【递归模块化编程】:Python设计模式与实践指南
发布时间: 2024-09-12 16:57:11 阅读量: 254 订阅数: 44 

一个古老的编程游戏:Python-Challenge全通攻略.docx
# 1. 递归模块化编程概述
在软件开发领域,递归模块化编程是一种重要的编程范式,它强调将复杂问题分解成更小、更易管理的模块,并通过递归方法解决这些问题。递归,作为一种在程序中自我调用的技术,使得代码更加简洁且易于理解。模块化编程则是将程序划分为独立、可替换的代码块,每个模块完成一个具体的子任务。本章将详细介绍递归与模块化编程的基本概念、优势以及在现代软件开发中的重要性。掌握递归模块化编程对于构建可维护、可扩展的软件系统至关重要。随着技术的发展,递归模块化已经成为许多高级编程语言和框架中不可或缺的一部分,为开发者提供了强大的工具来处理复杂问题。
# 2. Python中的设计模式
在软件工程领域,设计模式为解决特定问题提供了一种可复用的解决方案。Python作为一种广泛使用的高级编程语言,其简洁的语法和强大的库支持,使得在Python项目中应用设计模式变得既高效又实用。接下来,我们将深入探讨Python中的设计模式,并对创建型模式、结构型模式以及行为型模式进行详细讲解和案例分析。
## 2.1 创建型模式
创建型模式关注于对象的创建过程,旨在降低对象创建的复杂性。在Python中,由于其动态类型和内存管理的特性,创建型模式的表现和实现可能会与传统面向对象语言有所不同。
### 2.1.1 单例模式
单例模式是一种常用的创建型设计模式,它确保一个类只有一个实例,并提供一个全局访问点。
```python
class SingletonMeta(type):
_instances = {}
def __call__(cls, *args, **kwargs):
if cls not in cls._instances:
instance = super().__call__(*args, **kwargs)
cls._instances[cls] = instance
return cls._instances[cls]
class Singleton(metaclass=SingletonMeta):
def __init__(self):
pass
# 创建实例
singleton1 = Singleton()
singleton2 = Singleton()
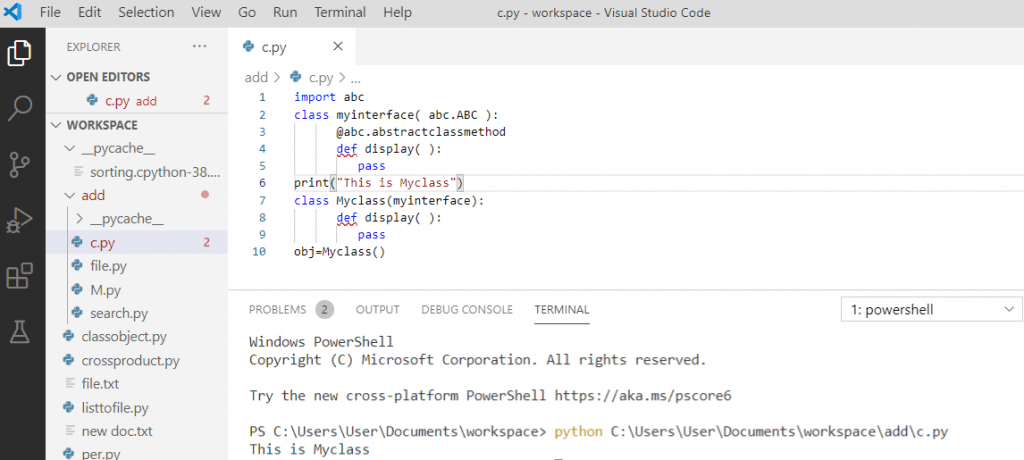
print(singleton1 is singleton2) # 输出 True
```
在上述代码中,我们通过一个元类`SingletonMeta`来控制`Singleton`类的实例化过程。当尝试创建新的实例时,元类首先检查类是否已经有一个实例。如果有,它将返回现有的实例而不是创建一个新的。这样可以确保类`Singleton`只有一个实例。
### 2.1.2 建造者模式
建造者模式(Builder Pattern)用于创建复杂对象,它允许用户仅通过指定复杂对象的类型和内容就可以构建它们,而不用实际了解内部的构建细节。
```python
class Product:
def __init__(self):
self.parts = []
def add(self, part):
self.parts.append(part)
class Builder:
def __init__(self):
self.product = Product()
def add_part(self, part):
self.product.add(part)
return self
def get_result(self):
return self.product
class Director:
def __init__(self, builder):
self.builder = builder
def construct(self):
return self.builder.add_part("Part1").add_part("Part2").get_result()
# 使用建造者模式
director = Director(Builder())
product = director.construct()
```
在这个例子中,`Product` 类代表最终的产品,`Builder` 类提供了创建这个产品的接口,`Director` 类指导如何构建这个产品。通过建造者模式,构建过程被封装在了`Builder`类和`Director`类中,使得客户端代码不需要关心产品的具体构建细节。
### 2.1.3 工厂方法模式
工厂方法模式定义了一个创建对象的接口,但让子类决定实例化哪一个类。工厂方法把实例化操作推迟到子类中进行。
```python
class Product:
pass
class ConcreteProduct(Product):
pass
class Creator:
def factory_method(self):
pass
def some_operation(self):
product = self.factory_method()
return product
class ConcreteCreator(Creator):
def factory_method(self):
return ConcreteProduct()
# 客户端代码
creator = ConcreteCreator()
product = creator.some_operation()
```
在这个例子中,`Creator` 类声明了一个工厂方法`factory_method`,它返回一个`Product`类型的对象。`ConcreteCreator` 类覆盖了工厂方法,返回了一个`ConcreteProduct`的实例。客户端代码可以使用`Creator`类,但实际创建的产品是`ConcreteProduct`。
## 2.2 结构型模式
结构型模式关注于如何组合类和对象以获得更大的结构。在Python中,这些模式有助于创建灵活且易于维护的代码结构。
### 2.2.1 适配器模式
适配器模式允许将一个类的接口转换成客户期望的另一个接口,使得原本接口不兼容的类可以一起工作。
```python
class Adaptee:
def specific_request(self):
return "Adaptee method"
class Target:
def request(self):
return "Target method"
class Adapter(Target):
def __init__(self, adaptee):
self.adaptee = adaptee
def request(self):
return self.adaptee.specific_request()
# 使用适配器
adaptee = Adaptee()
adapter = Adapter(adaptee)
print(adapter.request()) # 输出 "Adaptee method"
```
在这个适配器模式的例子中,`Adaptee` 类有一个不符合`Target`接口的方法,通过`Adapter`类适配,我们可以在不修改`Adaptee`类的情况下,让其满足`Target`接口的要求。
### 2.2.2 装饰器模式
装饰器模式允许向一个现有的对象添加新的功能,同时又不改变其结构。
```python
from functools import wraps
def decorator(func):
@wraps(func)
def wrapper(*args, **kwargs):
print("Before the function runs")
result = func(*args, **kwargs)
print("After the function runs")
return result
return wrapper
@decorator
def function_to_decorate(x):
print(f"Inside function_to_decorate with x={x}")
function_to_decorate(10)
```
在上面的代码中,我们定义了一个`decorator`函数,它返回了一个包装器函数`wrapper`。当`function_to_decorate`被调用时,装饰器确保在执行被装饰的函数前后输出了特定的文本。装饰器模式在Python中被广泛应用,特别是通过装饰器语法糖`@`,它能够优雅地增强函数的功能。
### 2.2.3 代理模式
代理模式为其他对象提供一种代理以控制对这个对象的访问。
```python
class RealSubject:
def request(self):
return "RealSubject: Handling Request"
class ProxySubject:
def __init__(self, real_subject=None):
self._real_subject = real_subject or RealSubject()
def request(self):
print("ProxySubject: Processing request before passing it to the RealSubject")
return self._real_subject.request()
# 使用代理模式
subject = ProxySubject()
print(subject.request())
```
在这个例子中,`ProxySubject`类代表一个`RealSubject`对象的代理,它可以添加额外的操作,比如在处理请求前后添加日志、权限检查或其他逻辑。只有当代理决定时,请求才会被转发到实际的`RealSubject`对象。
## 2.3 行为型模式
行为型模式关注对象之间的通信方式。在Python中,这些模式有助于设计出更松耦合和更灵活的系统。
### 2.3.1 策略模式
策略模式定义一系列算法,封装每个算法,并使它们可以互换。策略模式让算法的变化独立于使用算法的客户。
```python
class Context:
def __init__(self, strategy):
self._strategy = strategy
def context_interface(self):
return self._strategy.algorithm_interface()
class Strategy:
def algorithm_interface(self):
pass
class ConcreteStrategyA(Strategy):
def algorithm_interface(self):
return "ConcreteStrategyA"
class ConcreteStrategyB(Strategy):
def algorithm_interface(self):
return "ConcreteStrategyB"
# 客户端代码
context = Context(ConcreteStrategyA())
print(context.context_interface())
context._strategy = ConcreteStrategyB()
print(context.context_interface())
```
在这个例子中,`Context`类持有一个`Strategy`对象。客户端代码可以指定任何的策略子类对象,`Context`将使用这些策略子类来处理其请求。
### 2.3.2 观察者模式
观察者模式定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。
```python
class Subject:
def __init__(self):
self._observers = []
def register_observer(self, observer):
self._observers.append(observer)
def remove_observer(self, observer):
self._observers.remove(observer)
def notify_observers(self):
for observer in self._observers:
observer.update(self)
class Observer:
def update(self, subject):
pass
class ConcreteObserver(Observer):
def update(self, subject):
print(f"ConcreteObserver has been notified. Subject state: {subject}")
# 客户端代码
subject = Subject()
observer = ConcreteObserver()
subject.register_observer(observer)
subject.notify_observers()
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Python 数据结构递归专栏!本专栏旨在深入探讨 Python 递归的方方面面,从基础原理到高级优化技巧。
通过一系列深入的文章,您将了解:
* 递归算法的优化秘籍,告别卡顿,提升效率
* 递归算法的深度解析,原理与性能实战对比
* 递归与迭代的性能对决,专家指导如何选择
* 递归函数的优化与实例解析,精通递归之道
* 递归到动态规划的转换,从艺术到科学
* 无限递归的防范,一文通透
* 内存管理技巧,让递归效率倍增
* 尾递归优化,让代码更优雅
* 复杂数据结构构建秘技,递归编程指南
* 递归限制突破与优化策略,解决边界问题
* 树遍历实战,递归在树形结构中的应用
* 递归与回溯,解题秘籍与案例深入分析
* 文件系统编程,递归的智慧运用
* 并行递归计算,多线程与递归的高效结合
* 递归调试技巧,快速定位与修复错误
* 递归算法面试通关,实战解题技巧大公开
* 大数据处理,递归专家解决方案
* 模块化编程,设计模式与实践指南
* 递归与数学,理论与应用
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Groovy实战秘籍】:动态脚本技术在企业级应用中的10大案例分析
# 摘要
Groovy作为一种敏捷的Java平台语言,其灵活的语法和强大的编程范式受到企业级应用开发者的青睐。本文首先概述了Groovy语言的特性及其在企业级应用中的前景,随后详细探讨了其基础语法、编程范式和测试调试方法。接着,本文深入分析了动态脚本技术在企业级应用中的实际应用场景、性能优化及安
构建SAP金税接口的终极步骤

# 摘要
本文旨在深入理解SAP金税接口的需求与背景,并详细探讨其理论基础、设计与开发过程、实际案例分析以及未来展望。首先介绍了SAP系统的组成、架构及数据流和业务流程,同时概述了税务系统的金税系统功能特点及其与SAP系统集成的必要性。接着,深入分析了接口技术的分类、网络协议的应用,接口需求分析、设计方案、实现、测试、系统集成与部署的步骤和细节。文章还包括了多个成功的案例分享、集成时
直播流量提升秘籍:飞瓜数据实战指南及案例研究

# 摘要
直播流量作为当前数字营销的关键指标,对品牌及个人影响力的提升起到至关重要的作用。本文深入探讨直播流量的重要性及其影响因素,并详细介绍了飞瓜数据平台的功能与优势。通过分析飞瓜数据在直播内容分析、策略优化以及转化率提高等方面的实践应用,本文揭示了如何利用该平台提高直播效果。同时,通过对成功与失败案例的对比研究,提出了有效的实战技巧和经验启示。最后,本文展望了未来直播流量优化的新兴技术应用趋势,并强调了策略的持续优化
网络延迟分析:揭秘分布式系统延迟问题,专家级缓解策略
# 摘要
网络延迟是分布式系统性能的关键指标,直接影响用户体验和系统响应速度。本文从网络延迟的基础解析开始,深入探讨了分布式系统中的延迟理论,包括其成因分析、延迟模型的建立与分析。随后,本文介绍了延迟测量工具与方法,并通过实践案例展示了如何收集和分析数据以评估延迟。进一步地,文章探讨了分布式系统延迟优化的理论基础和技术手段,同时提供了优化策略的案例研究。最后,
【ROS机械臂视觉系统集成】:图像处理与目标抓取技术的深入实现

# 摘要
本文详细介绍了ROS机械臂视觉系统集成的各个方面。首先概述了ROS机械臂视觉系统集成的关键概念和应用基础,接着深入探讨了视觉系统的基础理论与工具,并分析了如何在ROS环境中实现图像处理。随后,文章转向机械臂控制系统的集成,并通过实践案例展现了ROS与机械臂的实际集成过程。在视觉系统与机械臂的协同工作方面,本文讨论了实时图像处理技术、目标定位以及动作
软件测试效率提升攻略:掌握五点法的关键步骤

# 摘要
软件测试效率的提升对确保软件质量与快速迭代至关重要。本文首先强调了提高测试效率的重要性,并分析了影响测试效率的关键因素。随后,详细介绍了五点法测试框架的理论基础,包括其原则、历史背景、理论支撑、测试流程及其与敏捷测试的关联。在实践应用部分,本文探讨了通过快速搭建测试环境、有效管理测试用例和复用,以及缺陷管理和团队协作,来提升测试效率。进一步地,文章深入讨论了自动化测试在五点法中的应用,包括工具选择、脚本编写和维护,以及集成和持续集成的方
【VBScript脚本精通秘籍】:20年技术大佬带你从入门到精通,掌握VBScript脚本编写技巧
# 摘要
VBScript是微软公司开发的一种轻量级的脚本语言,广泛应用于Windows环境下的自动化任务和网页开发。本文首先对VBScript的基础知识进行了系统性的入门介绍,包括语言语法、数据类型、变量、操作符以及控制结构。随后,深入探讨了VBScript的高级特性,如过程、函数、面向对象编程以及与ActiveX组件的集成。为了将理
高速数据传输:利用XILINX FPGA实现PCIE数据传输的优化策略

# 摘要
本文详细探讨了高速数据传输与PCIe技术在XILINX FPGA硬件平台上的应用。首先介绍了PCIe的基础知识和FPGA硬件平台与PCIe接口的设计与配置。随后,针对基于FPGA的PCIe数据传输实现进行了深入分析,包括链路初始化、数据缓冲、流控策略以及软件驱动开发。为提升数据传输性能,本文
【MAC用户须知】:MySQL数据备份与恢复的黄金法则

# 摘要
MySQL作为广泛使用的开源关系型数据库管理系统,其数据备份与恢复技术对于保障数据安全和业务连续性至关重要。本文从基础概念出发,详细讨论了MySQL数据备份的策略、方法、最佳实
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )