




编译原理深度解析:token在Python编译中的不凡作用


编译原理课程设计: 使用Python实现的类Pascal语言的词法分析和语法分析器
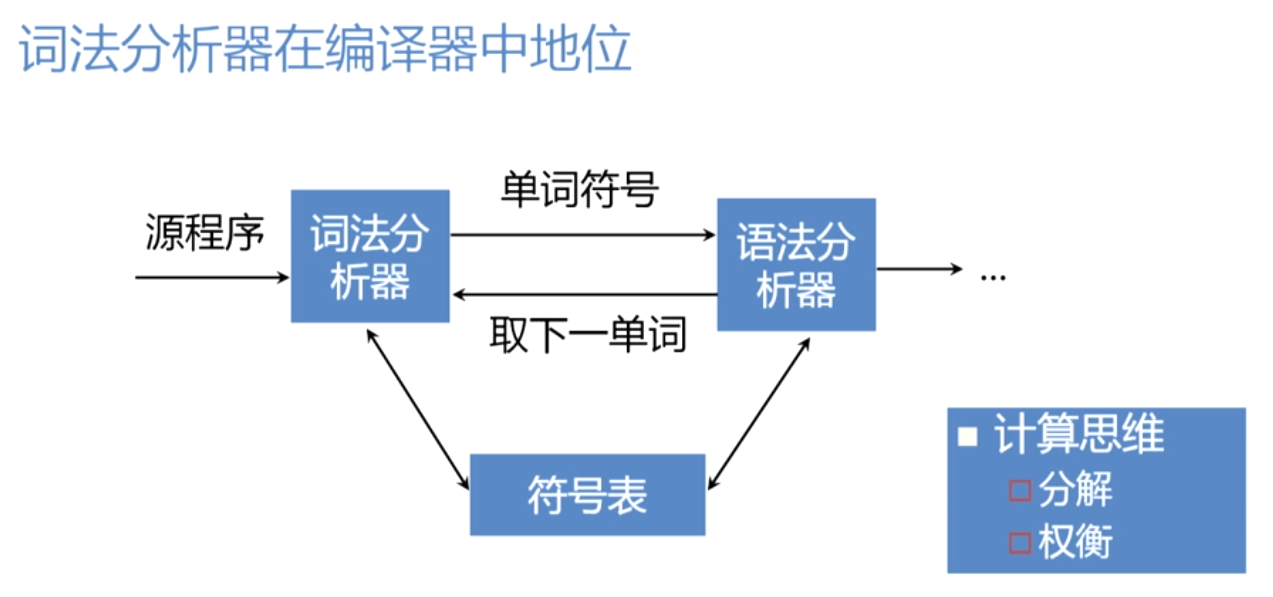
1. 编译原理概述
编译原理是计算机科学中的一个重要分支,它涉及将高级语言编写的源代码转换成机器可以理解和执行的机器代码的过程。这个转换过程不是简单的字面翻译,而是一个复杂的转换机制,其核心是编译器。
编译器是一个程序,它通常包含若干个模块,这些模块按照特定的编译流程将源代码转换为目标代码。编译流程一般分为前端和后端两部分。前端负责解析源代码,生成中间表示(Intermediate Representation, IR);后端则将IR转化为最终的目标机器代码。
理解编译原理能够让我们深入地认识到代码是如何被计算机执行的,对提高程序的性能和优化代码有着直接的帮助。本章将为读者提供编译原理的基础知识,为理解后续章节打下坚实基础。
2. Token的定义与重要性
2.1 Token的概念和分类
2.1.1 词法分析阶段的Token生成
在编译器处理源代码的过程中,Token生成是将源代码文本转换为计算机可识别的符号序列的第一步。词法分析器(Lexer),或称扫描器(Scanner),负责将输入的源代码字符串分解成一系列的Token。每个Token通常代表了语言中的一种元素,如关键字、标识符、字面量、运算符等。
Token的生成遵循了预定义的语法规则。这些规则通常定义在编译器设计阶段,通过正则表达式或者状态机来实现。每个规则指定了如何从输入源代码中识别出一个特定的Token类型。举例来说,一个简单的词法规则可以是:
- <IntegerLiteral> ::= <Digit> { <Digit> }
这条规则定义了一个整数字面量Token由一个数字开始,后面跟着任意数量的数字组成。
词法分析器遍历源代码字符串,一次读取一个字符,并根据当前状态和已有的规则来决定下一步的行动,最终生成Token序列。
2.1.2 Token的语法与结构
Token本身由两个部分组成:Token类型和Token值。Token类型是一个标识符,用于说明Token的类别,比如IDENTIFIER表示标识符,OPERATOR表示运算符等。Token值则是具体的内容,例如标识符的具体名字,或者是特定运算符的符号。
举例来说,在处理表达式x = 10 + 20;时,词法分析器会生成以下Token序列:
IDENTIFIER,Token值为"x"ASSIGNMENT_OPERATOR,Token值为"="INTEGER_LITERAL,Token值为"10"ADD_OPERATOR,Token值为"+"INTEGER_LITERAL,Token值为"20"SEMICOLON,Token值为";"
这个序列就代表了原代码表达式的意义。
2.2 Token在编译过程中的作用
2.2.1 从源代码到Token的转换
编译器的编译过程开始于源代码,然后通过一系列的步骤将其转换成可执行文件。这个过程中,Token的生成是第一步,也是至关重要的一步。源代码首先经过词法分析器处理,将字符序列转化为Token序列。这个过程实际上是给编译器提供了一个结构化、形式化的输入。
词法分析器会检查源代码中的所有字符,并根据语言的词法规则把它们分组,每个组对应一个Token。例如,一个变量名可能是一个标识符Token,一个加号可能是一个运算符Token。
这个转换过程可以通过下面的步骤概括:
- 读入源代码。
- 按字符逐个分析。
- 应用词法规则匹配Token类型。
- 输出Token序列。
2.2.2 Token与编译的中间表示(IR)
生成的Token序列是编译过程的中间表示(Intermediate Representation,IR)的基础。IR是编译器将源代码转换为机器代码过程中使用的一种中间形式。
Token序列通常会进一步通过语法分析阶段,转换成抽象语法树(Abstract Syntax Tree,AST)。AST是一种树状结构,更接近程序的逻辑结构,有助于后续的语义分析和优化。
Token转换为AST的过程大致如下:
- Token序列作为输入。
- 语法分析器(Parser)根据语法规则构造AST。
- AST反映了源代码的逻辑结构,包括表达式、控制流程等。
- AST作为编译优化和目标代码生成的输入。
通过将源代码先转换为Token序列,再从Token序列构建AST,编译器能够更容易地进行后续的编译阶段。
3. Token在Python编译中的实践
在探讨了Token的定义和它在编译过程中的关键作用之后,本章节将深入Python语言的编译实践,以了解Token在实际编译器中的应用情况。我们将详细剖析Python的词法分析器如何生成Token,以及这些Token是如何被进一步处理以构建语法树和参与语义分析的。
3.1 Python的词法分析器和Token生成
词法分析是编译过程中的第一阶段,其核心任务是从源代码字符串中提取出有意义的符号序列,也就是Token。Python作为一门动态语言,它的词法分析器是如何工作呢?让我们从源代码的词法分析过程开始详细了解。
3.1.1 Python源代码的词法分析过程
Python的词法分析过程由一个名为tokenize的模块实现,它位于Python标准库中。这个模块通过读取源代码文件并将其分解为一系列的Token。每个Token都有特定的类型,例如标识符、关键字、字面量、运算符等。词法分析器根据预定的规则,检查源代码字符串中的字符序列,并将它们分类为相应的Token类型。
词法分析器在处理源代码时,会考虑Python的语法规则,例如空格、换行、注释以及字符串和注释中的引号,都会被正确地处理并生成相应的Token。此外,Python的词法分析器还支持多种编码的源代码文件,确保正确地读取和解析。
下面是一个简单的Python代码示例及其词法分析过程:
- # 示例Python代码
- def hello_world():
- print("Hello, Token!")
该代码通过tokenize.tokenize方法进行分析后,会得到类似下面的Token序列:
- NAME 'def'
- NAME 'hello_world'
- OP '('
- OP ')'
- NAME 'print'
- STRING '"Hello, Token!"'
- NEWLINE
3.1.2 Python标准库中的Token实现
Python标准库中的token模块定义了所有的Token类型。这些类型用数字代码表示,并且每个Token类型都有一个对应的字符串名称。这些信息对于理解词法分析器生成的Token非常有用,也有助于调试编译过程中的问题。
例如,token模块中定义了如下Token类型:
- NAME = 1
- NUMBER = 2
- STRING = 3
- ... # 其他Token类型
了解这些Token类型之后,我们可以使用tokenize模块提供的tokenize.tokenize函数,通过查看每个生成Token的类型代码来跟踪词法分析的输出。
3.2 Python编译器中的Token处理
在Python源代码被分解为Token序列之后,编译器的下一步是对这些Token进行解析,以构建出语法树(Abstract Syntax Tree, AST)。这一过程涉及到Token的解析和语义分析,其中Token扮演着关键角色。
3.2.1

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【FLUKE_8845A_8846A维护秘籍】:专家分享的快速故障排除与校准技巧
【通信优化攻略】:深入BSW模块间通信机制,提升网络效率
EPLAN 3D功能:【从2D到3D的飞跃】:掌握设计转变的关键技术
内存优化:快速排序递归调用栈的【深度分析】与防溢出策略
无线定位技术:GPS与室内定位系统的挑战与应用
【Web开发者福音】:一站式高德地图API集成指南
【云网络模拟新趋势】:eNSP在VirtualBox中的云服务集成
【精挑细选RFID系统组件】:专家教你如何做出明智选择
【故障快速排除】:三启动U盘制作中的7大常见问题及其解决策略
空间数据分析与可视化:R语言与GIS结合的6大实战技巧


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















