Redis缓存实战:提升应用性能
发布时间: 2024-07-12 23:04:25 阅读量: 52 订阅数: 21 

数据库实战:Redis缓存数据库实战资源
# 1. Redis缓存概述**
Redis是一种开源的、基于内存的键值存储系统,它以其高性能、可扩展性和灵活性而闻名。作为一种缓存解决方案,Redis可以显著提高应用程序的性能,减少数据库负载,并改善用户体验。
Redis使用键值对存储数据,其中键是唯一的标识符,而值可以是字符串、列表、哈希表或集合等各种数据类型。Redis支持多种操作,包括读取、写入、删除和更新,并提供丰富的命令集来操作数据。
Redis的高性能归功于其内存中的数据存储方式,这消除了磁盘I/O的延迟。此外,Redis使用异步I/O和单线程事件循环,可以处理大量并发请求,使其非常适合处理高流量的应用程序。
# 2. Redis缓存实战应用
### 2.1 Redis缓存的配置和部署
#### 2.1.1 Redis服务器的安装和配置
**安装Redis服务器**
在Linux系统中,可以使用以下命令安装Redis服务器:
```
sudo apt-get install redis-server
```
**配置Redis服务器**
Redis服务器的配置文件位于`/etc/redis/redis.conf`,可以根据需要进行修改。以下是一些重要的配置参数:
| 参数 | 说明 |
|---|---|
| bind | 服务器绑定的IP地址 |
| port | 服务器监听的端口号 |
| maxmemory | 服务器的最大内存限制 |
| maxclients | 服务器允许的最大客户端连接数 |
**启动Redis服务器**
配置完成后,可以使用以下命令启动Redis服务器:
```
sudo service redis-server start
```
#### 2.1.2 Redis客户端的连接和使用
**连接Redis服务器**
使用Redis客户端连接到Redis服务器,可以使用以下命令:
```
redis-cli -h <主机名> -p <端口号>
```
**基本操作命令**
连接到Redis服务器后,可以使用以下基本命令进行操作:
| 命令 | 说明 |
|---|---|
| SET | 设置键值对 |
| GET | 获取键值 |
| DEL | 删除键 |
| EXISTS | 检查键是否存在 |
### 2.2 Redis缓存的读写操作
#### 2.2.1 基本的读写命令
**SET命令**
SET命令用于设置键值对,语法如下:
```
SET key value [expiration] [NX|XX]
```
其中:
* key:键的名称
* value:键的值
* expiration:键的过期时间(单位:秒)
* NX:如果键不存在,则设置键值对
* XX:如果键存在,则设置键值对
**GET命令**
GET命令用于获取键值,语法如下:
```
GET key
```
如果键存在,则返回键的值;否则,返回nil。
#### 2.2.2 数据结构的读写操作
除了基本的数据类型外,Redis还支持多种数据结构,如列表、集合、有序集合和哈希。
**列表**
列表是一个有序的键值对集合,可以使用以下命令进行操作:
| 命令 | 说明 |
|---|---|
| LPUSH | 在列表的头部添加元素 |
| RPUSH | 在列表的尾部添加元素 |
| LRANGE | 获取列表中指定范围的元素 |
**集合**
集合是一个无序的不重复元素集合,可以使用以下命令进行操作:
| 命令 | 说明 |
|---|---|
| SADD | 向集合中添加元素 |
| SMEMBERS | 获取集合中的所有元素 |
| SREM | 从集合中删除元素 |
**有序集合**
有序集合是一个有序的键值对集合,元素按分数排序,可以使用以下命令进行操作:
| 命令 | 说明 |
|---|---|
| ZADD | 向有序集合中添加元素 |
| ZRANGE | 获取有序集合中指定范围的元素 |
| ZSCORE | 获取元素的分数 |
**哈希**
哈希是一个键值对集合,其中键是字符串,值是字符串、列表、集合或有序集合,可以使用以下命令进行操作:
| 命令 | 说明 |
|---|---|
| HSET | 向哈希中设置键值对 |
| HGET | 获取哈希中指定键的值 |
| HDEL | 从哈希中删除键值对 |
# 3.1 Redis缓存的集群和复制
#### 3.1.1 Redis集群的搭建和配置
**集群搭建**
Redis集群是一个由多个Redis实例组成的分布式系统,它提供了高可用性和可扩展性。要搭建一个Redis集群,需要以下步骤:
1. **创建集群配置文件:**为每个Redis实例创建`redis.conf`配置文件,并设置以下参数:
- `cluster-enabled yes`:启用集群模式
- `cluster-config-file nodes.conf`:指定集群节点配置文件的位置
- `cluster-node-timeout 15000`:设置节点超时时间
2. **创建节点配置文件:**创建`nodes.conf`文件,其中包含集群中所有节点的IP地址和端口号:
```
127.0.0.1:6379
127.0.0.1:6380
127.0.0.1:6381
```
3. **启动Redis实例:**使用`redis-server`命令启动每个Redis实例,并指定配置文件:
```
redis-server /path/to/redis.conf
```
4. **创建集群:**使用`redis-cli`命令创建集群:
```
redis-cli --cluster create 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 --cluster-replicas 1
```
**参数说明:**
- `--cluster create`:创建集群命令
- `127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381`:集群中节点的IP地址和端口号
- `--cluster-replicas 1`:每个主节点的从节点数量
**集群配置**
创建集群后,需要配置集群的设置:
- **设置集群名称:**使用`CLUSTER SET CLUSTERNAME <name>`命令设置集群名称。
- **分配槽位:**使用`CLUSTER ADDSLOTS <slot-range>`命令将槽位分配给集群中的节点。
- **添加从节点:**使用`CLUSTER REPLICATE <master-node-id> <replica-node-id>`命令将从节点添加到主节点。
#### 3.1.2 Redis复制的原理和实现
**复制原理**
Redis复制是一种主从复制机制,其中一个主节点(master)将数据复制到多个从节点(slave)。主节点负责处理写操作,并将这些操作传播到从节点。从节点只负责处理读操作,并从主节点获取数据。
**复制实现**
Redis复制的实现基于以下步骤:
1. **建立连接:**从节点通过`PSYNC`命令连接到主节点。
2. **全量复制:**主节点将整个数据集发送给从节点。
3. **增量复制:**主节点将新写入的数据发送给从节点。
4. **从节点处理:**从节点接收并处理主节点发送的数据,并将其应用到自己的数据集。
**参数说明:**
- `PSYNC`:建立复制连接的命令
- `全量复制`:将整个数据集从主节点复制到从节点
- `增量复制`:将新写入的数据从主节点复制到从节点
**复制配置**
配置Redis复制需要以下步骤:
1. **在主节点上启用复制:**使用`slaveof no one`命令禁用复制,然后使用`slaveof <master-node-id>`命令将主节点设置为从节点。
2. **在从节点上启用复制:**使用`slaveof <master-node-id>`命令将主节点设置为从节点。
3. **设置复制偏移量:**使用`repl-offset`选项设置从节点的复制偏移量。
# 4. Redis缓存与其他技术的集成**
Redis缓存是一种强大的工具,可以与各种其他技术集成以增强其功能和适用性。本章将探讨Redis缓存与Spring Boot和消息队列的集成,展示如何利用这些集成来构建更强大、更灵活的应用程序。
## 4.1 Redis缓存与Spring Boot的集成
Spring Boot是一个流行的Java框架,它简化了Spring应用程序的开发。Spring Boot提供对Redis缓存的原生支持,使开发人员能够轻松地将Redis集成到他们的应用程序中。
### 4.1.1 Spring Boot对Redis的支持
Spring Boot提供了以下功能来支持Redis集成:
- **自动配置:**Spring Boot会自动配置Redis连接和缓存操作。
- **注解支持:**Spring Boot提供了`@Cacheable`和`@CachePut`等注解,用于简化缓存操作。
- **缓存管理器:**Spring Boot提供了`CacheManager`接口,允许开发人员自定义缓存行为。
### 4.1.2 Redis缓存的配置和使用
要将Redis缓存集成到Spring Boot应用程序中,需要进行以下步骤:
1. 在`pom.xml`文件中添加Redis依赖项:
```xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
```
2. 在`application.properties`文件中配置Redis连接信息:
```properties
spring.redis.host=localhost
spring.redis.port=6379
```
3. 使用`@Cacheable`注解将方法标记为可缓存:
```java
@Cacheable("myCache")
public String getCachedData() {
// 从数据库获取数据
return data;
}
```
4. 使用`@CachePut`注解更新缓存:
```java
@CachePut("myCache")
public void updateCachedData(String data) {
// 更新数据库中的数据
}
```
## 4.2 Redis缓存与消息队列的集成
消息队列是一种异步通信机制,允许应用程序在松散耦合的方式下交换消息。Redis缓存可以与消息队列集成,以提供持久化和可靠的消息传递。
### 4.2.1 Redis作为消息队列的实现
Redis可以通过`LIST`数据结构实现消息队列。以下是一个使用Redis作为消息队列的示例:
```
// 入队
redis.lpush("myQueue", "message");
// 出队
String message = redis.rpop("myQueue");
```
### 4.2.2 Redis与其他消息队列的协作
Redis还可以与其他消息队列集成,例如Apache Kafka和RabbitMQ。这种集成允许应用程序利用Redis的持久性和可靠性,同时利用其他消息队列的特性,例如分区和并行处理。
以下是一个使用Redis和Kafka集成的示例:
```
// Kafka消费者
@KafkaListener(topics = "myTopic")
public void consumeMessage(String message) {
// 将消息存储在Redis缓存中
redis.lpush("myCache", message);
}
```
通过将Redis缓存与其他技术集成,开发人员可以构建更强大、更灵活的应用程序。Redis缓存与Spring Boot的集成简化了缓存操作,而与消息队列的集成提供了持久化和可靠的消息传递。
# 5. Redis缓存的监控和运维
### 5.1 Redis缓存的监控工具和指标
#### 5.1.1 Redis的内置监控工具
Redis提供了丰富的内置监控工具,可以帮助用户实时监控Redis服务器的运行状态和性能指标。这些工具包括:
- **INFO命令:**INFO命令可以显示Redis服务器的各种信息,包括服务器版本、运行时间、内存使用情况、连接数、命令执行统计等。
- **MONITOR命令:**MONITOR命令可以实时显示Redis服务器接收到的所有命令和响应。这有助于用户了解服务器的负载情况和命令执行效率。
- **SLOWLOG命令:**SLOWLOG命令可以记录执行时间超过指定阈值的命令,帮助用户识别和优化慢查询。
#### 5.1.2 第三方Redis监控工具
除了Redis内置的监控工具,还有许多第三方Redis监控工具可供选择,这些工具通常提供更丰富的功能和可视化界面。一些流行的第三方Redis监控工具包括:
- **RedisInsight:**RedisInsight是一个商业Redis监控工具,提供实时监控、告警、故障排除和性能分析等功能。
- **RedisGraph:**RedisGraph是一个开源Redis监控工具,提供图形化界面,可以直观地展示Redis服务器的运行状态和性能指标。
- **Redis-stat:**Redis-stat是一个轻量级的Redis监控工具,提供命令统计、内存使用情况、连接数等基本监控指标。
### 5.2 Redis缓存的运维和故障排除
#### 5.2.1 常见的Redis故障和解决方法
Redis是一个稳定可靠的缓存系统,但仍可能遇到一些常见的故障。以下是一些常见的Redis故障及其解决方法:
| 故障类型 | 可能原因 | 解决方法 |
|---|---|---|
| 连接失败 | Redis服务器未启动或监听端口错误 | 检查Redis服务器是否已启动,并确保监听端口正确 |
| 命令执行失败 | Redis服务器内存不足或命令语法错误 | 检查Redis服务器的内存使用情况,并确保命令语法正确 |
| 慢查询 | 命令执行时间过长 | 使用SLOWLOG命令识别慢查询,并优化相关代码 |
| 数据丢失 | Redis服务器未持久化数据或持久化失败 | 配置Redis持久化功能,并定期备份Redis数据 |
| 复制失败 | Redis复制配置错误或网络问题 | 检查Redis复制配置,并确保网络连接正常 |
#### 5.2.2 Redis缓存的性能调优和优化
为了确保Redis缓存的高性能和稳定性,需要进行适当的性能调优和优化。以下是一些Redis缓存性能调优和优化技巧:
- **优化内存使用:**使用合适的数据结构存储数据,并定期清理过期数据。
- **优化命令执行:**使用管道化和批量操作来减少网络开销。
- **使用持久化:**配置Redis持久化功能,以防止数据丢失。
- **使用复制:**配置Redis复制,以提高可用性和容错性。
- **监控和调优:**使用监控工具实时监控Redis服务器的运行状态和性能指标,并根据需要进行调优。
# 6. Redis缓存的未来趋势
### 6.1 Redis缓存的发展现状和趋势
#### 6.1.1 Redis新版本和特性
Redis 7.0是Redis的最新主要版本,引入了许多新特性和改进,包括:
- **模块化架构:**允许用户加载和使用自定义模块,扩展Redis的功能。
- **RESP3协议:**一种新的二进制协议,比RESP2更快、更紧凑。
- **流数据类型:**一种新的数据类型,用于处理无界数据流。
- **时序数据支持:**针对时序数据的优化,包括时间序列查询和聚合。
#### 6.1.2 Redis在云计算和物联网中的应用
Redis在云计算和物联网中得到了广泛应用:
- **云计算:**Redis作为云服务提供,用于缓存、消息传递和会话管理。
- **物联网:**Redis用于存储和处理物联网设备产生的实时数据,例如传感器数据和事件。
### 6.2 Redis缓存的最佳实践和建议
#### 6.2.1 Redis缓存的设计和部署原则
- **选择合适的缓存策略:**根据应用场景选择最合适的缓存策略,例如LRU、LFU或FIFO。
- **合理设置缓存大小:**根据实际需求设置缓存大小,避免过大或过小。
- **使用集群和复制:**对于高可用性和可扩展性,使用Redis集群和复制机制。
#### 6.2.2 Redis缓存的性能优化和故障处理
- **使用持久化:**启用持久化以防止数据丢失,例如RDB或AOF。
- **监控和告警:**使用监控工具和告警机制来监视Redis缓存的性能和健康状况。
- **故障处理:**制定故障处理计划,包括故障转移、数据恢复和性能调优。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
**对角专栏:数据库与分布式系统**
"对角"专栏深入探讨数据库和分布式系统领域的各种技术和实践。专栏文章涵盖广泛主题,包括:
* MySQL数据库性能优化技巧,揭示性能下降的根源并提供解决方案
* MySQL死锁问题分析和解决策略
* MySQL索引失效案例分析和修复指南
* MySQL表锁问题全解析,深入解读表锁机制和解决方案
* MySQL慢查询优化指南,从原理到实际应用
* MySQL数据库主从复制原理和实践,实现高可用性
* MySQL数据库备份和恢复实战,确保数据安全
* MySQL数据库调优实战,从入门到精通
* NoSQL数据库选型指南,满足不同场景需求
* Redis缓存实战,提升应用性能
* MongoDB数据库入门和实践,探索文档型数据库的优势
* Elasticsearch搜索引擎实战,打造高效搜索体验
* Kafka消息队列实战,构建分布式系统
* Kubernetes容器编排实战,实现云原生应用管理
* 微服务架构设计和实践,实现分布式系统
* DevOps实践指南,提升软件开发效率
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Python降级实战秘籍】:精通版本切换的10大步骤与技巧
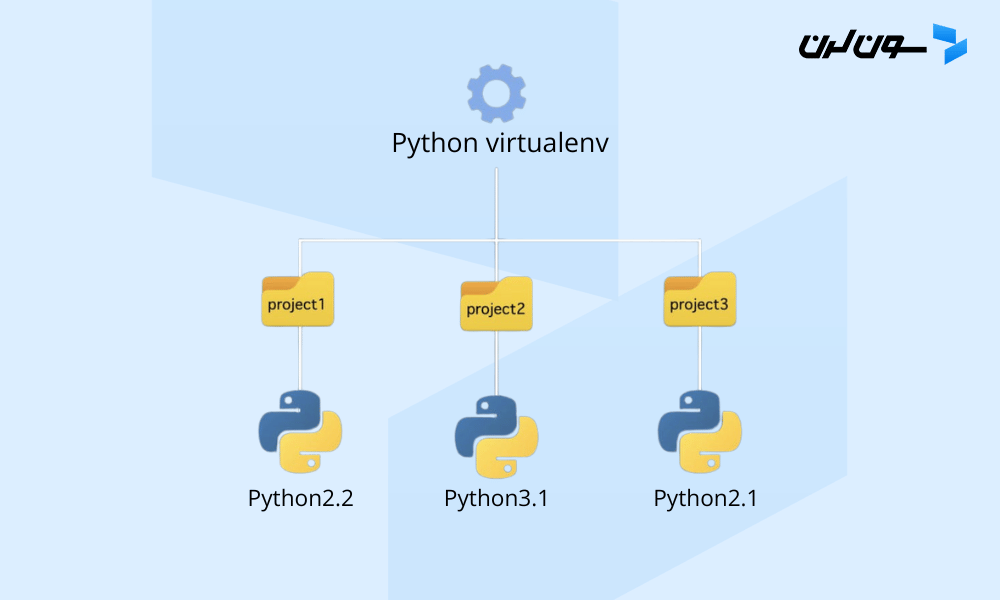
# 摘要
本文针对Python版本管理的需求与实践进行了全面探讨。首先介绍了版本管理的必要性与基本概念,然后详细阐述了版本切换的准备工作,包括理解命名规则、安装和配置管理工具以及环境变量的设置。进一步,本文提供了一个详细的步骤指南,指导用户如何执行Python版本的切换、降级操作,并提供实战技巧和潜在问题的解决方案。最后,文章展望了版本管理的进阶应用和降级技术的未来,讨论了新兴工具的发展趋势以及降级技术面临的挑战和创新方
C++指针解密:彻底理解并精通指针操作的终极指南
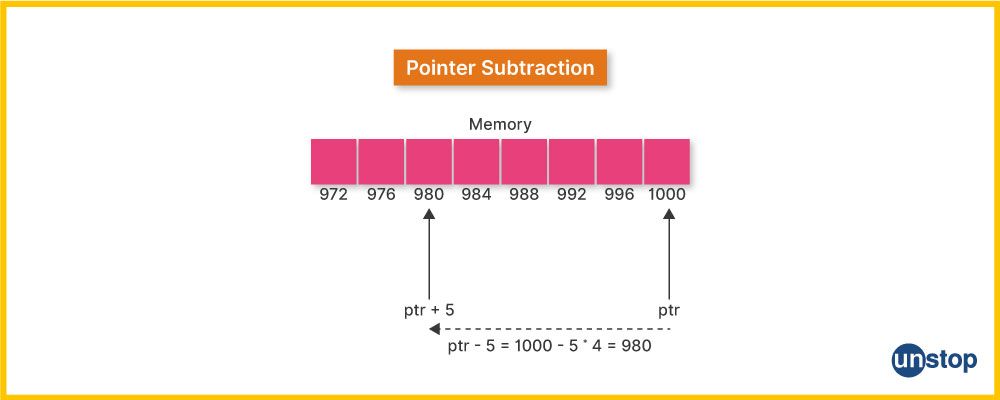
# 摘要
指针作为编程中一种核心概念,贯穿于数据结构和算法的实现。本文系统地介绍了指针的基础知识、与数组、字符串、函数以及类对象的关系,并探讨了指针在动态内存管理、高级技术以及实际应用中的关键角色。同时,本文还涉及了指针在并发编程和编译器优化中的应用,以及智能指针等现代替代品的发展。通过分析指针的多种用途和潜在问题,本文旨
CANoe J1939协议全攻略:车载网络的基石与实践入门

# 摘要
本文系统地介绍并分析了车载网络中广泛采用的J1939协议,重点阐述了其通信机制、数据管理以及与CAN网络的关系。通过深入解读J1939的消息格式、传输类型、参数组编号、数据长度编码及其在CANoe环境下的集成与通信测试,本文为读者提供了全面理解J1939协议的基础知识。此外,文章还讨论了J1
BES2300-L新手指南:7步快速掌握芯片使用技巧

# 摘要
BES2300-L芯片作为本研究的焦点,首先对其硬件连接和初始化流程进行了详细介绍,包括硬件组件准
数字电路设计者的福音:JK触发器与Multisim的终极融合
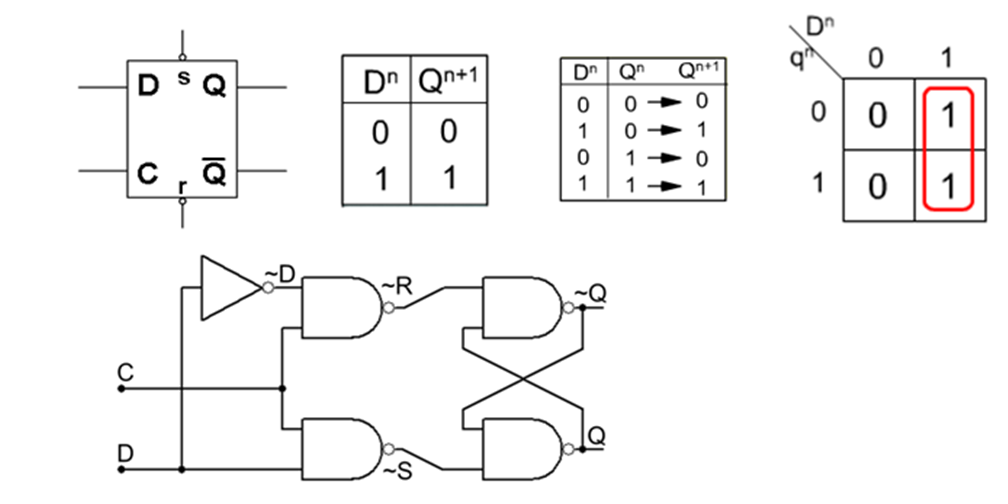
# 摘要
本文首先介绍了数字逻辑与JK触发器的基础知识,并深入探讨了JK触发器的工作原理、类型与特性,以及其在数字电路中的应用,如计数器和顺序逻辑电路设计。随后,文章转向使用Multisim仿真软件进行JK触发器设计与测试的入门知识。在此基础上,作者详细讲解了JK触发器的基本设计实践,包括电路元件的选择与搭建,以及多功能JK触发器设计的逻辑分析和功能验证。最后,文章提供了
企业级自动化调度:实现高可用与容错机制(专家秘籍)

# 摘要
企业级自动化调度系统是现代企业IT基础设施中的核心组成部分,它能够有效提升任务执行效率和业务流程的自动化水平。本文首先介绍了自动化调度的基础概念,包括其理论框架和策略算法,随后深入探讨了高可用性设计原理,涵盖多层架构、负载均衡技术和数据复制策略。第三章着重论述了容错机制的理论基础和实现步骤,包括故障检测、自动恢复以及FMEA分析。第四章则具体说明了自动化调度系统的设计与实践,包括平台选型、
【全面揭秘】:富士施乐DocuCentre SC2022安装流程(一步一步,轻松搞定)

# 摘要
本文全面介绍富士施乐DocuCentre SC2022的安装流程,从前期准备工作到硬件组件安装,再到软件安装与配置,最后是维护保养与故障排除。重点阐述了硬件需求、环境布局、软件套件安装、网络连接、功能测试和日常维护建议。通过详细步骤说明,旨在为用户提供一个标准化的安装指南,确保设备能够顺利运行并达到最佳性能,同时强调预防措施和故障处理的重要性,以减少设备故障率和延长使用寿命。
XJC-CF3600F保养专家

# 摘要
本文综述了XJC-CF3600F设备的概况、维护保养理论与实践,以及未来展望。首先介绍设备的工作原理和核心技术,然后详细讨论了设备的维护保养理论,包括其重要性和磨损老化规律。接着,文章转入操作实践,涵盖了日常检查、定期保养、专项维护,以及故障诊断与应急响应的技巧和流程。案例分析部分探讨了成功保养的案例和经验教训,并分析了新技术在案例中的应用及其对未来保养策略的
生产线应用案例:OpenProtocol-MTF6000的实践智慧

# 摘要
本文详细介绍了OpenProtocol-MTF6000协议的特点、数据交换机制以及安全性分析,并对实际部署、系统集成与测试进行了深入探讨。文中还分析了OpenProtocol-MTF6000在工业自动化生产线、智能物流管理和远程监控与维护中的应用案例,展示了其在多种场景下的解决方案与实施步骤。最后,本文对OpenProtocol-MTF6000未来的发
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )