建。
在本章中,我们将对Python标准库中的token模块进行基本的介绍,并探讨其在安全领域中的一般应用场景。随后,我们将深入讲解如何使用这些模块来生成和验证安全令牌,以及如何处理与之相关的各种问题。我们将通过一些简单的代码示例,向读者展示token的生成、使用和管理流程。
Python中的token模块,不仅涉及到令牌的生成和验证,还包括了令牌的存储、管理以及与之相关的安全策略。我们将从最基本的概念出发,带领读者逐步理解token模块的结构及其使用方法,为后续章节中关于token持久化存储机制的讨论打下坚实的基础。
# 2. token的持久化存储机制
## 2.1 Python中的持久化存储概念
### 2.1.1 持久化存储的需求和重要性
在IT行业中,持久化存储是一个至关重要的概念,它指的是将数据永久性地保存在非易失性存储介质上,以便在计算机系统关闭后数据依然能够被访问和使用。对于token而言,持久化存储尤其重要,因为它涉及到用户身份验证和访问控制。如果没有稳定的存储机制,用户在进行安全登录后,他们可能无法保持会话的连续性,或者在服务器重启后无法继续访问。此外,持久化存储机制允许系统在多个请求之间保存和检索token信息,这对于状态的维护和安全控制至关重要。
### 2.1.2 常见的数据持久化方式比较
在选择适合token的持久化存储方案时,通常会有几种常见的选择,包括文件系统、数据库以及分布式存储等。文件系统是最基础的方式,它简单易用,但可能不适合大规模或高并发场景。数据库提供了结构化存储能力,并且能够很好地支持复杂查询和事务管理,是许多应用的首选。分布式存储则在高可用性和扩展性方面表现出色,适合大规模分布式系统的需求。选择合适的存储方式,需要根据应用场景、数据规模和性能要求来综合考量。
## 2.2 token持久化存储的实现
### 2.2.1 文件系统在持久化中的应用
Python提供了丰富的文件操作接口,可利用文件系统实现token的持久化存储。在文件系统中,token可以被存储为简单的文本文件,也可以被序列化成特定格式(如JSON或pickle)后再保存。以下是使用Python进行文件持久化的基础代码块,其中包含了打开文件、写入token信息和关闭文件的操作:
```python
import json
def save_token_to_file(filename, token):
with open(filename, 'w') as ***
* 将token序列化为JSON字符串
json.dump(token, file)
def load_token_from_file(filename):
with open(filename, 'r') as ***
* 读取文件内容并反序列化为Python字典
token = json.load(file)
return token
# 示例使用
token_info = {'token': '123456', 'expiry': '2023-06-30'}
save_token_to_file('token.json', token_info)
loaded_token = load_token_from_file('token.json')
print(loaded_token)
```
在上述代码中,我们使用了Python的json模块,将token信息序列化为JSON格式,并写入文件中。之后,我们又从文件中读取并反序列化得到token信息。整个过程涉及到文件的打开、读写和关闭操作,这些操作对于文件系统的持久化存储是必要的。
### 2.2.2 数据库在持久化中的应用
数据库系统能够提供更为强大的数据管理能力。通过数据库存储token,不仅能够实现数据的结构化存储,还能利用数据库提供的查询优化、事务支持等高级特性。在Python中,可以使用`sqlite3`模块轻松地创建和操作SQLite数据库,也可以使用诸如`sqlalchemy`这样的ORM库与多种数据库系统交互。
```python
import sqlite3
def create_db_connection(db_file):
conn = sqlite3.connect(db_file)
return conn
def save_token_to_db(conn, token):
cursor = conn.cursor()
# 创建表
cursor.execute('''CREATE TABLE IF NOT EXISTS tokens
(id INTEGER PRIMARY KEY, token TEXT, expiry TEXT)''')
# 插入token信息
cursor.execute('''INSERT INTO tokens (token, expiry) VALUES (?, ?)''', (token['token'], token['expiry']))
***mit()
def load_token_from_db(conn, token_id):
cursor = conn.cursor()
cursor.execute('''SELECT token, expiry FROM tokens WHERE id = ?''', (token_id,))
token_info = cursor.fetchone()
return token_info
# 示例使用
conn = create_db_connection('token.db')
save_token_to_db(conn, {'token': '123456', 'expiry': '2023-06-30'})
token_info = load_token_from_db(conn, 1)
print(token_info)
conn.close()
```
以上代码展示了如何在Python中使用SQLite数据库来持久化存储token信息。我们首先定义了数据库连接函数,然后通过执行SQL语句来创建表和插入数据。最后通过查询来加载特定的token信息。数据库作为存储介质,提供了比文件系统更为稳定和高效的数据管理方案。
## 2.3 高级持久化技术的选择
### 2.3.1 磁盘存储与内存存储对比
磁盘存储和内存存储各有其优劣。磁盘存储提供了持久性和大容量的数据存储能力,适合于需要长期保存的数据。而内存存储(例如使用Redis或Memcached)则提供了快速的读写速度,适合于需要频繁访问的临时数据。在选择存储技术时,我们需要根据应用场景和性能要求来做出决定。例如,对于频繁验证的token,使用内存存储可以大大减少延迟;而对于安全性要求更高的长期token,则可能需要磁盘存储的稳定性和持久性。
### 2.3.2 缓存策略与优化
使用缓存是优化持久化存储性能的常用方法之一。缓存可以临时保存高频访问的数据,减少对底层存储介质的直接访问次数,从而提升系统性能。在token存储中,可以对有效期内的token使用缓存机制,一旦token失效或过期,再从持久化存储中重新加载。这样既保证了数据的安全性,又可以提高系统的响应速度。在实现缓存策略时,需要注意缓存失效处理、数据一致性以及容量管理等问题。
缓存策略的实现可以通过如下示例代码来展示:
```python
from functools import lru_cache
@lru_cache(maxsize=100)
def load_token_from_persistence(token_id):
# 这里是模拟从持久化存储(如文件或数据库)加载token的过程
# 实际情况中应根据token_id来获取相应的token信息
return {'token': f'token_{token_id}', 'expiry': '2023-06-30'}
def check_token(token_id):
token = load_token_from_persistence(token_id)
# 进行token的验证和处理
print(f'Loaded token: {token}')
```
在该代码示例中,我们使用了Python标准库中的`lru_

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 中的 token 模块,揭示了其在 Python 编程、编译、性能优化、框架内部应用、代码审计、动态加载、代码混淆、异常处理、自动化测试、解释器构建和代码可视化中的关键作用。通过一系列文章,专栏提供了全面的见解,包括 token 生成和优化、解析器编写技巧、编译中的作用、与 AST 的联系、性能提升策略、框架内部应用、代码分析技巧、持久化存储、动态加载和卸载、代码混淆、异常处理、自动化测试中的应用、解释器构建和代码可视化。专栏旨在帮助 Python 开发者深入理解 token 模块,并将其应用于各种实际场景,从而提升代码质量、性能和安全性。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
LabVIEW TCP_IP编程进阶指南:从入门到高级技巧一步到位
# 摘要
本文旨在全面介绍LabVIEW环境下TCP/IP编程的知识体系,从基础概念到高级应用技巧,涵盖了LabVIEW网络通信的基础理论与实践操作。文中首先介绍了TCP/IP通信协议的深入解析,包括模型、协议栈、TCP与UDP的特点以及IP协议的数据包结构。随后,通过LabVIEW中的编程实践,本文展示了TCP/IP通信在LabVIEW平台下的实现方法,包括构建客户端和服务器以及UDP通信应用。文章还探讨了高级应用技巧,如数据传输优化、安全性与稳定性改进,以及与外部系统的集成。最后,本文通过对多个项目案例的分析,总结了LabVIEW在TCP/IP通信中的实际应用经验,强调了LabVIEW在实
移动端用户界面设计要点
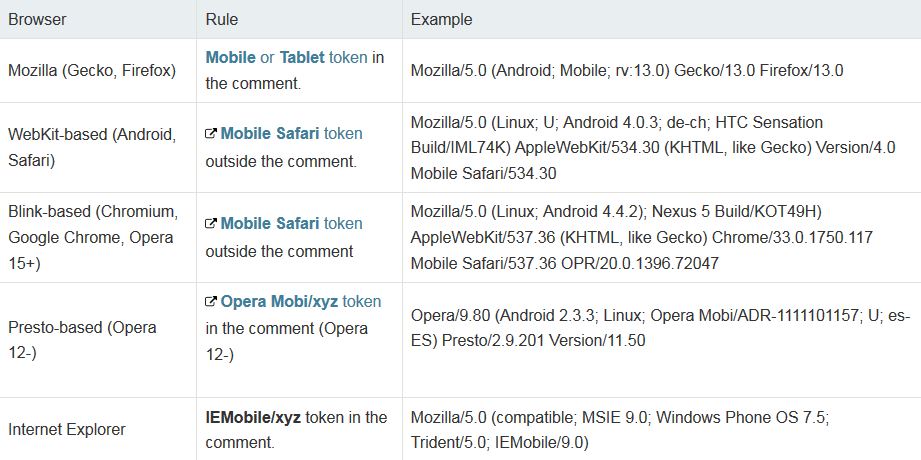
# 摘要
本论文全面探讨了移动端用户界面(UI)设计的核心理论、实践技巧以及进阶话题。第一章对移动端UI设计进行概述,第二章深入介绍了设计的基本原则、用户体验设计的核心要素和设计模式。第三章专注于实践技巧,包括界面元素设计、交互动效和可用性测试,强调了优化布局和响应式设计的重要性。第四章展望了跨平台UI框架的选择和未来界面设计的趋势,如AR/VR和AI技术的集成。第五章通过案例研究分析成功设计的要素和面临的挑战及解决
【故障排查的艺术】:快速定位伺服驱动器问题的ServoStudio(Cn)方法
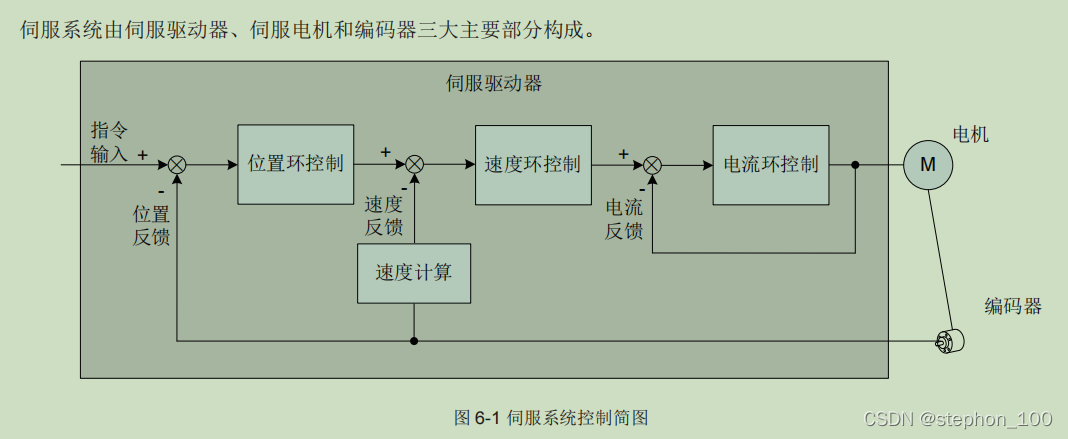
# 摘要
本文全面介绍了伺服驱动器的故障排查艺术,从基础理论到实际应用,详细阐述了伺服驱动器的工作原理、结构与功能以及信号处理机
GX28E01散热解决方案:保障长期稳定运行,让你的设备不再发热
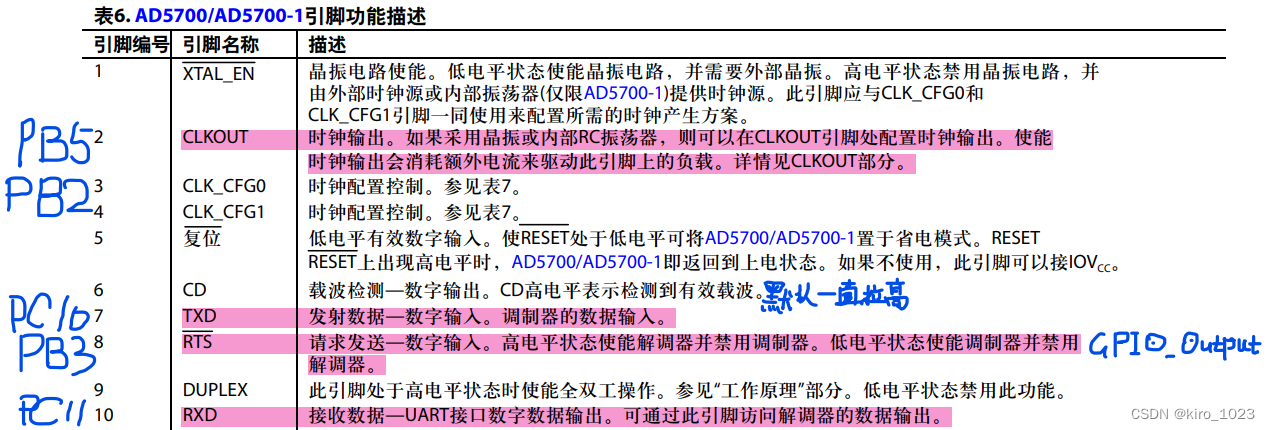
# 摘要
本文针对GX28E01散热问题的严峻性进行了详细探讨。首先,文章从散热理论基础出发,深入介绍了热力学原理及其在散热中的应用,并分析了散热材料与散热器设计的重要性。接着,探讨了硬件和软件层面的散热优化策略,并通过案例分析展示了这些策略在实际中的应用效果。文章进一步探讨了创新的散热技术,如相变冷却技术和主动冷却系统的集成,并展望了散热技术与热管理的未来发展趋势。最后,分析了散热解决方案的经济效益,并探讨了散
无缝集成秘籍:实现UL-kawasaki机器人与PROFINET的完美连接

# 摘要
本文综合介绍了UL-kawasaki机器人与PROFINET通信技术的基础知识、理论解析、实践操作、案例分析以及进阶技巧。首先概述了PROFINET技术原理及其
PDMS设备建模准确度提升:确保设计合规性的5大步骤

# 摘要
本文探讨了PDMS设备建模与设计合规性的基础,深入分析了建模准确度的定义及其与合规性的关系,以及影响PDMS建模准确度的多个因素,包括数据输入质量、建模软件特性和设计者技能等。文章接着提出了确保PDMS建模准确度的策略,包括数据准备、验证流程和最佳建模实践。进一步,本文探讨了PDMS建模准确度的评估方法,涉及内部和外部评估
立即掌握!Aurora 64B-66B v11.2时钟优化与复位策略

# 摘要
本文全面介绍了Aurora 64B/66B的时钟系统架构及其优化策略。首先对Aurora 64B/66B进行简介,然后深入探讨了时钟优化的基础理论,包括时钟域、同步机制和时
掌握CAN协议:10个实用技巧快速提升通信效率
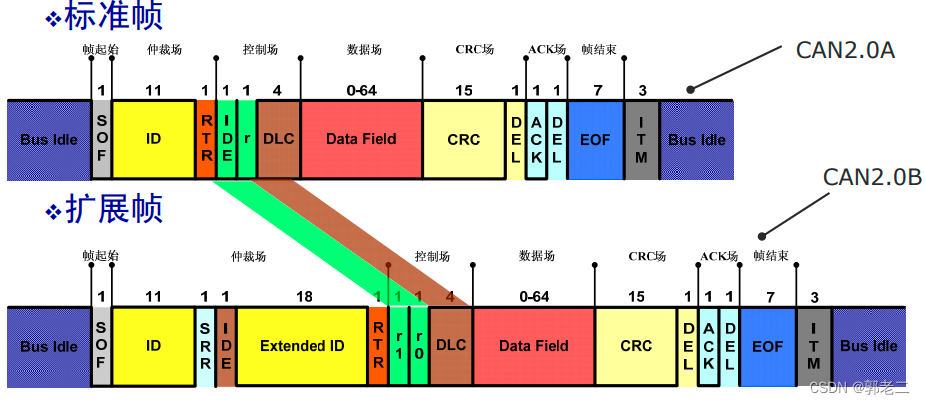
# 摘要
本论文全面介绍了CAN协议的基础原理、硬件选择与配置、软件配置与开发、故障诊断与维护以及在不同领域的应用案例。首先,概述了CAN协议的基本概念和工作原理,然后详细探讨了在选择CAN控制器和收发器、设计网络拓扑结构、连接硬件时应考虑的关键因素以及故障排除技巧。接着,论文重点讨论了软件配置,包括CAN协议栈的选择与配置、消息过滤策略和性能优化。此外,本研究还提供了故障诊断与维护的基
【金字塔构建秘籍】:专家解读GDAL中影像处理速度的极致优化

# 摘要
本文系统地介绍了GDAL影像处理的基础知识、关键概念、实践操作、高级优化技术以及性能评估与调优技巧。文章首先概述了GDAL库的功能和优势,随后深入探讨了影像处理速度优化的理论基础,包括时间复杂度、空间复杂度和多线程并行计算原理,以及GPU硬件加速的应用。在实践操作章节,文章分析了影像格式优化、缓冲区与瓦片技术的应用以及成功案例研究。高级优化技术与工具章节则讨论了分割与融合技术
电子技术期末考试:掌握这8个复习重点,轻松应对考试
# 摘要
本文全面覆盖电子技术期末考试的重要主题和概念,从模拟电子技术到数字电子技术,再到信号与系统理论基础,以及电子技术实验技能的培养。首先介绍了模拟电子技术的核心概念,包括放大电路、振荡器与调制解调技术、滤波器设计。随后,转向数字电子技术的基础知识,如逻辑门电路、计数器与寄存器设计、时序逻辑电路分析。此外,文章还探讨了信号与系统理论基础,涵盖信号分类、线性时不变系统特性、频谱分析与变换。最后,对电子技术实验技能进行了详细阐述,包括电路搭建与测试、元件选型与应用、实验报告撰写与分析。通过对这些主题的深入学习,学生可以充分准备期末考试,并为未来的电子工程项目打下坚实的基础。
# 关键字
模拟
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )