【精确度与召回率】:PyTorch中的性能指标优化实战
发布时间: 2024-12-11 12:10:07 阅读量: 10 订阅数: 12 

通讯原理第二次上机,软件中缺少的建模文件

# 1. 精确度与召回率的基本概念
在机器学习和数据挖掘领域,精确度(Precision)和召回率(Recall)是两个核心的概念,它们共同构成了分类问题中模型评估的基本框架。精确度是指在所有预测为正例的样本中,真正正例所占的比例;召回率则是指在所有真实正例的样本中,被正确预测为正例的比例。理解这两个指标的定义和它们之间的权衡关系是优化机器学习模型性能的关键步骤。
## 定义和计算方法
精确度的计算公式为:
```
精确度 = 真正例 / (真正例 + 假正例)
```
召回率的计算公式为:
```
召回率 = 真正例 / (真正例 + 假反例)
```
在这里,真正例(True Positive, TP)指的是被正确预测为正的样本数量,假正例(False Positive, FP)是指被错误预测为正的负样本数量,假反例(False Negative, FN)则是指被错误预测为负的正样本数量。
## 精确度与召回率的权衡
精确度和召回率之间存在一种天然的平衡关系。一般来说,提高精确度可能会降低召回率,反之亦然。在实际应用中,我们需要根据具体问题和业务需求来平衡这两个指标。例如,在医疗诊断中,我们可能更倾向于高召回率以减少漏诊的可能性,而在垃圾邮件过滤中,则可能更加关注精确度以避免将正常邮件错误分类。
在下一章中,我们将深入探讨如何在PyTorch框架下评估模型的性能,并详细阐述如何构建性能评估框架,包括计算精确度和召回率的具体方法。
# 2. 在PyTorch中评估模型性能
精确度和召回率是衡量分类模型性能的重要指标,了解如何在PyTorch中实现这些评估指标是构建有效模型的关键步骤之一。
## 2.1 理解精确度和召回率
精确度和召回率是两个基本概念,它们从不同的角度评估分类模型的性能。
### 2.1.1 定义和计算方法
精确度(Precision)是在预测为正的样本中,实际也为正的样本所占的比例。其数学定义为:
\[ \text{精确度} = \frac{\text{真正例}}{\text{真正例} + \text{假正例}} = \frac{TP}{TP + FP} \]
召回率(Recall),也被称为真正例率(True Positive Rate, TPR),是在实际为正的样本中,被正确预测为正的样本所占的比例。其数学定义为:
\[ \text{召回率} = \frac{\text{真正例}}{\text{真正例} + \text{假负例}} = \frac{TP}{TP + FN} \]
在这些定义中,TP(True Positive)表示真正例的数量,FP(False Positive)表示假正例的数量,而FN(False Negative)表示假负例的数量。
### 2.1.2 精确度与召回率的权衡
在实际应用中,精确度和召回率往往需要做出权衡。一个模型可能在预测时偏向于增加精确度,这通常意味着牺牲一些召回率;反之亦然。例如,在垃圾邮件过滤问题中,我们可能会更关注模型的精确度,以减少将正常邮件误判为垃圾邮件的情况,哪怕这会略微降低召回率。
## 2.2 构建性能评估框架
为了评估模型的性能,我们需要构建一个评估框架,这通常涉及数据的准备、混淆矩阵的计算、以及多分类问题的性能度量。
### 2.2.1 使用PyTorch构建评估脚本
在PyTorch中,我们可以利用内置函数快速构建评估脚本。评估过程中,我们首先将模型设置为评估模式:
```python
model.eval()
with torch.no_grad():
# 在这里进行模型评估
```
接下来,使用正确的评估指标对模型进行评价。以精确度为例,可以使用以下代码:
```python
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Precision of the network on the test images: %d %%' % (
100 * correct / total))
```
### 2.2.2 混淆矩阵及其应用
混淆矩阵是一个非常有用的工具,用于可视化模型的性能。在二分类问题中,它是一个2x2的矩阵,如下所示:
| 预测 \ 实际 | 正类 | 负类 |
|-------------|------|------|
| 正类 | TP | FP |
| 负类 | FN | TN |
在PyTorch中,我们可以使用以下代码来构建混淆矩阵:
```python
from sklearn.metrics import confusion_matrix
import numpy as np
# 使用模型输出和实际标签来计算混淆矩阵
conf_matrix = confusion_matrix(labels, predicted)
```
通过分析混淆矩阵,我们可以得到精确度和召回率,还可以计算其他相关指标,如F1分数。
### 2.2.3 多分类问题的性能度量
对于多分类问题,混淆矩阵会扩展为`n x n`的矩阵,其中`n`是类别数。在这种情况下,评估指标需要考虑所有类别。在PyTorch中,可以使用`torchmetrics`这样的库来简化多分类问题的性能度量。
## 2.3 性能指标的可视化
为了直观地理解模型性能,我们通常会将性能指标可视化,如ROC曲线和精确度-召回率曲线。
### 2.3.1 绘制ROC曲线和AUC值
接收者操作特征曲线(ROC)是一个经典的可视化工具,它通过不同阈值来展示模型的真正例率(TPR)和假正例率(FPR)。在PyTorch中,可以使用以下代码绘制ROC曲线和计算AUC(Area Under Curve)值:
```python
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc
fpr, tpr, thresholds = roc_curve(labels, outputs)
roc_auc = auc(fpr, tpr)
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.show()
```
### 2.3.2 精确度-召回率曲线的绘制
精确度-召回率曲线是另一重要的可视化工具,它展示了在不同阈值下的精确度和召回率。为了绘制这条曲线,我们需要计算出在不同阈值下的精确度和召回率:
```python
precision = dict()
recall = dict()
thresholds = dict()
n_classes = outputs.shape[1]
for i in range(n_classes):
precision[i], recall[i], thresholds[i] = precision_recall_curve(labels[:, i], outputs[:, i])
plt.plot(recall[i], precision[i], lw=2, label='class {}'.format(i))
plt.xlabel("Recall")
plt.ylabel("Precision")
plt.legend(loc="best")
plt.title("Precision-Recall Curve")
plt.show()
```
通过以上步骤,我们可以深入理解模型在不同类别上的性能,并根据这些信息调整模型参数以达到更好的分类效果。
# 3. 精确度与召回率的优化策略
在机器学习中,模型的性能评估是一个重要的环节。而精确度与召回率是评价分类模型性能的两个关键指标。本章将详细介绍如何优化这两个指标。
## 3.1 数据层面的优化
### 3.1.1 数据增强技术
数据增强是一种提高模型鲁棒性和泛化能力的方法,通过增加训练集的多样性,可以防止模型过拟合,并提高模型在真实世界数据上的表现。
#### 常见的数据增强技术包括:
- **图像旋转、缩放和裁剪**
- **颜色变换,如亮度、对比度调整**
- **添加噪声**
- **使用GAN生成的合成数据**
代码块示例:
```python
from torchvision import transforms
# 定义一个数据增强的管道
data_transforms = transforms.Compose([
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.RandomRotation(10), # 随机旋转10度
transforms.ColorJitter(brightness=0.5, contrast=0.5) # 调整亮度
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了使用PyTorch进行模型评估的具体方法和关键指标。它提供了对精确度、召回率和F1分数等7大性能指标的全面解析,并指导读者如何利用混淆矩阵来提升模型性能。专栏还介绍了PyTorch评估指标的实际应用,帮助读者掌握深度学习模型评估的最佳实践。通过了解这些指标和方法,读者可以有效评估和优化其PyTorch模型,从而提升其性能和可靠性。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
PSS_E高级应用:专家揭秘模型构建与仿真流程优化
参考资源链接:[PSS/E程序操作手册(中文)](https://wenku.csdn.net/doc/6401acfbcce7214c316eddb5?spm=1055.2635.3001.10343)
# 1. PSS_E模型构建的理论基础
在探讨PSS_E模型构建的理论基础之前,首先需要理解其在电力系统仿真中的核心作用。PSS_E模型不仅是一个分析工具,它还是一种将理论与实践相结合、指导电力系统设计与优化的方法论。构建PSS_E模型的理论基础涉及多领域的知识,包括控制理论、电力系统工程、电磁学以及计算机科学。
## 1.1 PSS_E模型的定义和作用
PSS_E(Power Sys
【BCH译码算法深度解析】:从原理到实践的3步骤精通之路

参考资源链接:[BCH码编解码原理详解:线性循环码构造与多项式表示](https://wenku.csdn.net/doc/832aeg621s?spm=1055.2635.3001.10343)
# 1. BCH译码算法的基础理论
## 1.1
DisplayPort 1.4线缆和适配器选择秘籍:专家建议与最佳实践
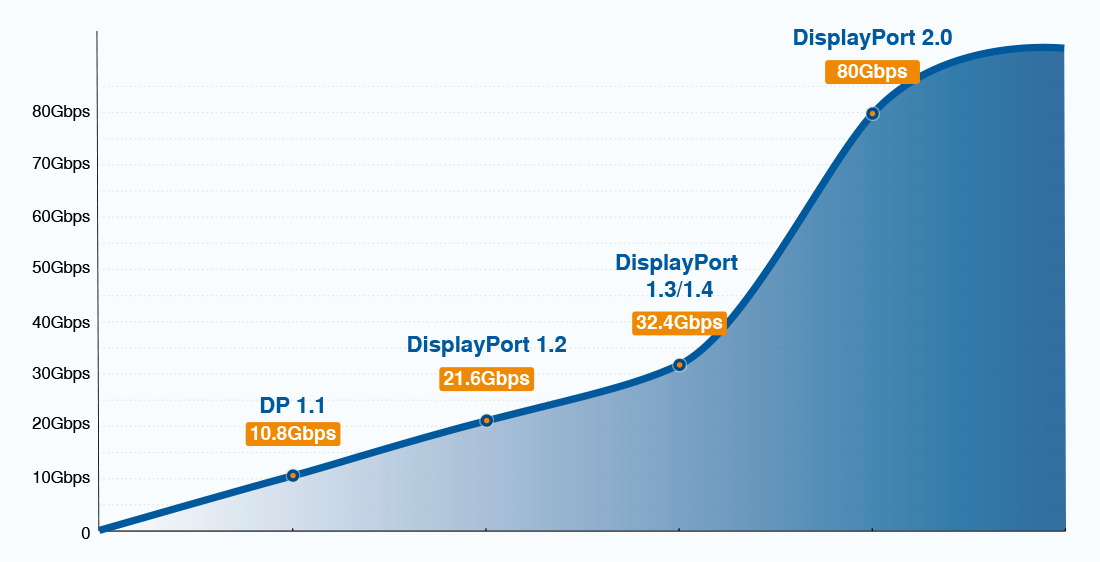
参考资源链接:[display_port_1.4_spec.pdf](https://wenku.csdn.net/doc/6412b76bbe7fbd1778d4a3a1?spm=1055.2635.3001.10343)
# 1. DisplayPort 1.4技术概述
随着显示技术的不断进步,DisplayPort 1.4作为一项重要的接
全志F133+JD9365液晶屏驱动配置入门指南:新手必读
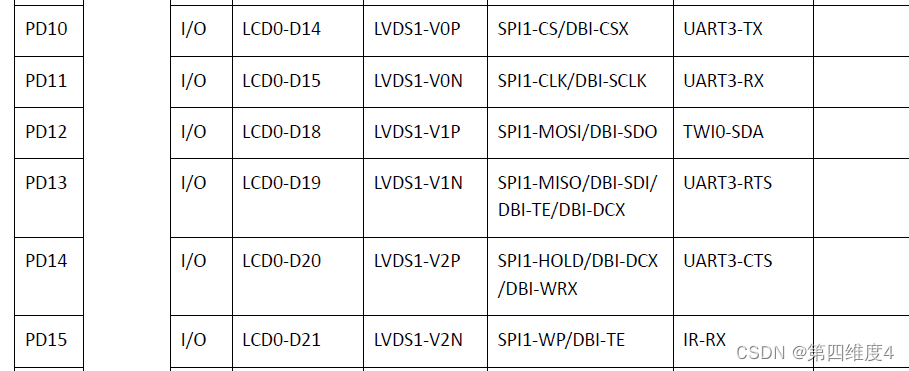
参考资源链接:[全志F133+JD9365液晶屏驱动配置操作流程](https://wenku.csdn.net/doc/1fev68987w?spm=1055.2635.3001.10343)
# 1. 全志F133与JD9365液晶屏驱动概览
液晶屏作为现代显示设备的重要组成部分,其驱动程序的开发与优化直接影响到设备的显示效果和用户交互体验。全志F133处理器与JD9365液晶屏的组合,是工
【C语言输入输出高效实践】:提升用户体验的技巧大公开
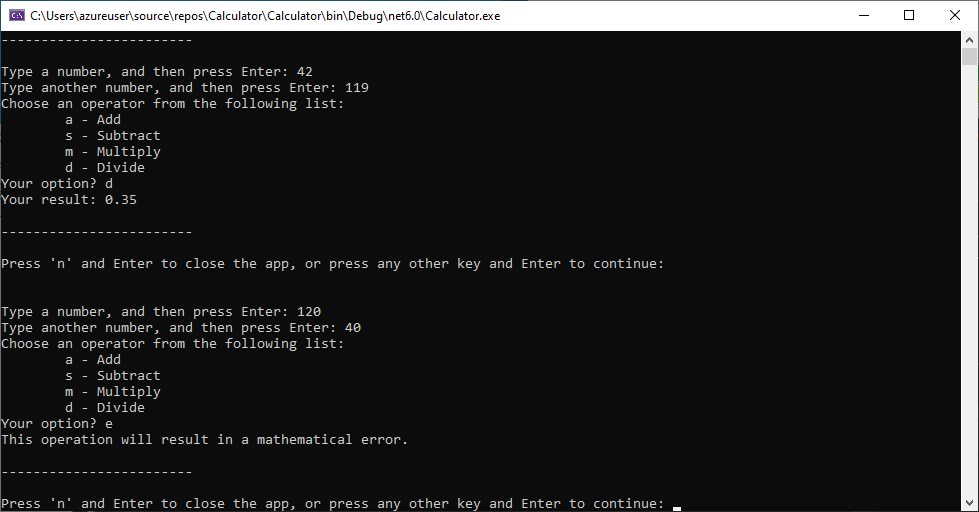
参考资源链接:[编写一个支持基本运算的简单计算器C程序](https://wenku.csdn.net/doc/4d7dvec7kx?spm=1055.2635.3001.10343)
# 1. C语言输入输出基础与原理
## 1.1 C语言输入输出概述
PowerBuilder性能优化全攻略:6.0_6.5版本性能飙升秘籍

参考资源链接:[PowerBuilder6.0/6.5基础教程:入门到精通](https://wenku.csdn.net/doc/6401abbfcce7214c316e959e?spm=1055.2635.3001.10343)
# 1. PowerBuilder基础与性能挑战
## 简介
PowerBuilder,一个由Sybase公司开发的应用程序开发工具,以其快速应用开发(RAD)的特性,成为了许多开发者的首选。然而
【体系结构与编程协同】:系统软件与硬件协同工作第六版指南
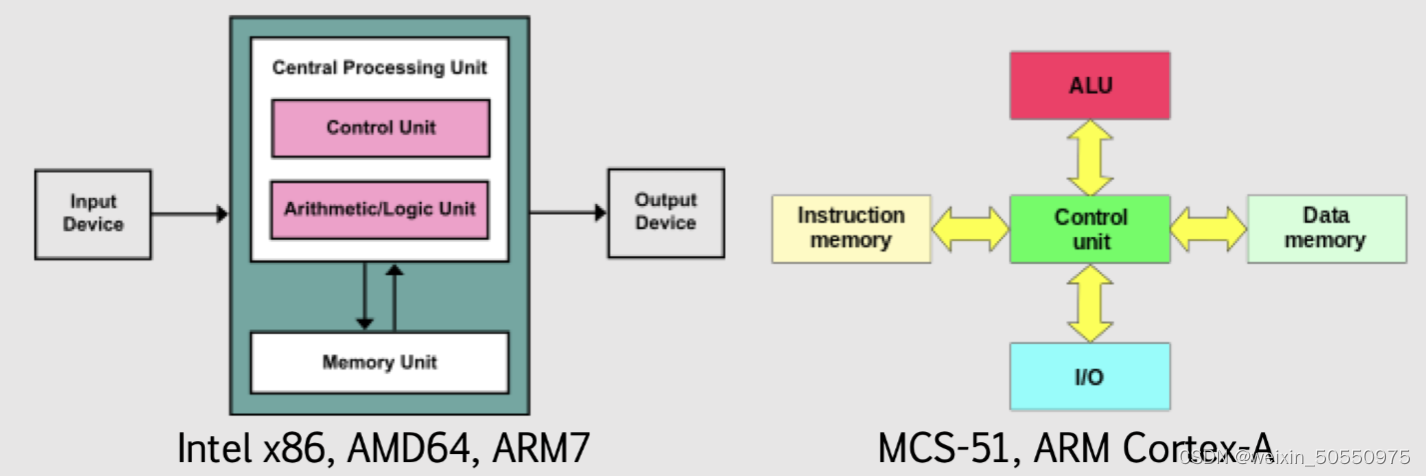
参考资源链接:[量化分析:计算机体系结构第六版课后习题解答](https://wenku.csdn.net/doc/644b82f6fcc5391368e5ef6b?spm=1055.2635.3001.10343)
# 1. 系统软件与硬件协同的基本概念
## 1.1 系统软件与硬件协同的重要性
在现代计算机系统中,系统软件与硬件的协同工作是提高计算机性能和效率的关键。系统软件包括操作系统、驱动
【故障排查大师】:FatFS错误代码全解析与解决指南

参考资源链接:[FatFS文件系统模块详解及函数用法](https://wenku.csdn.net/doc/79f2wogvkj?spm=1055.263
从零开始:构建ANSYS Fluent UDF环境的最佳实践
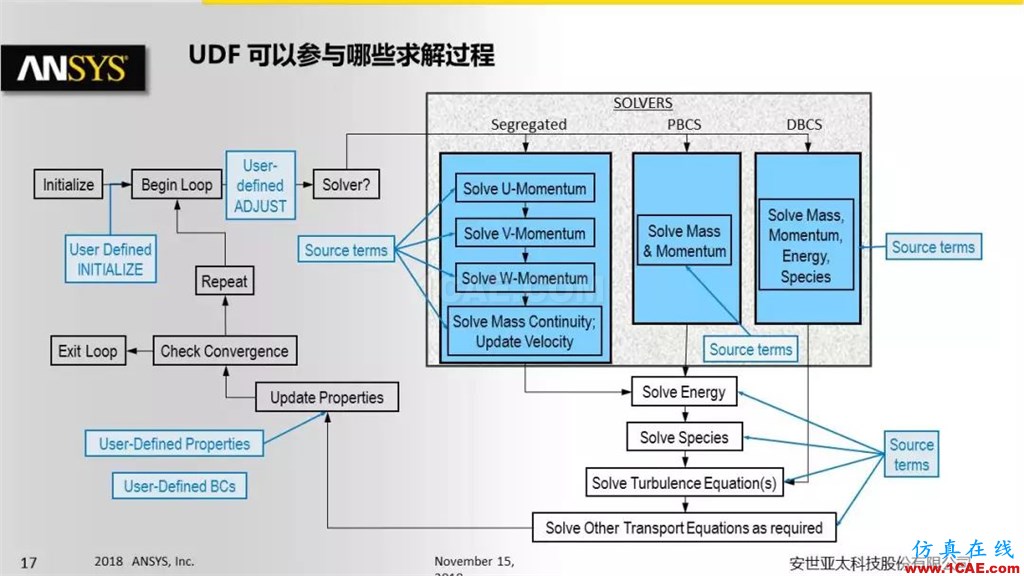
参考资源链接:[2020 ANSYS Fluent UDF定制手册(R2版)](https://wenku.csdn.net/doc/50fpnuzvks?spm=1055.2635.3001.10343)
# 1. ANSYS Fluent UDF基础知识概述
## 1.1 UDF的定义与用途
ANSYS Fluent UDF(User-Defined Functions)是一种允许用户通
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )